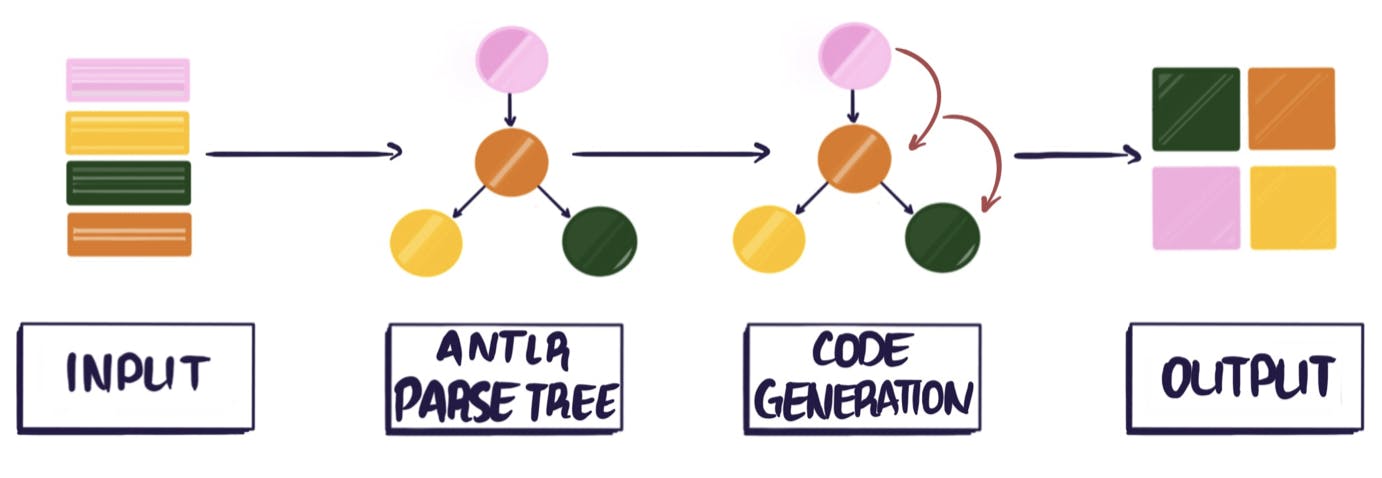
MongoDB Compass, the UI for MongoDB, recently introduced a pair of features to make it easier for developers to work in their chosen language. Users can now export the queries and aggregations they build in the UI to their preferred language. Soon they will also be able to input them in their preferred language. Allowing developers the flexibility to choose between multiple input languages and multiple output languages when using Compass required us to build a custom solution in the form of a many-to-many transpiler. Most compilers are one-to-one, or less commonly, one-to-many or many-to-one. There are hardly any many-to-many transpilers. To avoid having to start from scratch, we leveraged the open source parsing tool ANTLR which provided us with a set of compiler tools along with preexisting grammars for the languages we needed. We successfully minimized the amount of additional complexity by coming up with a creative set of class hierarchies that reduced the amount of work needed from n² to n.
Motivation
MongoDB Compass is an application that provides a UI for the database and helps developers to iteratively develop aggregations and queries. When building queries, the application currently requires input to be made in a JavaScript-based query language called MongoDB Shell.
