Day 21 of 100daysofcode challenge: Classification and Regression
Classification and regression are both types of supervised learning (ML). They differ in the type of problem they are trying to solve and their output.
Classification models take a discrete or categorical input to produce a discrete or categorical output. The goal is to predict a class label or category. For example: Categorizing whether an email is spam or not spam or categoring whether a pet is a dog or a .
Regression models take a continous input to produce a continous output. The goal is to predict a numerical value or range. For example future stock prices or future temperatures .
It is a mathematical notation used to find the efficiency or time complexity of an algorithm. Meaning we ask as the input grows how drastically does the time requirement grows with it.
The orders of growth from best to worst goes as follows:
O(1) Constant [meaning that any variable input does not effect this function]
O(logn) Logarithmic
O(n) Linear
O(nlogn) Linearithmic
O(n^2) Quadratic
O(n^3) Cubic
O(2^n) Exponential
O(n!) Factorial
Keep in mind that we are checking the time complexity of an algorithm’s worst case scenario. For instance in linear search our target could be at the start of an array/list thus an O notation of O(1) , but since the worst case scenario is that our target is at the end of the array/list thus the actual O notation is O(n) where n is the length of the array/list.
Day 23 of 100daysofcode challenge: Uninformed search algorithms
Uninformed search algorithms uses no problem-specific knowledge to search for it’s target node in a search tree/graph. Examples of uninformed search algorithms are Depth-first search (DFS) and Breadth-first search (BFS)
What is the difference between DFS and BFS?
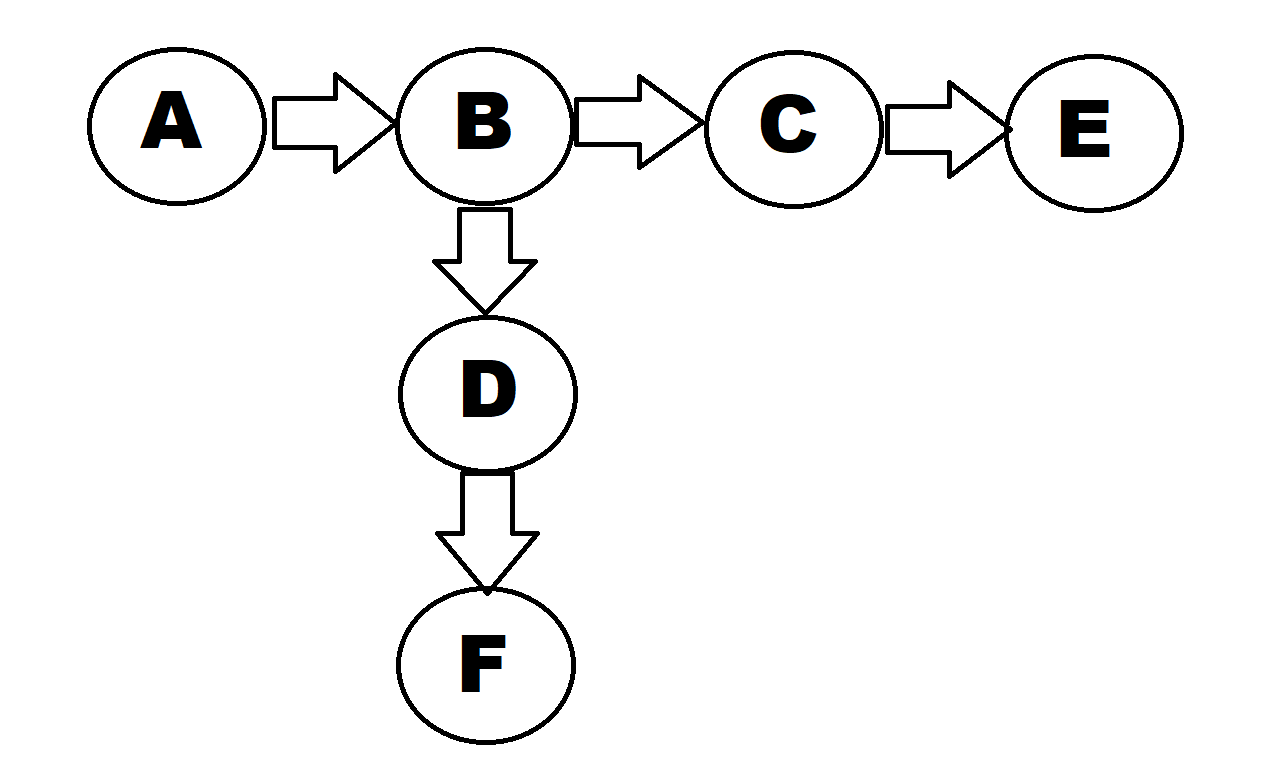
Depth-first search is a search algorithm that always explores the deepest node in a tree/graph. For example if you look at the diagram below, a DFS algorithm would first start at A then go to B, Then C and next E (explore the entirety of that path). Only after it reaches a dead end will it jump to a new path at D and explore D and next F.
