So, we have an M30 atlas cluster with 3 replicas. We’re trying to benchmark our application by running some performance tests. During the run, we observed an oddity with Atlas cluster. We noticed periodic spikes in System CPU usage across all 3 nodes of the replica set.
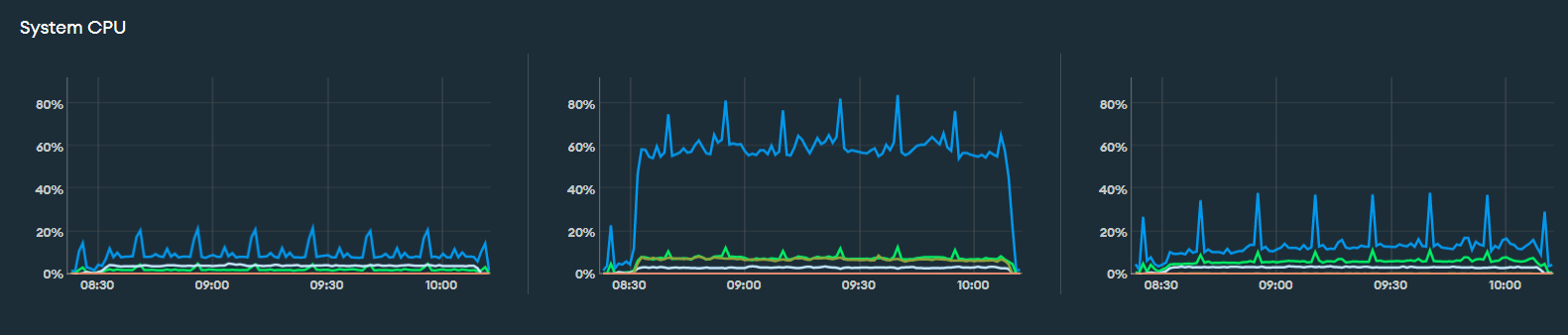
What is causing the spike every 15 mins?