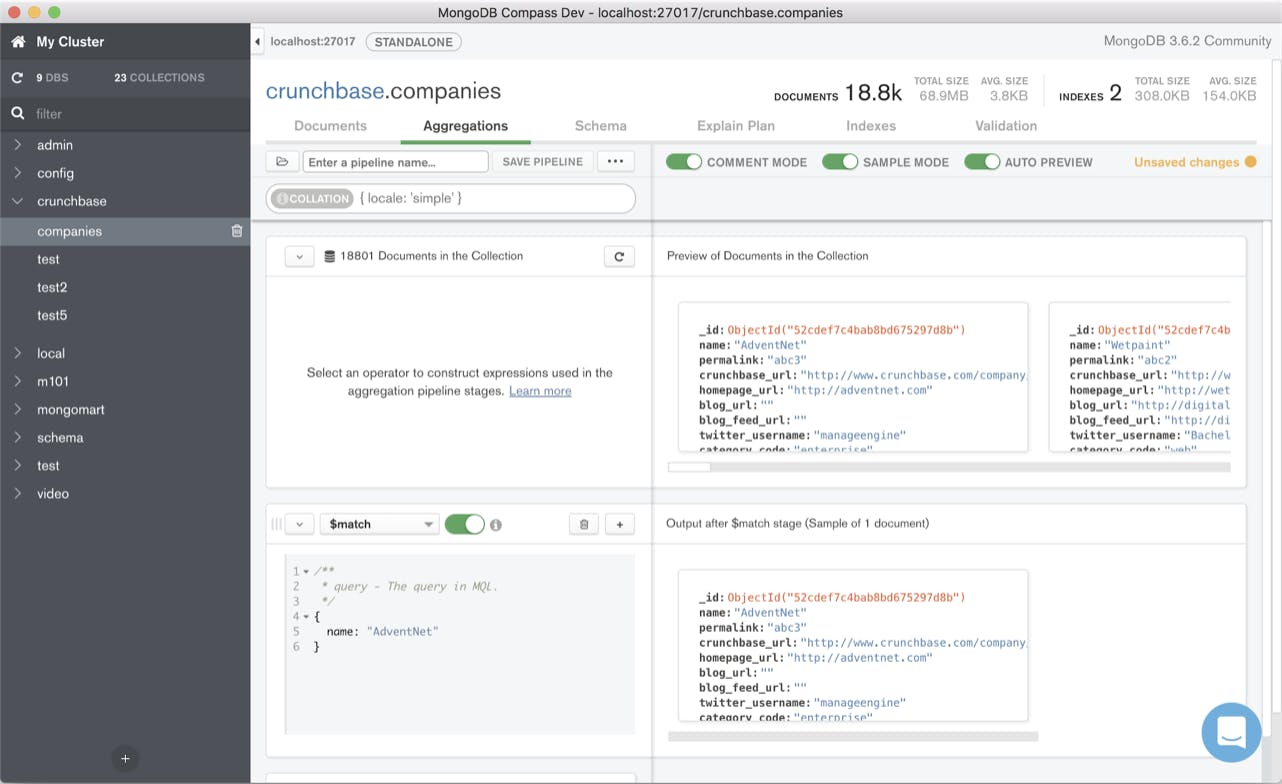
To enable developers to use their preferred programming language when developing aggregation pipelines and queries, we wanted to add functionality in two parts. First, we wanted to allow developers that are familiar with the MongoDB Shell to export queries they create in the language they need (Python, Java, etc.).
Second, we wanted to allow developers to use their language of choice while building a query. To achieve both and allow users maximum flexibility, our system therefore needed to accept multiple input languages as well as generate multiple output languages in an efficient way.