Breadth-first search is also a search algorithm but it explores the shallowest node first. Using the diagram below again as an example, BFS will start with A, then B, then C and D (it will explore both paths and not commit to one path ), then it wil explore E and F.
Day 24 of 100daysofcode challenge: Youtube to MP3 Converter
As part of my internship @TECHlarious and @Two Of US L.L.C, I was assigned to do a project that made use of APIs.
My project is the Youtube to MP3 Converter which as the name suggest turns a youtube video into a downloadable MP3. The API used comes from Rapid API, a website full of useful and helpful APIs.
This project does not accept blank inputs and the user must input the video ID of the video they want to convert.
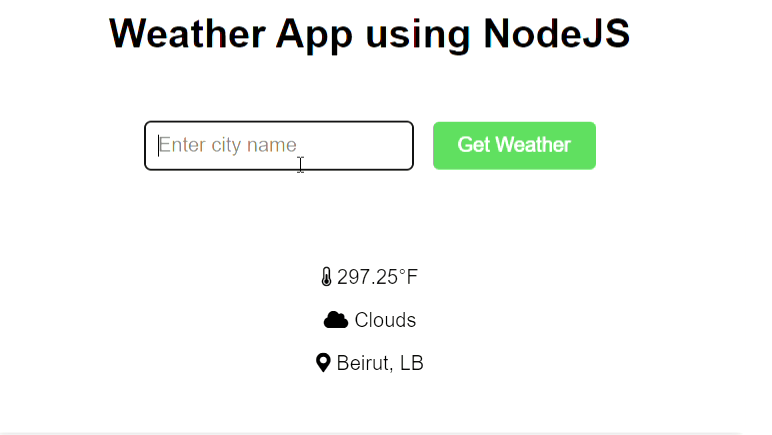
To practice using Node.js and APIs, I created a weather app. This application uses Openweather’s API. It shows the temperature,cloudyness and country of any city the user types in.
EJS is short for embedded JavaScript.
EJS is a templating engine that lets you create reusable HTML templates with JavaScript code embedded within them. It’s a popular choice for building dynamic web applications, especially with Node.js.
You can embed JavaScript code within your templates using <% %>, which gets executed when the template is rendered.
EJS also supports variables, which can be passed from your application to the
template
Mongoose is a JavaScript library that allows you to interact with MongoDB, a NoSQL database, in a more intuitive and object-oriented way. It provides a schema-based solution for modeling and manipulating data in MongoDB.
Mongoose allows you to define schemas for your MongoDB collections, which enables validation, casting, and default values for your data.
You can create models from your schemas, which are then used to interact with your MongoDB collections.
Mongoose provides an interface for performing Create, Read, Update, and Delete (CRUD) operations on your data.
Nodemon is a utility that automatically restarts your Node.js application when it detects changes in your code. It’s a development-only dependency that simplifies the development process by eliminating the need to manually restart your application every time you make changes.
How does Nodemon work?
You install Nodemon as a development dependency in your project.
You run your Node.js application using Nodemon instead of Node.js (e.g., nodemon app.js instead of node app.js).
Nodemon watches for changes in your code and dependencies.
When Nodemon detects changes, it automatically restarts your application.
Day 29 of 100daysofcode challenge: POST and GET methods
In HTTP (Hypertext Transfer Protocol), GET and POST are two of the most common request methods used to interact with web servers. Here is how they work:
GET Method: The GET method is used to retrieve data from a server. When you enter a URL in your browser, it sends a GET request to the server, asking for the resource located at that URL. The request includes the URL and headers, but no body content. The server responds with the requested resource, and the data is displayed in your browser.
