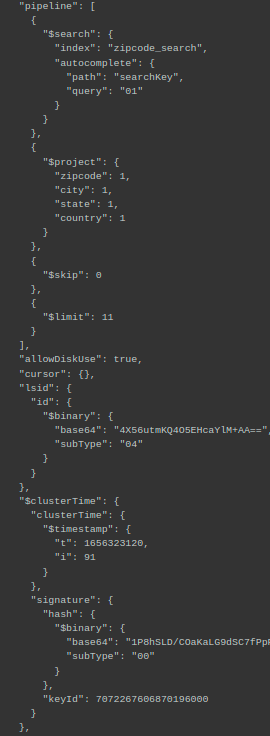
Hi, I am trying the atlas search. Facing some unexpected behavior. Like I want to search zip code, I write this piece. Then I run the script to execute the query 3000 times so that I can check its performance.
But the results are totally opposite to what I thought.
The traditional query works way better than the indexed one. Both of them are giving results.
I don’t know, why this is happening?
Is my index working in the indexed search query or not, How can I confirm? Or am I doing something work here?
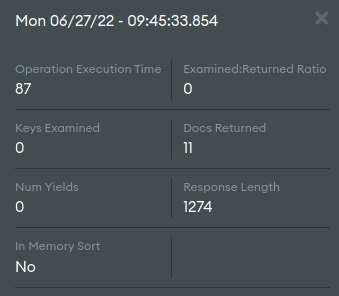
The number of documents examined by the $search query is 0 and the other query examined 299 documents there is a total of 42000 documents in the zipcode collection and there is an index on zip code and city.
The avg execution time of $search query is higher than $match query.
When $search query is running then load on zipcode collection goes up to 100%. But on $match load goes up to 10%.
So problem statement is that I want to use autocomplete to search the zip code and city. So I created a “searchKey” in each document which will be a combination of zip code and city name. For Eg, if the zip code is “1234” and the city is “ABC” then “searchKey” in that document will be “1234 ABC”. So that I can perform the search on the single key. Then I create the search index on it. Index definition is done above.
Hi @varun_garg ,
Thanks for all the info supplied,
When $search query is running then load on zipcode collection goes up to 100%. But on $match load goes up to 10%.
What do you mean by 100% load? CPU? Also I am not sure how you are tracking utilization per collection, perhaps you mean CPU on a particular node in your cluster? Primary node?
The number of documents examined by the $search query is 0
Are you referring to the keys-examined metric reported by mongodb? Its okay for this to be 0 for any $search aggregation stage, this metric refers to native mongodb indexes, not search indexes.
Is my index working in the indexed search query or not, How can I confirm? Or am I doing something work here?
If you are getting results from the $search query, it works, $search won’t run a collection scan like a regular find() query would if an index is not present.
I want to know that when we run the search query on zip code collection the load on the zip code goes up to 100%, Why?
It’s hard to answer this here, if you need further help diagnosing the issue I recommend contacting support
Few thoughts on this issue without seeing further information:
Are the queries returning the same amount of documents? is it the same documents? The logic and criteria of autocomplete and regex is not exactly the same, which query behavior you prefer?
Autocomplete also sorts the results by relevancy, Usually “better” matches are returned first, this is better if you show the results to users, the
I don’t know the size of your documents, but for 42k documents its likely that the entire working set fits in memory in mongodb. This would make $match very fast. Its possible that for larger datasets you would see different performance for both these queries
I can’t tell from the query you shared what type of regex you are running (do you have a .* at the end to match any suffix?)
Why merge city and zipcode into the same field? You can have them as two different autocomplete fields in your search index and use the compound operator to with two autocomplete clauses. (Don’t know if this would impact performance but will remove the need for the extra field)
Is your production workload similar to your script that runs the query 3000 times?
If not then why worry about it?
If it is we have learnt that $search scales pretty well when you add cores, if you are concerned about saturating your CPU you can always upgrade your Atlas cluster (or use a different query).
If you are showing the suggestions to human users I suggest running the query and looking whether the first 10 documents or so are good matches and ordered like you want. If you use autocomplete it might be easier for you to control the order using other search knobs, fuzzy-ness, boosting exact matches to the top over partial matches and so on.