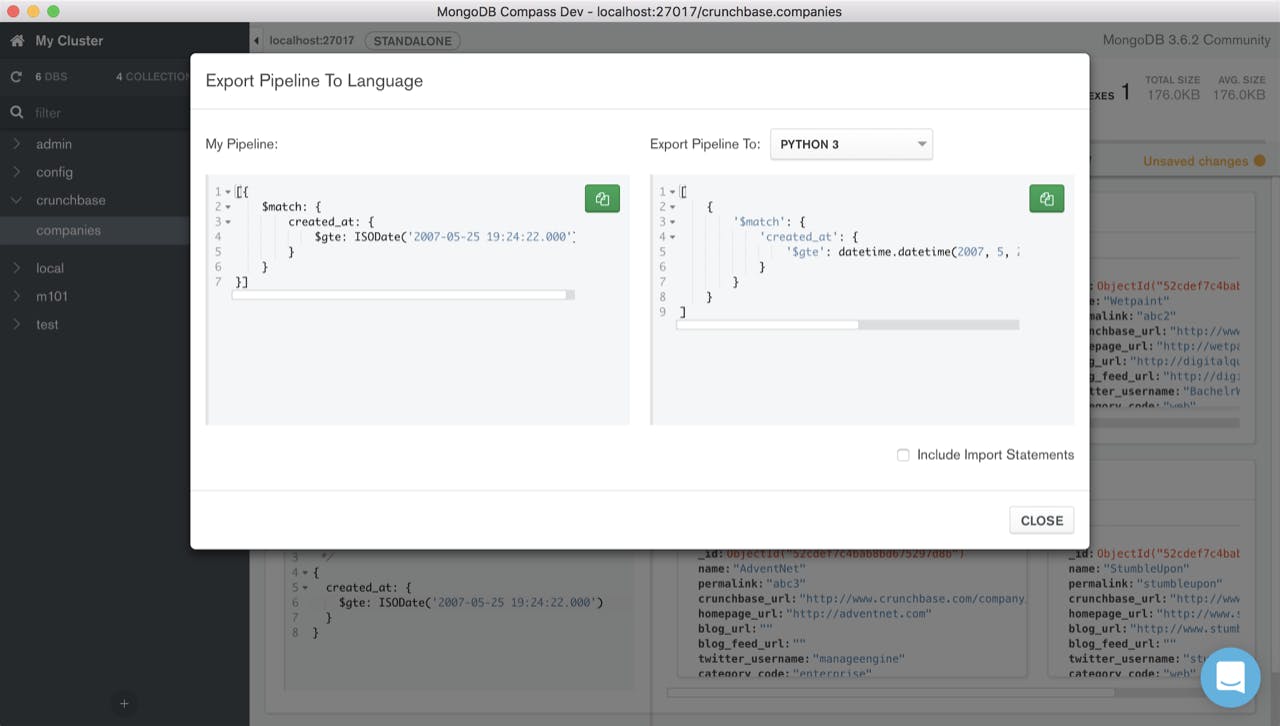
At the basis of these features is sophisticated compiler technology in the form of a transpiler. A transpiler is a source-to-source compiler which takes the source code of a program written in one programming language as its input and produces the equivalent source code in another programming language. Since our transpiler currently supports extended JSON, also called BSON, we call it a BSON transpiler. While we currently support only a subset of each programming language, the transpiler is designed in a way that would allow us to extend support to include the entire language syntax.
Design Approach
The Compass application is designed with an extensible plugin architecture allowing us to build the transpiler as a standalone plugin. To work with the Electron framework our application is based on, our plugin needed to be executable in JavaScript. There are lots of different transpilers in JavaScript which we considered. However, for our use case, we needed any language to any language transformation with support for BSON, which meant we needed a custom solution.
Compass queries always take the form of either an array of BSON documents (stages for the aggregation pipeline) or a BSON document (for other queries) containing the MongoDB query language. While this constraint reduces the scope of the problem for the BSON transpiler, the language subset we need to support is large and complex enough that we decided to treat the problem as if we were adding full-language support.
The naive approach to building a source-to-source compiler supporting multiple languages would result in a polynomial amount of effort since the number of language combinations is the product of the number of input and output languages. We needed to build a sustainable design so that adding new input and output languages only requires building O(1) components per language. This reduces the entire problem to O(n) for the number of languages n. We achieved this by abstracting the problem into independent input and output stages that are loosely coupled by their interface to a shared, intermediate, in-memory data structure: a parse tree. The input language stage just needs to build the tree, and the output language stage just needs to read it.
Most compilers have two primary stages: parsing and code generation. The parsing stage is responsible for turning the literal text of a program into a tree representing an abstraction of its meaning, and the code generation stage walks that tree and produces an output that can be executed -- generally a binary of machine or virtual machine instructions. A key observation is that a source-to-source compiler can be seen as a specialized compiler in which the code generation stage generates program text, in another user-friendly language, instead of machine code. The design of our transpiler stems from that concept.
Parsing
In order to process some source code, such as the string new NumberDecimal(5), a lexical analyzer or lexer takes raw code and splits it into tokens (this process is known as lexical analysis). A token is an object that represents a block of text corresponding to one of the primitive components of the language syntax. It could be a number, label, punctuation, an operator, etc.