POST Method:The POST method is used to send data to a server for processing.When you submit a form or upload a file, your browser sends a POST request to the server, including the data in the request body.The request includes the URL, headers, and body content (the data being sent).The server processes the data and responds with a result, which might be a new resource, an error message, or a redirect.
Day 31 of 100daysofcode challenge: Curse of dimensionality
Curse of dimensionality is a phenomen that occurs with high-dimensional data and is a challenge in machine learning and data analysis.
What does high-dimensional data mean?
It is data that has multiple features. For example, if a dataset has 10 features, the data space is 10-dimensional. The more features a dataset has the more dimensional it becomes and the more complex it becomes as well.
Day 32 of 100daysofcode challenge: Recommender systems types
There are multiple types of recommender systems. The most known are Collaborative filtering (CF) and Content-Based Filtering (CBF)
CF: recommends items based on the behaviour or preferences of similar users. It identifies patterns in user behaviour and recommends items that other user with similar tastes have liked.
Example: A music streaming platform recommends songs to a user based on the listening habitsbof other users with similar musical tastes.
CBF: recommends items with similar attributes or features to the ones a user has liked or interacted with in the past.
Example: A movie streaming platform recommends movies with similar genres,directors, or actors to the ones a user has watched before.
Day 33 of 100daysofcode Challenge: HTTP response status codes
HTTP response status codes are 3 digit codes returned by a web server in response to a client’s request. They indicate the outcome of the request and the response.
There are 5 classes of HTTP response status codes:
Day 34 of 100daysofcode challenge: Overfitting and underfitting
In machine learning (ML), the goal is to train a model that can accurately make predictions on new, unseen data. However, during the training process, it’s possible to encounter two common problems: overfitting and underfitting.
Overfitting: Overfitting occurs when a model is too complex and learns the noise and random fluctuations in the training data, rather than the underlying patterns. As a result, the model performs extremely well on the training data but poorly on new, unseen data. [ The model memorized the answers and thus doesn’t understand how to solve future problems or data]
Underfitting: Underfitting occurs when a model is too simple and fails to capture the underlying patterns in the training data. As a result, the model performs poorly on both the training data and new, unseen data.
Ideally we want the model to be optimally complex. Complex enough to learn the patterns of the training data , but be able to predicate accurately for future data points as well.
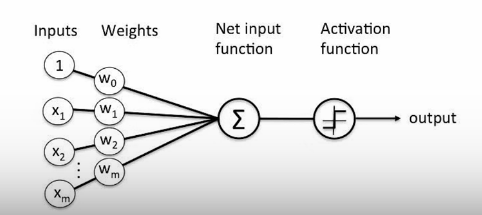
It is the building block of a neural network. The simplest type of artificial neural network. Used for binary classification [classify inputs into one of two classes]
Components of a Perceptron:
Inputs: The perceptron receives one or more input values.
Weights: Each input has a corresponding weight
Bias: a bias term added when calculating the weighted sum
The weighted sum is the multiplication of each input value with a corresponding weight, and then adding the bias term.
Activation Function: Weighted sum is passed through an activation function which determines the output.
This output is then compared to a threshold value . If the output is greater or equal to the threshold, the perceptron outputs 1 (or “true”) otherwise it outputs a 0 (or “false”)
A neural network is a machine learning model inspired by the structure and function of the human brain. It’s a network of interconnected artificial neurons (nodes) that process and transmit information.
Key Components:
Artificial Neurons (Nodes): Each node receives one or more inputs, performs a computation, and sends the output to other nodes.
Connections (Edges):Nodes are connected through edges, which represent the flow of information between nodes.
Weights and Biases:Each edge has a weight and bias associated with it, which determine the strength and direction of the connection.
Activation Functions:Nodes apply an activation function to the output of the weighted sum to introduce non-linearity and enable the network to learn complex patterns.
How do Neural Networks Work?
Input Layer: The network receives input data, which is propagated through the network.
Hidden Layers:The input data is processed through one or more hidden layers, where complex patterns and representations are learned.
Output Layer:The output of the hidden layers is propagated to the output layer, which produces the final prediction or classification.
