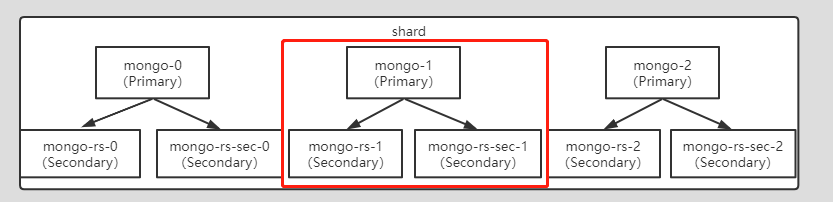
We run 3 shards of each 3 “mongod” servers each:
MongoDB version: 4.2.10
Docker version: 19.03.8, build afacb8b7f0
OS: Ubuntu 18.04.4
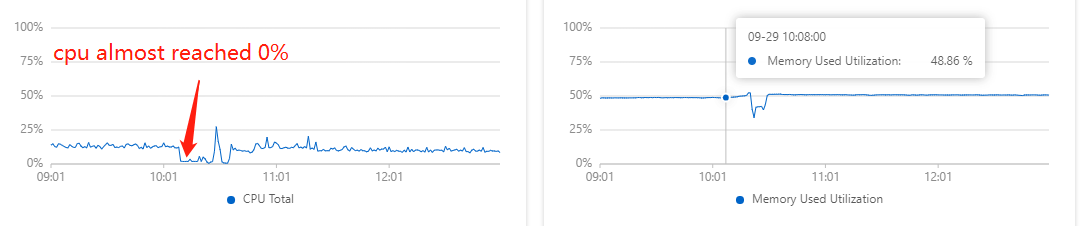
Everything worked well but some days ago, a failure occurred: witout any sign , mongo-1(primay) could’t return connections to clients . The logs of mongos and Secondary printed lots of “NetworkInterfaceExceededTimeLimit” exception.
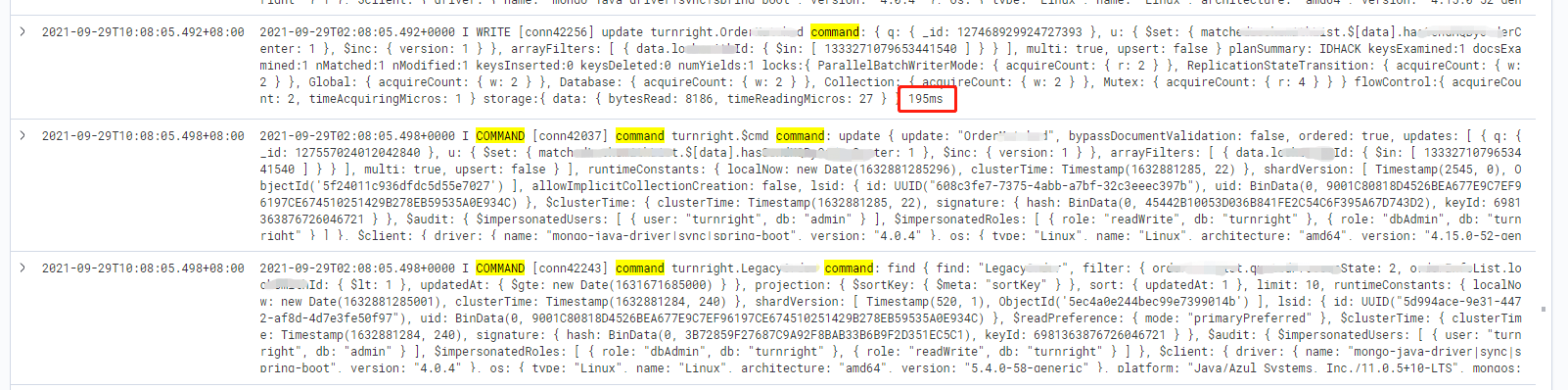
The logs of mongo-1(primary), during the problem, it only printed logs about connection:
2021-09-29T10:08:55.921+08:00 2021-09-29T02:08:55.921+0000 I NETWORK [listener] connection accepted from ip:57192 #42365 (178 connections now open)
2021-09-29T10:08:55.968+08:00 2021-09-29T02:08:55.968+0000 I NETWORK [listener] connection accepted from ip:36974 #42366 (179 connections now open)
2021-09-29T10:08:55.968+08:00 2021-09-29T02:08:55.968+0000 I ACCESS [conn42359] Successfully authenticated as principal __system on local from client ip:36962
2021-09-29T10:08:55.969+08:00 2021-09-29T02:08:55.968+0000 I NETWORK [listener] connection accepted from ip:36976 #42367 (180 connections now open)
2021-09-29T10:08:55.969+08:00 2021-09-29T02:08:55.969+0000 I NETWORK [conn42366] received client metadata from ip:36974 conn42366: { driver: { name: “NetworkInterfaceTL”, version: “4.2.10” }, os: { type: “Linux”, name: “Ubuntu”, architecture: “x86_64”, version: “18.04” } }
2021-09-29T10:21:05.976+08:00 2021-09-29T02:21:05.976+0000 I NETWORK [listener] connection accepted from ip:41604 #59742 (16272 connections now open)
2021-09-29T10:21:05.976+08:00 2021-09-29T02:21:05.976+0000 I NETWORK [listener] connection accepted from ip:41602 #59741 (16271 connections now open)
2021-09-29T10:21:05.976+08:00 2021-09-29T02:21:05.976+0000 I NETWORK [conn59741] received client metadata from ip:41602 conn59741: { driver: { name: “NetworkInterfaceTL”, version: “4.2.10” }, os: { type: “Linux”, name: “Ubuntu”, architecture: “x86_64”, version: “18.04” } }
It kept receiving connections form clients but could’t handle them.
