Apache Kafka is an open-source stream-processing software platform developed by LinkedIn and donated to the Apache Software Foundation in 2011. One of Kafka’s core capabilities is its ability to ingest massive amounts of data in a distributed architecture. This makes it easy to scale out and address big data use cases like IoT, data pipelines, and other real-time data systems.
In Apache Kafka, integration with data sources like MongoDB is done through the Kafka Connect service. This service uses connectors that know how to interact with the desired data source. The MongoDB Connector for Apache Kafka provides both source and sink capabilities with an Apache Kafka cluster.
Microsoft Azure includes an event messaging service called Azure Event Hubs. This service provides a Kafka endpoint that can be used by existing Kafka based applications as an alternative to running your own Kafka cluster. Azure Event Hubs exposes the same Kafka Connect API enabling the use of the MongoDB connector with the Event Hubs service.
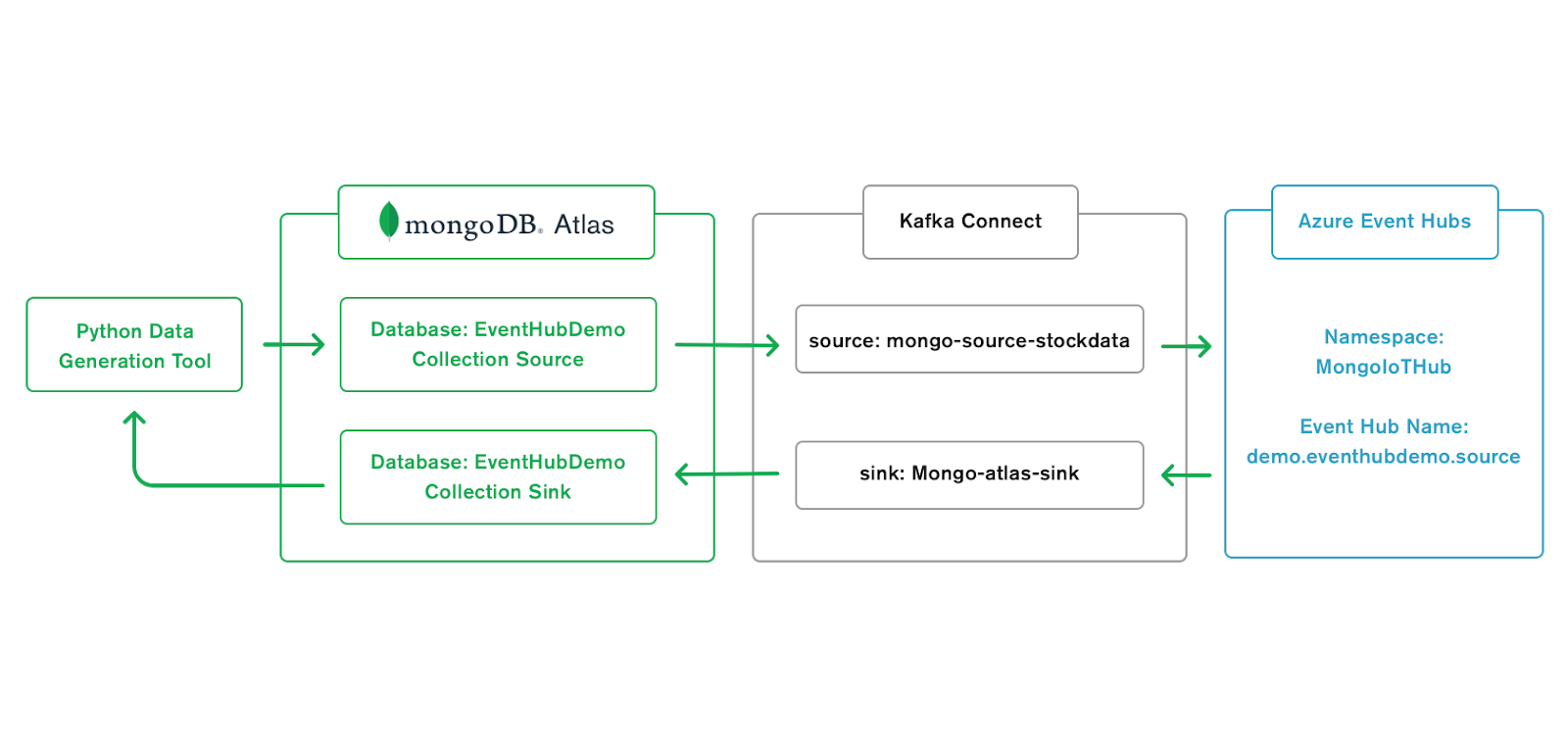
In this blog, we will demonstrate how to set up the MongoDB Connector for Apache Kafka and use it within the Azure Event Hub environment. In the end, we will write data to a MongoDB collection, the source connector will see the change and push the data into an Azure Event hub. From there the sink connector will notice the new arrival of data in the event hub and push this data into another MongoDB collection. A python application will insert data into the source collection and also be reading data from the sink collection. The net effect will be a round trip of data sent through Azure Event Hubs using the MongoDB Connector for Apache Kafka.