Backpropagation:The error between the predicted output and actual output is computed and propagated backwards through the network to update the weights and biases.
Types of Neural Networks:
Feedforward Networks:Information flows only in one direction, from input layer to output layer, without any feedback loops.
Recurrent Neural Networks (RNNs):Information can flow in a loop, allowing the network to keep track of state and make decisions based on sequential data.
Convolutional Neural Networks (CNNs):Designed for image and signal processing, CNNs use convolutional and pooling layers to extract features.
CRUD is an acronym that stands for Create, Read, Update, and Delete. It’s a fundamental concept in software development, particularly in the context of database management and web applications.
The CRUD Operations:
Create (C): This operation involves adding new data or records to a database or system. Read (R): This operation retrieves existing data or records from a database or system. Update (U):This operation modifies or changes existing data or records in a database or system. Delete (D): This operation removes or deletes existing data or records from a database or system.
Day 38 of 100daysofcode challenge: Activation Functions
What is an Activation Function?
Activation functions determines the output of a node or neuron in a neural network. They also introduce non-linearity into a model [learn and represent more complex relationships between inputs and outputs] .
Types of Activation Functions:
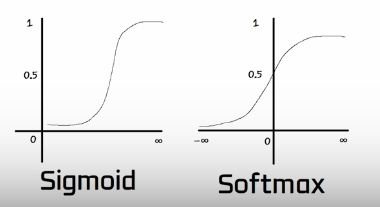
Sigmoid: Maps the input to a value of between 0 and 1. Often used at output layer when the task is a binary classification problem.
ReLU: Outputs 0 for negative inputs and the input value for positive inputs. Easy to compute, but can result in dead neurons during training.
There is a variation of the ReLU called the leaky ReLU that is just like the ReLU , but allows a small fraction of inputs to pass. This is done to avoid dead neurons.
Tanh (Hyperbolic tangent): Similar to sigmoid, but maps input to a value between -1 and 1. [It is less used than sigmoid or ReLU] .
Softmax: Used for multiclass classification problems. The output is a probability distribution over multiple classes. Unlike the sigmoid where the output is one of two classes [binary classification] . Used in the Output layer.
Day 39 of 100daysofcode challenge: Feedforward Propagation and Backpropagation
Feedforward Propagation: The process of flowing input data through a neural network to produce an output. It’s a forward pass through the network, where the input data is propagated through each layer , and the output of each layer is used as the input to the next layer.
Goal: Generate an output to the next layer.
Backpropagation: An optimization algorithm used to train neural networks by minimizing the error between the predicted output and the actual output. It’s a backward pass through the network, where the error is propagated from the output layer back to the input layer adjusting the weights and biases of the connection between neurons to minimize the error.
Goal: Update the model’s parameter to improve it’s performance.
Day 40 of 100daysofcode challenge: Neural Network Architectures
What are Neural Network Architectures?
Neural network architectures refer to the organization and structure of artificial neural networks, including the arrangement of layers, connections, and nodes. The architecture of a neural network determines how it processes input data, learns from it, and makes predictions or decisions.
Common neural network architectures:
Feedforward Networks:Also known as multilayer perceptrons (MLPs), these networks consist of multiple layers of nodes, where each layer processes the input data and passes the output to the next layer.
Convolutional Neural Networks (CNNs): Designed for image and signal processing, CNNs use convolutional and pooling layers to extract features and reduce spatial dimensions.
Recurrent Neural Networks (RNNs): Suitable for sequential data, RNNs have feedback connections, allowing them to capture temporal relationships and model sequential dependencies.
Long Short-Term Memory (LSTM) Networks: A type of RNN, LSTMs are designed to handle long-term dependencies in sequential data, using memory cells to store information.
Autoencoders:Neural networks that learn to compress and reconstruct input data, often used for dimensionality reduction, anomaly detection, and generative modeling.
Generative Adversarial Networks (GANs):Consisting of a generator and discriminator, GANs learn to generate new data samples that resemble the training data.
Residual Networks (ResNets): Designed to ease training and improve performance, ResNets use residual connections to bypass layers and introduce skip connections.
Transformers:Introduced in attention-based models, transformers are designed for sequential data and use self-attention mechanisms to model relationships between input elements