Recently (last 2 days) we’ve had our application go down and become inaccessible for about 15-30 minutes.
It seems like it coincides with the time that a new primary is elected.
Looking back through the history, it seems like the swap over usually happens instantly. I see no significant errors in my application during the swap over.
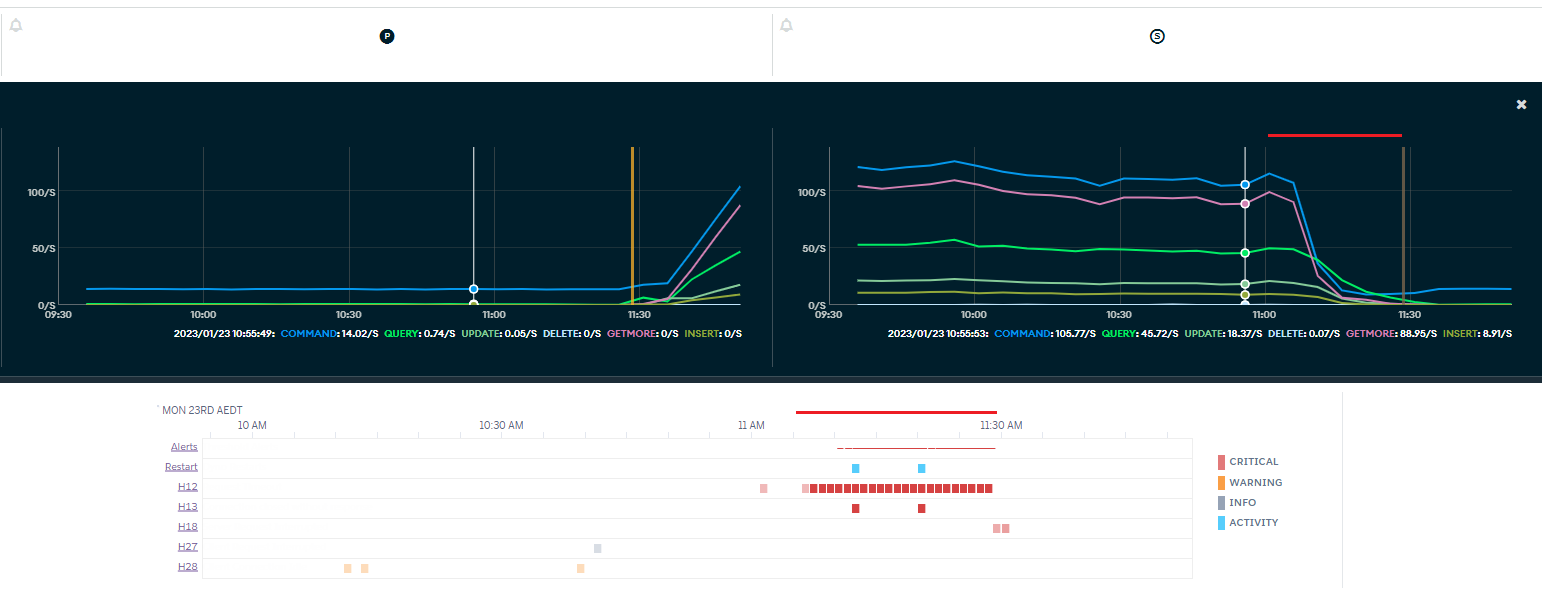
The red line here indicates the start of the errors occurring on my backend. You can see the traffic is slowly being bled from the (old) primary. It takes about 30 minutes until eventually the new primary is elected and things resume normally
For this window of time our application is unable to talk to process requests. All requests timeout for this window of time.
It eventually sorted it self out. I put our application into maintenance mode about 20 minutes into the situation which reduced the number of requests to the backend to zero. It seems like this gave it a chance to swap over properly?
I am just wondering if this is expected, if I could get some insights into this problem. I am not sure how to diagnose the problem. Everything is fine, until its not, and then in about 15-30 minutes a new primary is elected and then everything is fine again. That’s all I’ve been able to figure out.
We have a NestJS application on Heroku, we’re using Mongoose to interact with the database.