In the parsing stage these tokens are then transformed into a tree structure that describes not only isolated pieces of the input code but also their relationship to each other. At this point the compiler is able to recognise language constructs such as variable declarations, statements, expressions, and so on. The leaves of this tree are the tokens found by the lexical analysis. When the leaves are read from left to right, the sequence is the same as in the input text.
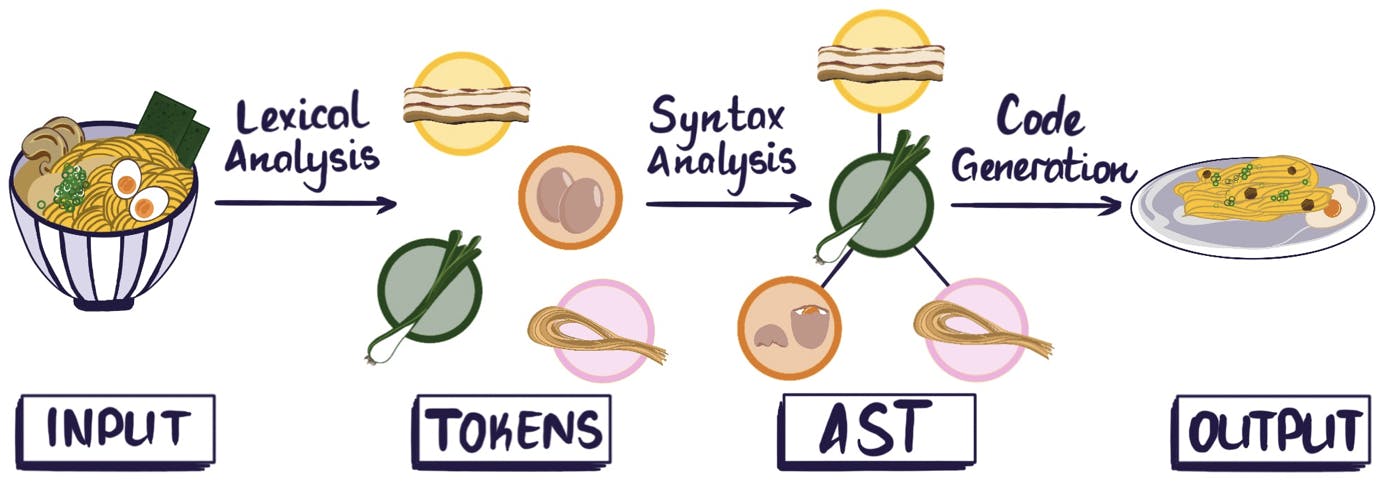
We did not want to write our own parser and lexer since it is incredibly time consuming even for a single language, and we have to support multiple. Luckily, there are many "parser-generator" tools that efficiently generate syntax trees from a set of rules, called a grammar. These tools take an input grammar, which is hierarchical and highly structured, parse an input string based on that grammar, and convert it to a tree structure.
The tricky part of using parser-generators is the tedious and error-prone process of writing the grammars. Writing a grammar from scratch requires a detailed knowledge of the input language with all of its edge cases. If the transpiler needs to support many programming languages, we would have to write grammars for each of the input languages which would be a huge task.
