Vector search and, more broadly, Artificial Intelligence (AI) are more popular now than ever. These terms are arising everywhere. Technology companies around the globe are scrambling to release vector search and AI features in an effort to be part of this growing trend. As a result, it's unusual to come across a homepage for a data-driven business and not see a reference to vector search or large language models (LLMs). In this blog, we'll cover what these terms mean while examining the events that led to their current trend.
Check out our AI Learning Hub to learn more about building AI-powered apps with MongoDB.
What is vector search
Vectors are encoded representations of unstructured data like text, images, and audio in the form of arrays of numbers.
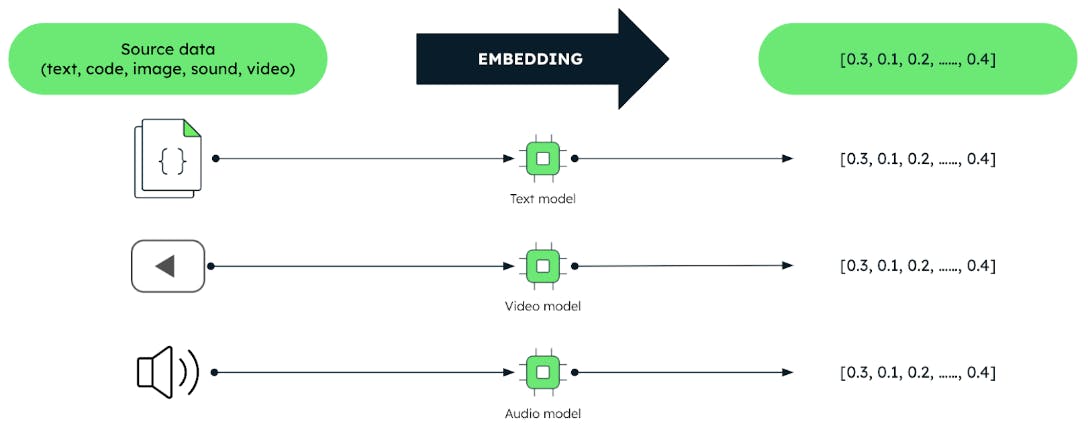
These vectors are produced by machine learning (ML) techniques called "embedding models". These models are trained on large corpuses of data. Embedding models effectively capture meaningful relationships and similarities between data. This enables users to query data based on the meaning rather than the data itself. This fact unlocks more efficient data analysis tasks like recommendation systems, language understanding, and image recognition.
Every search starts with a query and, in vector search, the query is represented by a vector. The job of vector search is finding, from the vectors stored on a database, those that are most similar to the vector of the query. This is the basic premise. It is all about similarity. This is why vector search is often called similarity search. Note: similarity also applies to ranking algorithms that work with non-vector data.
To understand the concept of vector similarity, let’s picture a three-dimensional space. In this space, the location of a data point is fully determined by three coordinates.
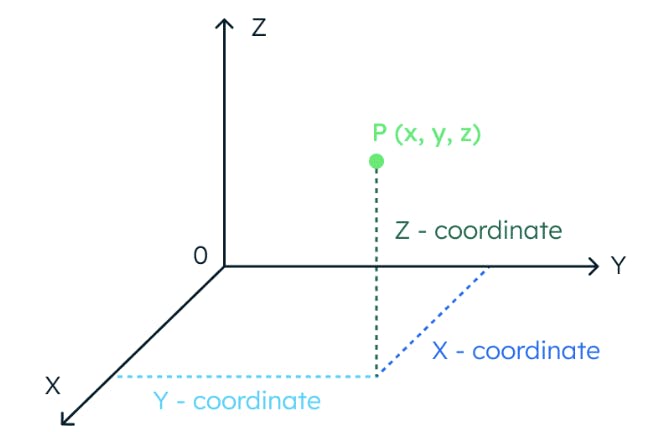
In the same way, if a space has 1024 dimensions, it takes 1024 coordinates to locate a data point.
Vectors also provide the location of data points in multidimensional spaces. In fact, we can treat the values in a vector as an array of coordinates. Once we have the location of the data points — the vectors — their similarity to each other is calculated by measuring the distance between them in the vector space. Points that are closer to each other in the vector space represent concepts that are more similar in meaning.