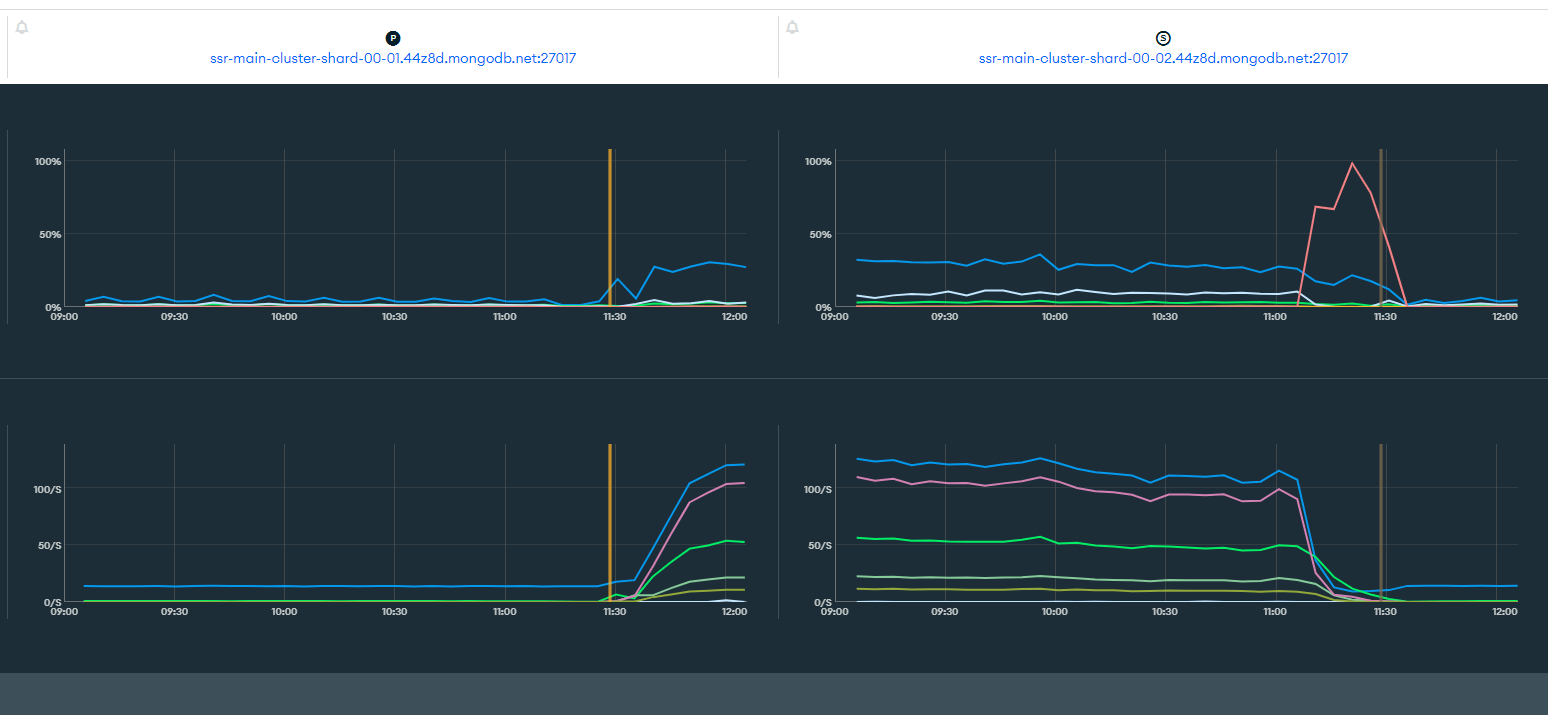
Noticed that the CPU steal is really high around the start of the problem we see. I cant tell if this is a symptom of the problem of the problem itself. Not sure. Help would be appreciated, thanks.
Based off the details on this post (I assume these metrics are Normalized System CPU and Opcounters for two nodes), it seems like the CPU increase correlates with the operation count increase which is probably what we expect here. However, as you have mentioned the issue appears to occur when “CPU steal” occurs (I presume everything is okay prior to this but correct me if i’m wrong here). As per the Fix CPU usage issues documentation (specifically regarding CPU steal):
System: CPU (Steal) % is occurs when the CPU usage exceeds the guaranteed baseline CPU credit accumulation rate by the specified threshold. For more information on CPU credit accumulation, refer to the AWS documentation for Burstable Performance Instances.
Note: The System: CPU (Steal) % is alert is applicable when the EC2 instance credit balance is exhausted. Atlas triggers this alert only for AWS EC2 instances that support Burstable Performance Instances. Currently, these are M10 and M20 cluster types.
Based off the details above, it’s likely that your cluster’s cpu usage is exceeding the guaranteed baseline CPU credit accumulate rate (in which it will need to utilise burstable performance) up until a point all the CPU credit balance is exhausted in which CPU steal starts occuring (assuming the same workload continues).
Of course this is just my assumption based only on the data available on this post. The following CPU steal details may be useful to you too. However, I would recommend you contacting the Atlas in-app chat support as they have more insight into your cluster. It might be that you may need to optimize your workload (where possible) or test a higher tier cluster (M30 for example) to see if the primary swapping issue still occurs.