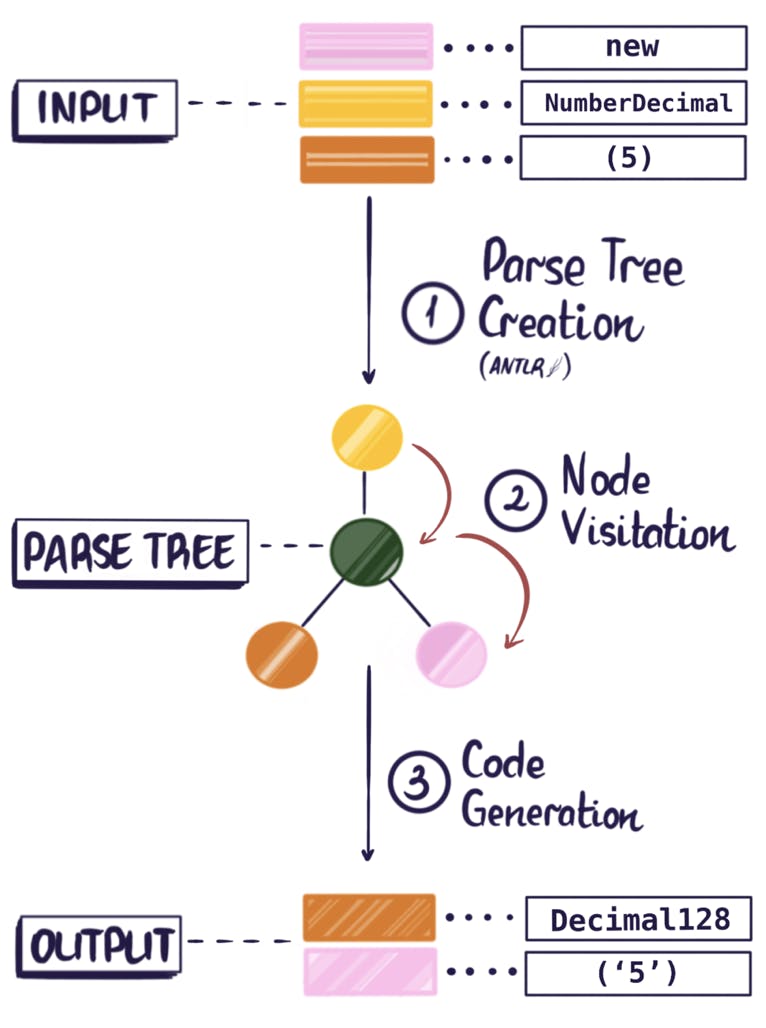
This is why we decided to use ANTLR, a powerful parser-generator that, most importantly, already has grammars for almost all programming languages of interest. ANTLR also has a JavaScript runtime, allowing us to use it in our Node.js project. We considered using the LLVM-IR, a different set of compiler technologies that compile to an intermediate high-level representation. This approach would then need a separate step to compile the intermediate representation into the target language. This is a common pattern for multi-platform compilers, like the Clang/LLVM project. Unfortunately, there are not many existing compilers that go from the intermediate representation back to user programming languages. We would have had to write those compilers ourselves, so ultimately using LLVM would not have saved us much effort.
The code snippet below illustrates the basic structure of a program that builds a parse tree for ECMAScript (Javascript) input source code. This code imports auxiliary lexer and parser files and lets ANTLR pull characters from the input string, create a character stream, convert it to a token stream and finally build a parse tree.
The resulting parse tree inherits from the ANTLR-defined ParseTree class, giving it a uniform way to be traversed.
Note that the parsing stage and resulting parse tree are determined by the input language; they are completely independent of the stage where we generate the output language into which we seek to translate the source code. This independence in our design allows us to reduce the number of parts we need to write to cover our input and output languages from O(n²) to O(n).
Code Generation
Tree types
Using ANTLR for its library of pre-built grammars requires a slight compromise in our design. To understand why, it is necessary to understand the difference between two terms that are related and sometimes used interchangeably: a parse tree and an abstract syntax tree (AST). Conceptually these trees are similar because they both represent the syntax of a snippet of source code; the difference is the level of abstraction. An AST has been fully abstracted to the point that no information about the input tokens themselves remains. Because of this, ASTs representing the same instructions are indistinguishable, regardless of what language produced them. By contrast, a parse tree contains the information about the low-level input tokens, so different languages will produce different parse trees, even if they do the same thing.