Prerequisites
If you would like to follow the demo you will need the following:
Azure Subscription - You will need access to an Azure subscription. If you do not have one you can sign up on the Microsoft Azure website.
Docker - If you don’t have Docker installed or are new to Docker check out the Docker website. Docker is not related to Apache Kafka, it just makes spinning up infrastructure especially demos really quick and easy. If you don’t know it, taking the time is well worth the investment.
MongoDB Atlas cluster - In this demo, we will be using a MongoDB Cluster as a source and sink to the Azure Event Hub. MongoDB Atlas spins up a cluster in minutes right in Azure. If you do not have access to a MongoDB Atlas cluster, you can create your free cluster. Note when using MongoDB Atlas there is no network access or user accounts defined by default. To create a user account, click, “Add New Database User” from the Database Access menu in your new cluster.
Network connectivity
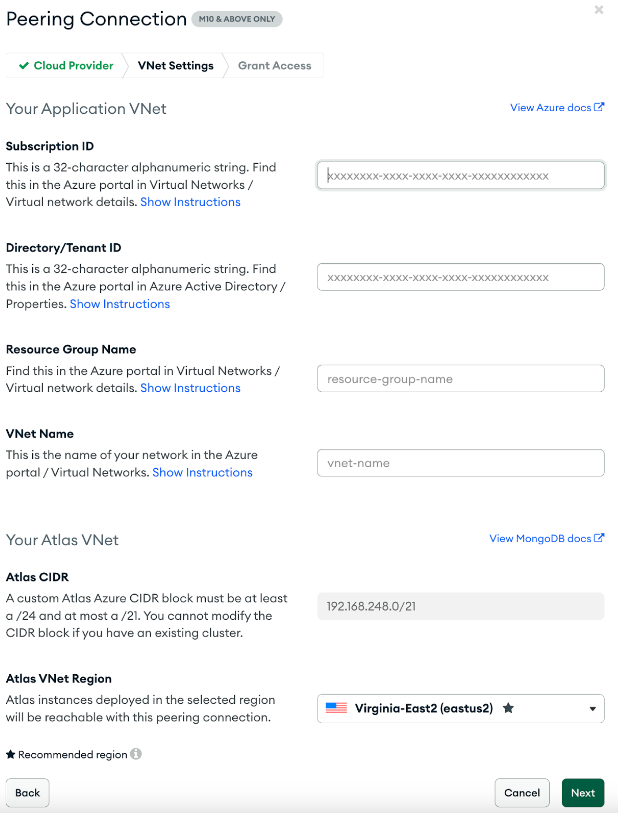
Most production workloads are not exposed to the internet. MongoDB Atlas supports private connectivity to Azure via VPC Peering as shown in Figure 3. For more information check out the Set Up a Network Peering Connection section of the MongoDB documentation.