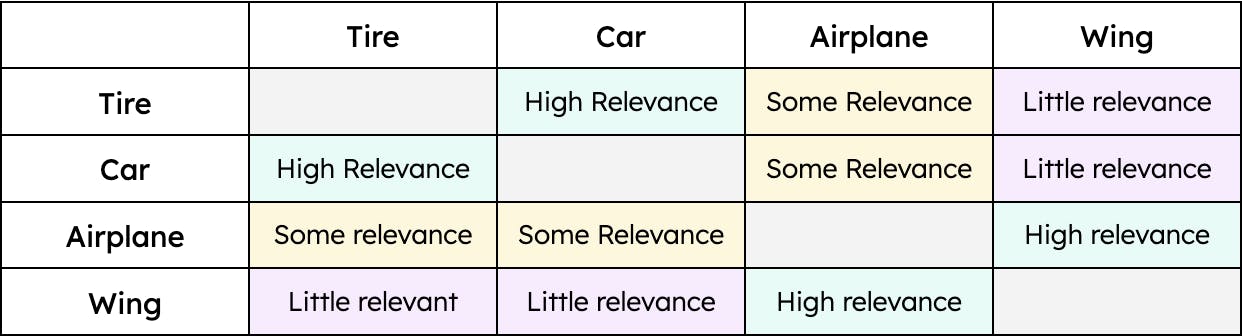
For example, "tire" has a greater similarity to "car" and a lesser one to "airplane." However, "wing" would only have a similarity to "airplane." Therefore, the distance between the vectors for “tire” and “car” would be smaller than the distance between the vectors for “tire” and “airplane.” Yet, the distance between “wing” and “car” would be enormous. In other words, “tire” is relevant when we talk about a “car,” and to a lesser extent, an “airplane.” However, a “wing” is only relevant when we talk about an “airplane” and not relevant at all when we talk about a “car” (at least until flying cars are a viable mode of transport). The contextualization of data — regardless of the type — allows vector search to retrieve the most relevant results to a given query.
A simple example of similarity
What are Large Language Models?
LLMs are what bring AI to the vector search equation. LLMs and human minds both understand and associate concepts in order to perform certain natural language tasks, such as following a conversation or understanding an article. LLMs, like humans, need training in order to understand different concepts. For example, do you know what the term “corium” pertains to? Unless you're a nuclear engineer, probably not. The same happens with LLMs: if they are not trained in a specific domain, they are not able to understand concepts and therefore perform poorly. Let’s look at an example.
LLMs understand pieces of text thanks to their embedding layer. This is where words or sentences are converted into vectors. In order to visualize vectors, we are going to use word clouds. Word clouds are closely related to vectors in the sense that they are representations of concepts and their context. First, let’s see the word cloud that an embedding model would generate for the term “corium” if it was trained with nuclear engineering data:

As shown in the picture above, the word cloud indicates that corium is a radioactive material that has something to do with safety and containment structures. But, corium is a special term that can also be applied to another domain. Let’s see the word cloud resulting from an embedding model that has been trained in biology and anatomy:
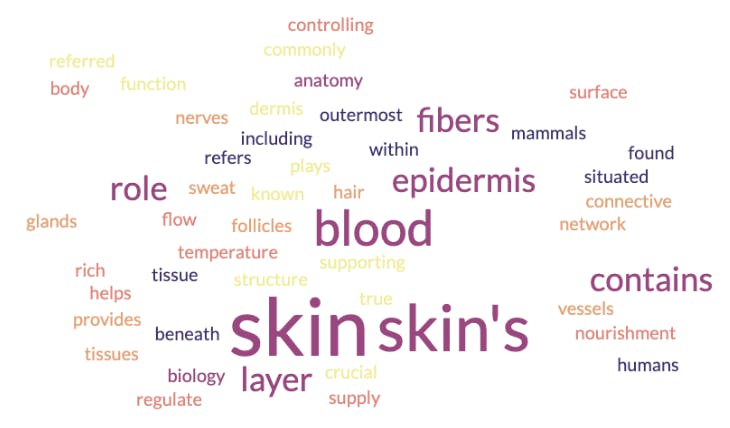
In this case, the word cloud indicates that corium is a concept related to skin and its layers. What happened here? Is one of the embedding models wrong? No. They have both been trained with different data sets. That is why finding the most appropriate model for a specific use case is crucial. One common practice in the industry is to adopt a pre-trained embedding model with strong background knowledge. One takes this model and then fine-tunes it with the domain-specific knowledge needed to perform particular tasks.
The quantity and quality of the data used to train a model is relevant as well. We can agree that a person who has read just one article on aerodynamics will be less informed on the subject than a person who studied physics and aerospace engineering. Similarly, models that are trained with large sets of high-quality data will be better at understanding concepts and generate vectors that more accurately represent them. This creates the foundation for a successful vector search system.