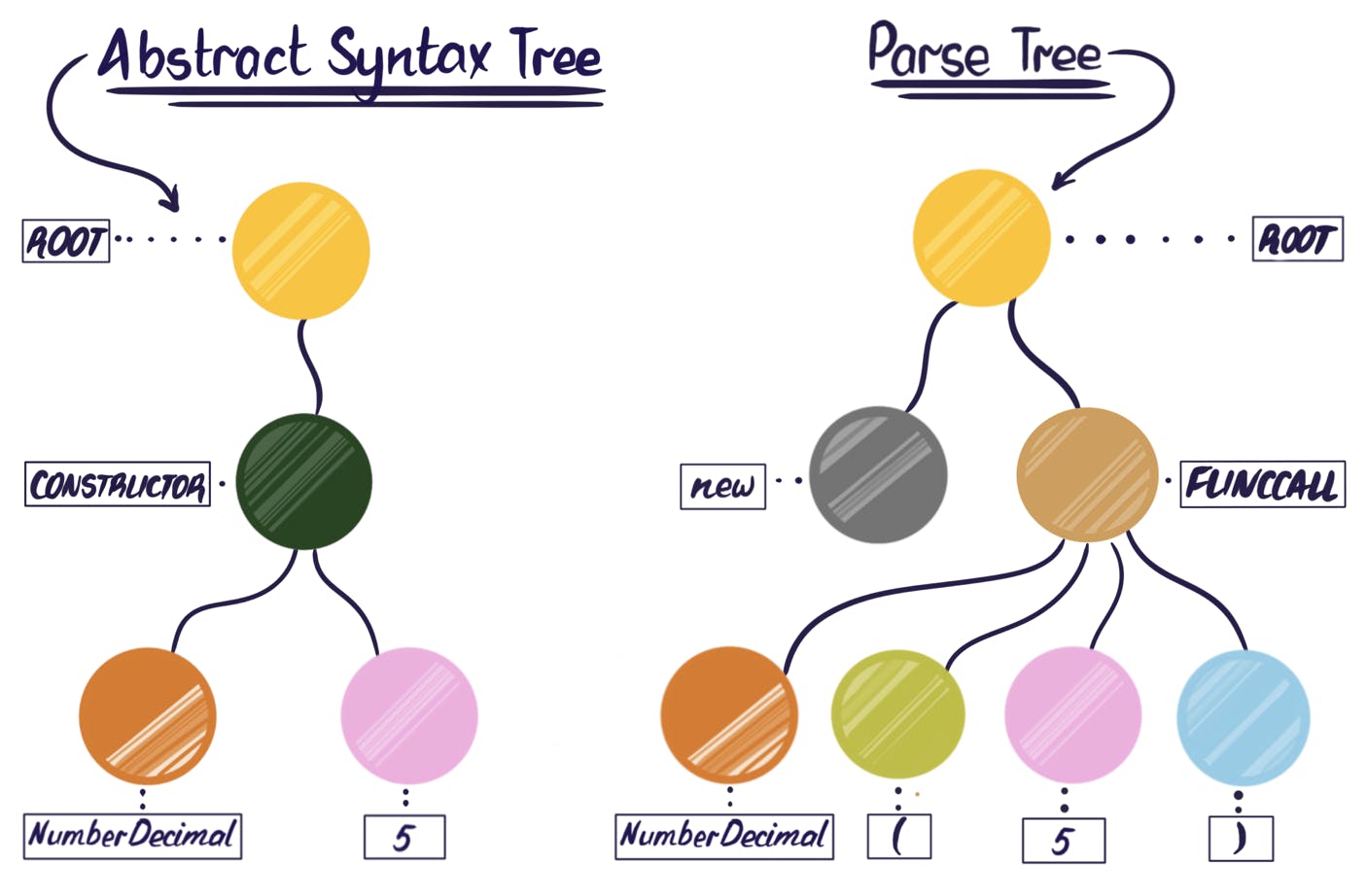
Ideally, our code generating stage would operate on an AST, not a parse tree, because having to account for language-specific parse trees introduces complexity we’d rather avoid. ANTLR4, however, only produces read-only parse trees. But the advantages of using ANTLR and its ready-made grammars are well worth that trade-off.