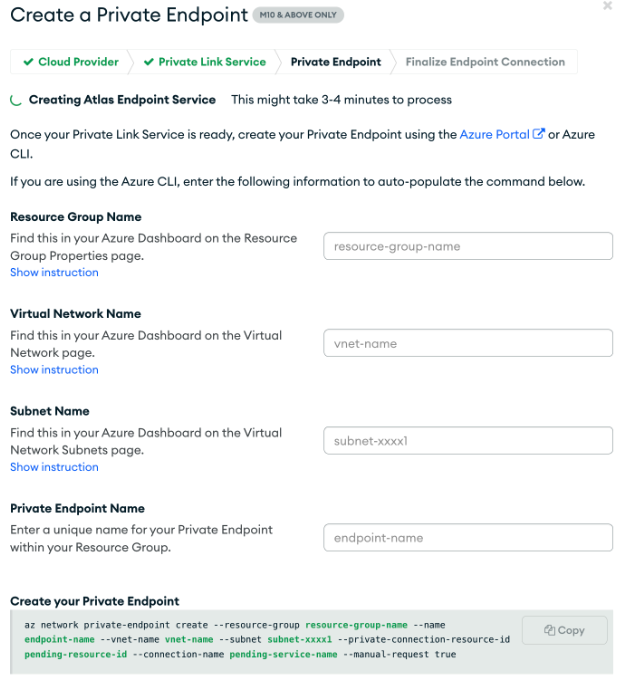
Connectivity via Azure Private Link is also supported through Atlas Private Endpoints as shown in FIgure 4. For more information setting up Private Endpoints check out the Learn About Private Endpoints in Atlas section of MongoDB Documentation.
If you wish to access your Azure Event Hub through the internet, you will need to add the public IP address of your Azure Event Hub instance to the IP Access List Entry in Atlas. You can also put 0.0.0.0 to allow access from any IP, however, this is not a security best practice. You can get the IP address of your Azure Event Hub by using a tool like traceroute or any DNS lookup tool on the web.
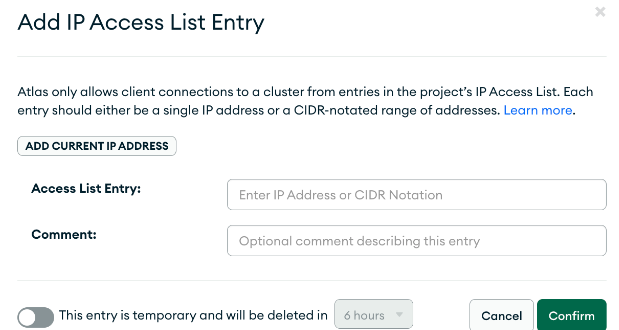
Note: If you have problems working through this demo, most likely it has to do with either networking configuration or database access, double-check that you can connect to your MongoDB Atlas cluster using the database credentials you specified. Also, make sure the IP address of the Azure Event Hub is added to the IP Access List or you set 0.0.0.0 to allow access from anywhere.
Installing the Azure CLI tool
Everything we do in this demo with regard to Microsoft Azure will use the Azure CLI command line tool. While you can do everything through the Azure Portal, using the tool provides you an opportunity to get comfortable with creating azure resources via scripting which ultimately makes it easier to deploy and automate.
Installing the Azure CLI https://docs.microsoft.com/en-us/cli/azure/install-azure-cli?view=azure-cli-latest
Demo Setup
In this demo, we will use Microsoft Azure and create an Azure Event Hub. An Event Hub can be thought of as a Kafka topic. We will use Docker to spin up a Kafka-Connect container and install our MongoDB Connector for Apache Kafka to this container instance. A python application will be used to write data into a source collection and to read data from a sink collection.
Creating the Azure Resources
This demo will require a resource group and an Azure Event Hub. The following is how to set up the resource group and Azure Event Hub using the Azure CLI. The steps are based on the following documentation: https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-quickstart-cli
If you have not already configured the Azure CLI tool with your subscription information perform the following:
You will be asked to log in with your Microsoft Account. Next, set the context of the CLI tool by specifying which subscription to use. In this example our subscription is called, “Pay-As-You-Go” but your name will vary.