I tried to connect to mongod with MongoDB shell by ‘docker exec -it mongodb-shard mongo --port 27018’ but it doesn’t work, could’t connect to it.
Logs of mongo-rs-1 and mongo-rs-sec-1 (secondary) :
2021-09-29T10:09:05.217+08:00 2021-09-29T02:09:05.217+0000 I REPL [replication-1505] Restarting oplog query due to error: NetworkInterfaceExceededTimeLimit: error in fetcher batch callback :: caused by :: Request 30396207 timed out, deadline was 2021-09-29T02:09:05.207+0000, op was RemoteCommand 30396207 – target:[mongo-1:27018] db:local expDate:2021-09-29T02:09:05.207+0000 cmd:{ getMore: 6531183952488528211, collection: “oplog.rs”, batchSize: 13981010, maxTimeMS: 5000, term: 81, lastKnownCommittedOpTime: { ts: Timestamp(1632881335, 6), t: 81 } }. Last fetched optime: { ts: Timestamp(1632881335, 6), t: 81 }. Restarts remaining: 1
2021-09-29T10:09:07.818+08:00 2021-09-29T02:09:07.818+0000 I REPL [replication-1505] Error returned from oplog query (no more query restarts left): MaxTimeMSExpired: error in fetcher batch callback :: caused by :: operation exceeded time limit
2021-09-29T10:09:07.820+08:00 2021-09-29T02:09:07.820+0000 W REPL [rsBackgroundSync] Fetcher stopped querying remote oplog with error: MaxTimeMSExpired: error in fetcher batch callback :: caused by :: operation exceeded time limit
2021-09-29T10:09:10.317+08:00 2021-09-29T02:09:10.317+0000 I REPL [SyncSourceFeedback] SyncSourceFeedback error sending update to mongo-1:27018: InvalidSyncSource: Sync source was cleared. Was mongo-1:27018
2021-09-29T10:09:37.822+08:00 2021-09-29T02:09:37.822+0000 I REPL [replication-1504] Blacklisting mongo-1:27018 due to error: ‘NetworkInterfaceExceededTimeLimit: Request 30396224 timed out, deadline was 2021-09-29T02:09:37.822+0000, op was RemoteCommand 30396224 – target:[mongo-1:27018] db:local expDate:2021-09-29T02:09:37.822+0000 cmd:{ find: “oplog.rs”, limit: 1, sort: { $natural: 1 }, projection: { ts: 1, t: 1 } }’ for 10s until: 2021-09-29T02:09:47.822+0000
Logs of mongos:
2021-09-29T10:09:28.351+08:00 2021-09-29T02:09:28.350+0000 I COMMAND [conn63809] command tr.Client command: find { find: “Client”, filter: { applicationId: 5836984, clientId: “139226756”, clientType: “LegacyQualifiedWorker” }, limit: 2, $db: “tr”, $clusterTime: { clusterTime: Timestamp(1632881348, 2), signature: { hash: BinData(0, EE561BD26B273CFB69233B17D400D94C165D433B), keyId: 6981363876726046721 } }, lsid: { id: UUID(“100a0796-a4f2-40d7-b70c-6d2aeb9766be”) }, $readPreference: { mode: “primaryPreferred” } } numYields:0 ok:0 errMsg:“Encountered non-retryable errorduring query :: caused by :: Couldn’t get a connection within the time limit” errName:NetworkInterfaceExceededTimeLimit errCode:202 reslen:342 protocol:op_msg 20067ms
It showed a lot of NetworkInterfaceExceededTimeLimit error.
I connected to mongo-rs-1 and rs.status() showed that all members of replicaSet were online, one PRIMARY and two SECONDARYs.
I restarted mongo-1 and it recovered for a while , then it went wrong again. About 20 minutes later I restarted mongo-1 again and it revovered completely this time, everything worked well, no more error.
Was it a network problem or something else? I have no idea what happened in mongo-1. Could anyone gives some advice?
 !
! . I’m glad it’s back in shape now.
. I’m glad it’s back in shape now.