Visitors
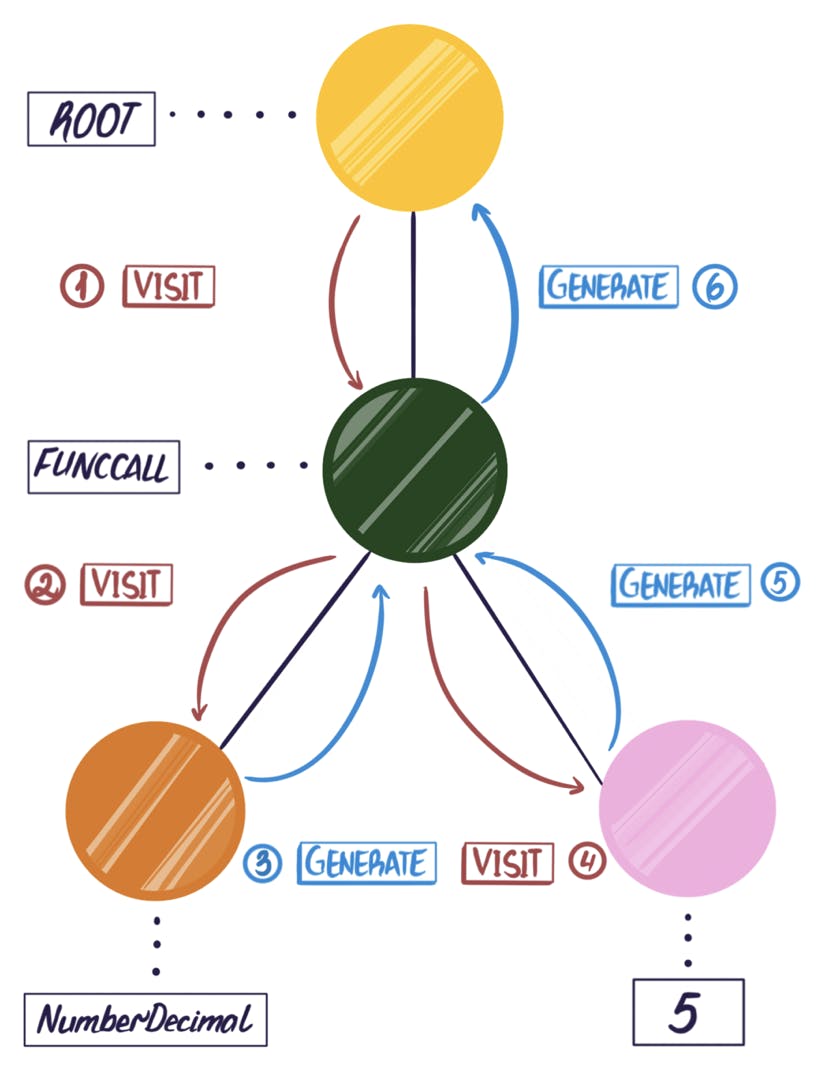
Like most compilers, the BSON transpiler uses a visitor pattern to traverse parse trees. ANTLR not only builds a parse tree but it also programmatically generates a skeleton visitor class. This visitor class contains methods for traversing parse trees (one visit method for each type of node of the tree). All of these methods begin with visit and end with the name of the node that it will visit - e.g. visitFuncCall() or visitAdditiveExpression(). The node names are taken directly from the input language grammar file, so each visitor class and its methods are tailored to the input language grammar. In the ANTLR-generated visitor class, these methods do not do anything except recurse on the child nodes. In order for our visitor to be able to transpile code, we need to subclass the generated visitor class and override each visit method to define what to do with each type of node.
Since the BSON transpiler is built to support multiple input languages, and each language will produce a different kind of parse tree, we need to create one custom visitor for each input language supported by Compass. However, as long as we avoid building a custom visitor for each combination of input and output language, we are still only building O(n) components.
With this design, each visitor is responsible for traversing a single language parse tree. The visitor calls functions as it visits each node and returns the original text of the node or can transform this text the way we need. Starting from the root, the visitor calls the visit method recursively, descending to the leaves in a depth-first order. On the way down, the visitor decorates nodes with metadata, such as type information. On the way up, it returns the transpiled code.