Now we are ready to start creating the resources needed for the demo. First, create an Azure Resource Group in the Eastern US datacenter.
Next, create an Azure Event Hub called, “MongoIoTHub” in this same resource group.
Note that the Event Hub name needs to be unique across all of Azure so be creative. Upon success you will get a response similar to the following:
Next, you need to get the connection string to the Event Hub itself. This can be done in the Azure Portal under Shared Access Policies or using the AZ CLI tool as follows:
Note for a demo we can use the RootManageSharedAccessKey. This key is provided by default, however, in a real production deployment, you would want to create another Shared Access Policy that is restricted to the minimal amount of permissions your application needs such as Send and/or Listen access.
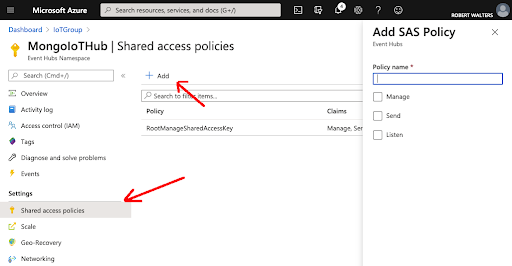
The results will include an Endpoint fields that contains connection information.
Next, let’s create a test topic to make sure everything is set up correctly. We can create the Azure Event Hub a.k.a Kafka topic via the AZ tool as follows:
Upon success you will see something like the following:
Now that we have the Azure Event Hub created, we can start sending and receiving messages. A great tool to test basic connectivity to a Kafka topic is KafkaCat.
Using Kafkacat with Azure Event Hubs
Kafkacat is an open-source tool that can be used to send and receive messages to a Kafka topic. It has nothing to do with Azure Event Hubs, rather it can be used with any Apache Kafka cluster (including other Kafka services such as Confluent Cloud). For additional information on using Kafkacat specifically with Azure Event Hubs check out the online documentation.
When using Kafkacat with Azure Event Hubs, the important thing to remember is passing the correct security parameters. While you can pass all the required parameters individually with the -X parameter, it will be easier to create a config file then just pass the config file to kafkacat using the -F parameter.
To create the configuration file, create a new file let’s call it “kc.config”. Next, Remember to replace the values below as needed to align with your own deployment.
To test that we can send and receive messages to our event hub, open two terminal windows. In one window run kafkacat as a consumer (identified by the -C parameter) to the “mytopic” event hub (a.k.a kafka topic) that we created earlier.
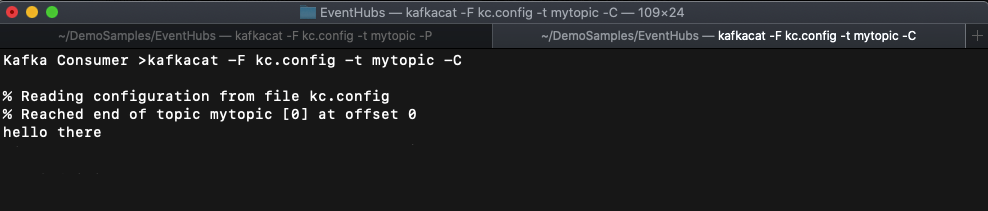
When you run this command you will see, “% Reading configuration from file kc.config” and nothing more as it is sitting there waiting for messages on the topic. In a new terminal window run kafkacat as a producer (identified by the -P parameter) as follows:
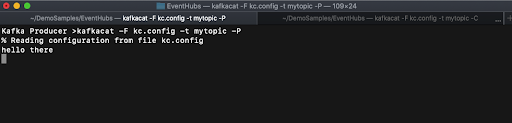
When you run this command you will see the same, “% Reading configuration from file kc.config” message. Now we can type something like, “Hello World” and hit return. Flip over to the terminal window that is running the consumer and you will see the message show up (as seen in Figure 5). Now that we have verified our network connectivity to the Azure Event Hubs let’s use Docker to stand up the Kafka Connect components.
Using Docker to spin up Kafka Connect container
Since the Azure Event Hub credentials are written multiple times in the docker-compose file, let’s create a “.env” file to store the credentials once. When we run the docker-compose command it will read this configuration file and use the values within the script. Remember to change the values in the text below to match your configuration.
