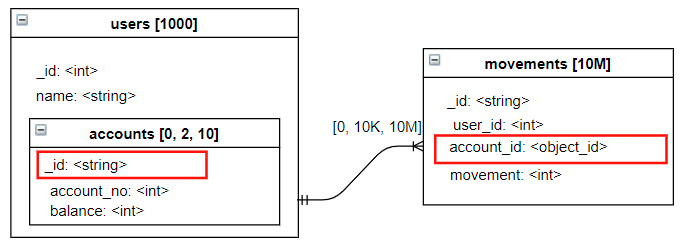
Sometimes, Mongo modeling recommends duplicating data by efficiency and referencing other collections, instead of opting for Embed (when the number of records is very high n to Zillions).
In that case, what would be the best approximation if we change a row of the other collection, which requires modifying the data we have replicated in our collection by efficiency?
The use of transactions according to Mongo is not recommended.
For example. I’m going to put the code as JavaScript objects (so that it is simpler and more short).
Imagine that an account can have thousands of details records, and that in the user’s information (the most consulted) we only want to have a photo of the situation of the user’s accounts, without having to go to each of his accounts.
While you insert value into Account’s collection Movements array you would need to compute user’s Account.Balance by increasing it by value of the Movement.
If Movements array length is a concern (and as you stated it would contain zillions of elements) I would also consider Bucket Pattern. In reality each adjustment would track date and time of the Movement which could be used for bucketing and preferably sharding.
Could you be more especific, please? Imagine that you delete a user and you have to delete all of his movements. Do you need to use transactions or are there a better way to do that? What if you have locally placed your database, not in Mongo Atlas.
To sum up: When you need to separate data in two collections, but they are conected each other, how we should manage them?
Please, answer this questions not only giving name of patterns.
There is no simple rule. The way you approach design depends on many things.
Essentially, when you have data scattered then application needs to delete it from all collections (non-atomic operation if you do not use transaction) but if you really need to do it in a transaction is another matter. Transactions are expensive and often with careful design and depending on how system is used you can get away with not using it.
For example operations on a document and everything embedded in it is always atomic operation out of the box so design can benefit from that.
Consider your example of deleting user. Since, as you said, user is most queried entity you could delete user only and defer removing all movement data to scheduled job afterwards which will benefit from fast response and full task accomplished later.
This design is not ideal though because deleting from zillion collection in one go uses a lot of resource, that’s why I was suggesting bucketing and sharting.
A cronjob or trigger based architecture can be utilised to execute script that will consume queued reference to purge records.
The application can use webservice to enqueue user_id to be deleted then script can process that queue for example.