It is worth noting that although LLMs use text embedding models, vector search goes beyond that. It can deal with audio, images, and more. It is important to remember that the embedding models used for these cases share the same approach. They also need to be trained with data — images, sounds, etc. — in order to be able to understand the meaning behind it and create the appropriate similarity vectors.
When was vector search created?
MongoDB Atlas Vector Search currently provides three approaches to calculate vector similarity. These are also referred to as distance metrics, and consist of:
euclidean distance
cosine product
dot product
While each metric is different, for the purpose of this blog, we will focus on the fact that they all measure distance. Atlas Vector Search feeds these distance metrics into an approximate nearest neighbor (ANN) algorithm to find the stored vectors that are most similar to the vector of the query. In order to speed this process up, vectors are indexed using an algorithm called hierarchical navigable small world (HNSW). HNSW guides the search through a network of interconnected data points so that only the most relevant data points are considered.
Using one of the three distance metrics in conjunction with the HNSW and KNN algorithms constitutes the foundation for performing vector search on MongoDB Atlas. But, how old are these technologies? We would think they are recent inventions by a bleeding-edge quantum computing lab, but the truth is far from that.
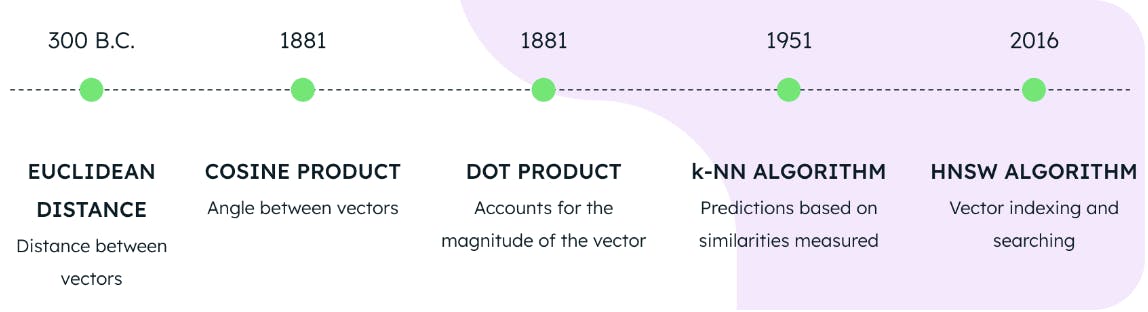
Euclidean distance was formulated in the year 300 BC, the cosine and the dot product in 1881, the KNN algorithm in 1951, and the HNSW algorithm in 2016. What this means is that the foundations for state-of-the-art vector search were fully available back in 2016. So, although vector search is today’s hot topic, it has been possible to implement it for several years.
When were LLMs created?
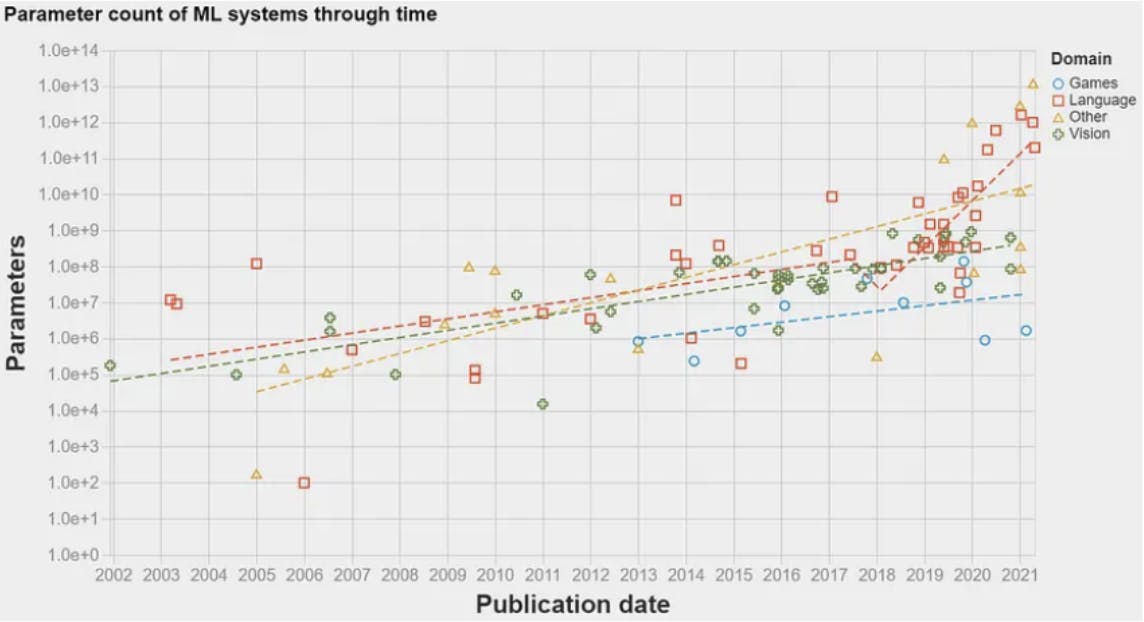
In 2017, there was a breakthrough: the transformer architecture. Presented in the famous paper Attention is all you need, this architecture introduced a neural network model for natural language processing (NLP) tasks. This enabled ML algorithms to process language data on an order of magnitude greater than was previously possible. As a result, the amount of information that could be used to train the models increased exponentially. This paved the way for the first LLM to appear in 2018: GPT-1 by OpenAI. LLMs use embedding models to understand pieces of text and perform certain natural language tasks like question answering or machine translation. LLMs are essentially NLP models that were re-branded due to the large amount of data they are trained with — hence the word large in LLM. The graph below shows the amount of data — parameters — used to train ML models over the years. A dramatic increase can be observed in 2017 after the transformer architecture was published.
