TL;DR what is the best solution for handling very large data sets?
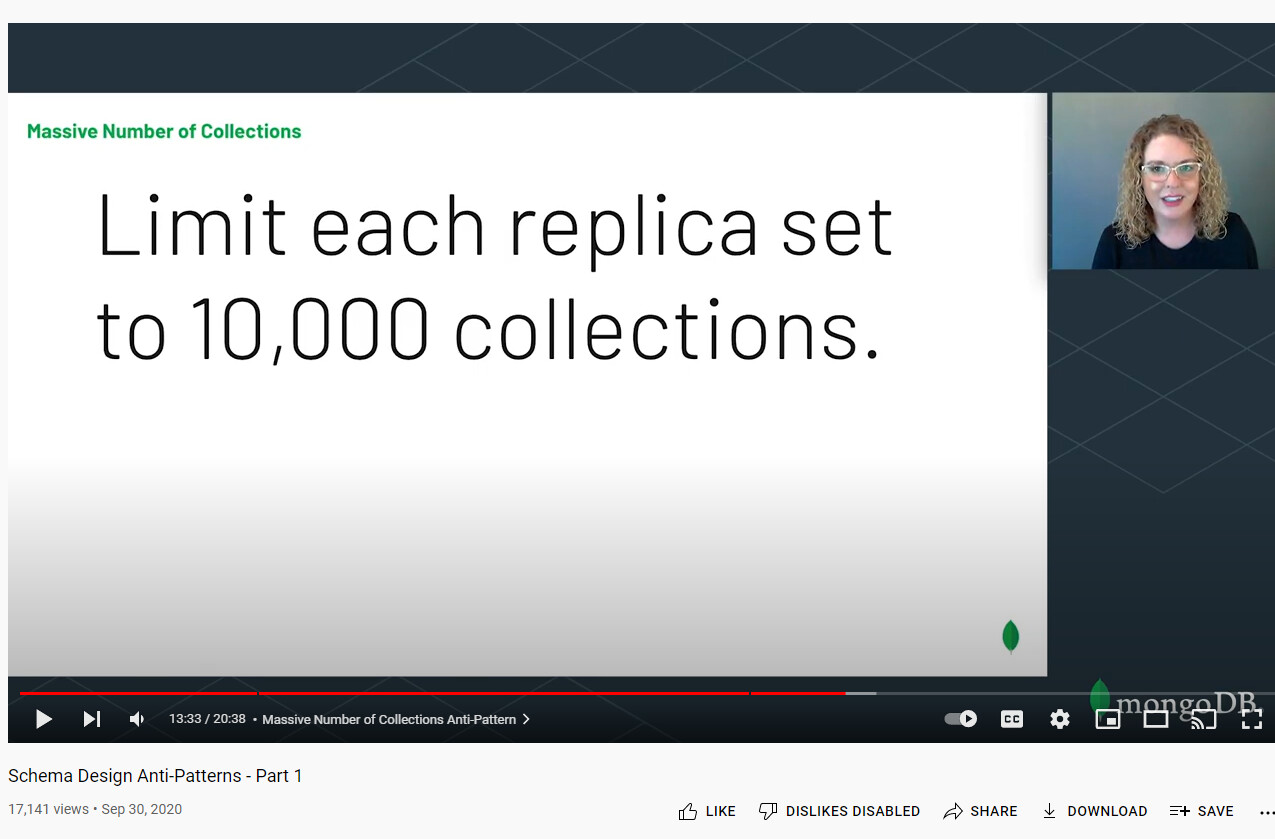
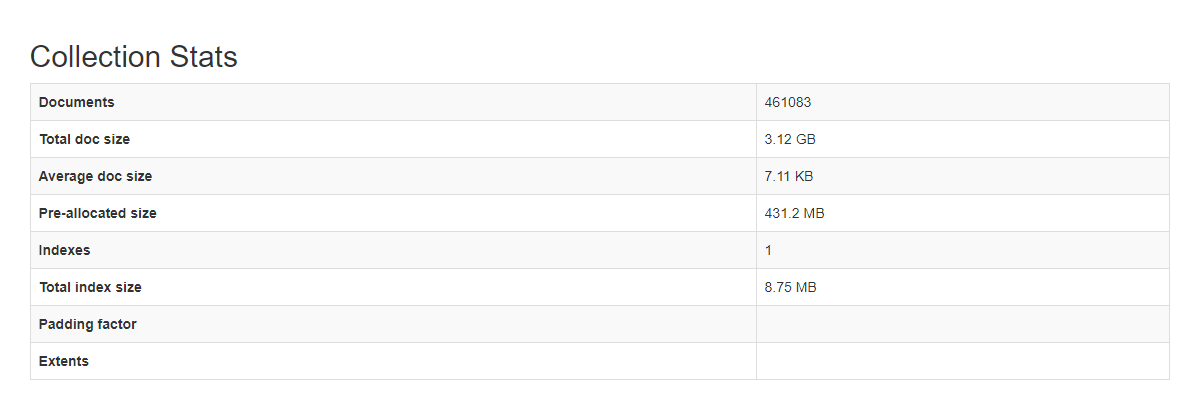
We’re using mongodb for a processing results data set (results are written and queried, never updated)… a single execution goes to a unique collection, below are the collection stats… this processing execution can occur 60-100 times daily and there is some worry about us hitting the 10k+ collection performance problem and suggested we look into sharding the data… but sharding and replication only improves performance and does not look like it would address hitting the 10k… should I instead be looking at storing more data to a single collection (it’s already 400k+ documents so seems like a lot)? or a cold storage solution (move old results out of mongo to external file)? or something else?