The docker-compose file will leverage the latest version of Kafka connect and build the latest version of the MongoDB Connector for Apache Kafka via the Dockerfile-MongoConnect file. These two configuration files are as follows:
Docker-compose.yml file
Dockerfile-MongoConnect file
Finally, run a docker-compose up in the directory of the above files. This will launch an instance of Kafka Connect and connect to the Azure Event Hub. If you run into any issues, double-check you pasted the right credentials in the .env file.
Configuring the MongoDB Connector for Apache Kafka
Once the Kafka Connector is running we can make our REST API calls to define the source and sink. Note you can view the Kafka Connect logs when it's running in a Docker container by issuing docker logs <
Defining the source
Log in to your MongoDB Atlas cluster and obtain the connection string. Replace it in the connection.uri and issue the following command:
The command above will tell the Kafka Connector that we want to create a source to the Source collection in the EventHubDemo database. The topic will be created for us and we specified a topic.prefix of “demo” thus our full topic (i.e. Azure Event Hub name) will be “demo.EventHubDemo.Source”. In this example, we did not specify any pipeline so we will capture every event that occurs within the source. If we wanted to capture only inserts or respond to data that matches a particular filter we would define a pipeline. An example of a pipeline that only captures insert events is as follows:
Upon a successful configuration, you will receive a JSON response. For a complete list of supported source connector parameters check out the online documentation.
Defining the Sink
Replace the values below with your MongoDB Atlas cluster connection string and execute the following command:
In the above configuration, the MongoDB Connector will write data from the topic, “demo.EventHubDemo.Source” into the “Sink” collection in the “EventHubDemo” database. In this example, we do not use schemas, however, if your data on the topic leveraged schemas like JSON Schema or Avro, you could perform transforms on the data or write your own message transform. For a complete list of properties check out the online Sink documentation.
Putting it all together
At this point, we are ready to push data into the “Source” collection. To help with inserting data into the source collection and querying the sink collection we will use a python application. The source of this app and all the other files in this paper are located in GitHub at https://github.com/RWaltersMA/azure-event-hubs-mongo.
Before running this python application, make sure your Kafka Connector is configured correctly by following the instructions in the “Configuring the MongoDB Connector for Apache Kafka” section.
The create-stock-data app has the following parameters:
| Parameter | Default Value | Description |
|---|---|---|
| -s | 10 | The number of financial stock symbols to generate |
| -c | mongodb://localhost | The connection to a MongoDB cluster |
| -d | Stocks | The database to read and write to |
| -w | Source | The collection name to insert into |
| -r | Sink | The collection name to read from |
This application randomly generates a number of stocks and their initial values. It will write new values every second for all securities into the collection defined with the “-w” parameter. If we configured the source and sink correctly in the previous section, as the data arrives in the collection, Kafka Connect will push the data into the Azure Event Hub. From there the Sink will notice the data in the Azure Event Hub and write it to the collection defined in the “-r” parameter.
The output of the python application is as follows:
The application spins up two threads, one to write the data every second and the other to open a change stream against the collection defined in the “-r” parameter. Following the successful “writing stock data” message you will see the data being read from the change stream on the sink. This data has made the trip from the source collection out to Azure Event Hub and back to a sink collection.
Summary
In this blog, we walked through how to set up and configure the MongoDB Connector for Apache Kafka. While the demonstration was a simple read from collection, send to Azure Event Hub then write back to another collection, you can take this example and expand on it depending on how you will ultimately use MongoDB for Apache Kafka connector. For more information on the connector and to learn about the latest updates check out the documentation.
References
- https://github.com/Azure/azure-event-hubs-for-kafka
- https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-get-connection-string#get-connection-string-from-the-portal
- https://github.com/Azure/azure-event-hubs-for-kafka/tree/master/quickstart/kafkacat
- https://github.com/edenhill/kafkacat#configuration
- https://github.com/Azure/azure-event-hubs-for-kafka/tree/master/tutorials/connect