Why are vector search and LLMs so popular?
As stated above, the technology for vector search was fully available back in 2016. However, it did not become particularly popular until the end of 2022. Why?
Although the ML industry has been very active since 2018, LLMs were not widely available or easy to use until OpenAI’s release of ChatGPT in November 2022. The fact that OpenAI allowed everyone to interact with an LLM with a simple chat is the key to its success. ChatGPT revolutionized the industry by enabling the average person to interact with NLP algorithms in a way that would have otherwise been reserved for researchers and scientists. As can be seen in the figure below, OpenAI’s breakthrough led to the popularity of LLMs skyrocketing. Concurrently, ChatGPT became a mainstream tool used by the general public. The influence of OpenAI on the popularity of LLMs is also evidenced by the fact that both OpenAI and LLMs had their first popularity peak simultaneously. (See figure 8.)
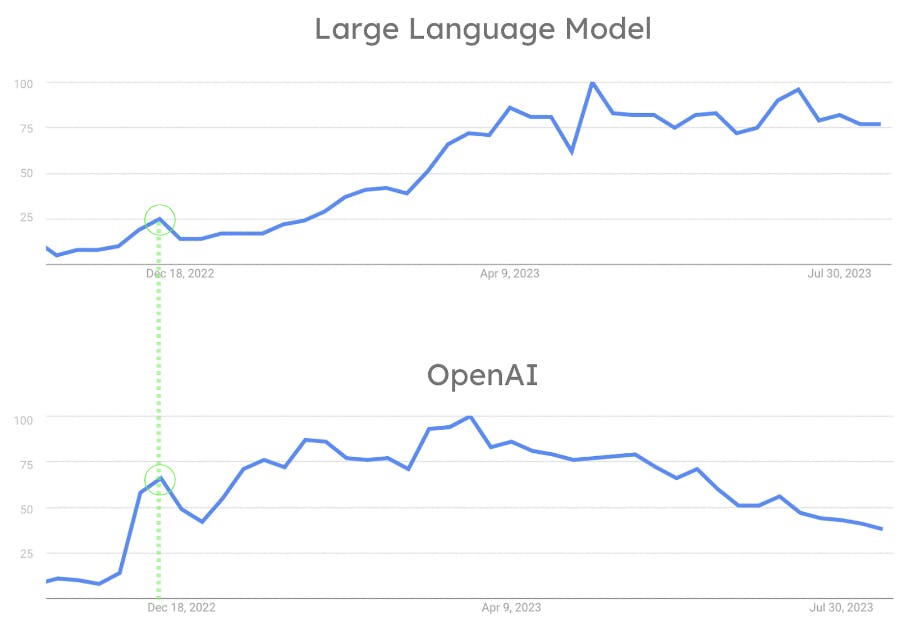
Here is why. LLMs are so popular because OpenAI made them famous with the release of ChatGPT. Searching and storing large amounts of vectors became a challenge. This is because LLMs work with embeddings. Thus the adoption of vector search increased in tandem. This is the largest contributing factor to the industry shift. This shift resulted in many data companies introducing support for vector search and other functionalities related to LLMs and the AI behind them.
Conclusion
Vector search is a modern disruptor. The increasing value of both vector embeddings and advanced mathematical search processes has catalyzed vector search adoption to transform the field of information retrieval. Vector generation and vector search might be independent processes, but when they work together their potential is limitless.
To learn more visit our Atlas Vector Search product page. To get started using Vector Search, head over to our quick-start guide.