Generators
With a brute force solution, the visit* methods of the visitor would contain code for generating the output language text. To generate multiple output languages, we would have to specialize each method depending on the current output language. Overall, this approach would subclass every language-specific visitor class once for every output language, or worse yet, put a giant switch statement in each of the visit* methods with a case for each output language. Both of those options are brittle and require O(n²) development effort. Therefore we chose to decouple the code for traversing the language-specific trees from the code for generating output. We accomplished this by encapsulating code-generation for each language into a set of classes called Generators, which implement a family of emit* methods, like emitDate and emitNumber used to produce the output code.
Class composition
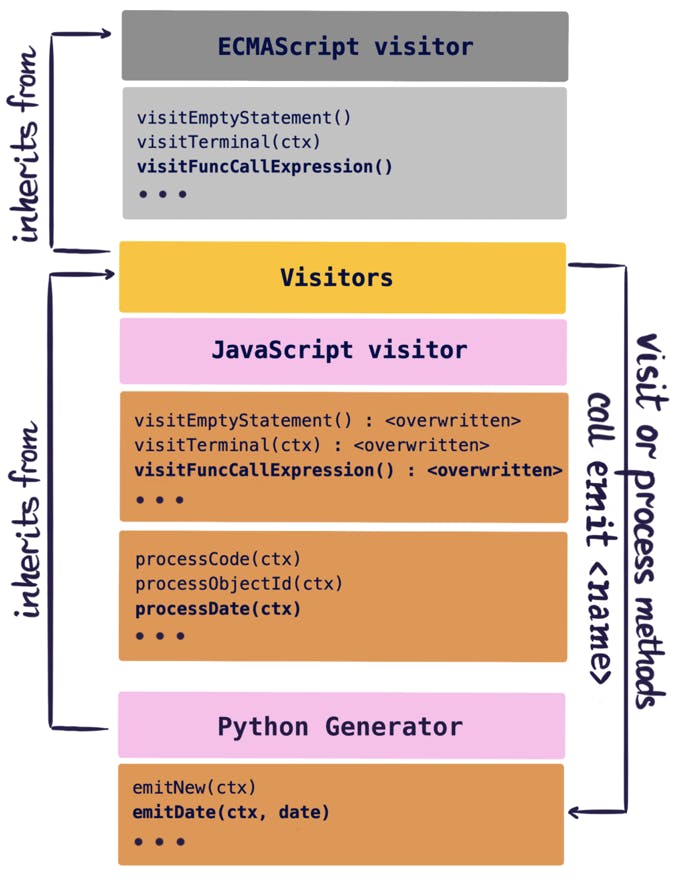
Our design was informed by the need for the visitor to be able to call generator methods without needing to know which generator they were using. Since code generation actually has a lot in common regardless of the output language, we wanted to implement a system where we could abstract the default behavior as much as possible and leave the generator to only handle edge cases.
We chose to make use of JavaScript’s dynamic mechanics for inheritance and method dispatch by having the generator class inherit from the visitor class. Because JavaScript does not require that methods be defined before they are called, the visitor can call emitmethods on itself that are actually defined in the generator and the generator can call visitor methods to continue the tree traversal. Using a generator class determined by the output language and a visitor class determined from the input language, we are able to compose a transpiler on-the-fly as it is exported. Generators are similar to an abstract interface, except there are no classic interfaces in JavaScript.
As illustrated in the code snippet below, for each language combination our application creates a specialized transpiler instance composed of the corresponding visitor and generator classes. When our application receives a piece of code from the user, it creates a parse tree. The transpiler then visits the parse tree, using the ParseTreeVisitor’s visit method inherited from our custom Visitor subclass, and the language-specific, ANTLR generated visitor class (such as ECMAScriptVisitor).
Tree Traversal Example
Simple Nodes
In the most straightforward case, think the JavaScript snippet of text "hello world", the first thing the custom visitor class needs to do is specify the entry point for the tree traversal. Since the entry nodes in different languages have different names (i.e. file_input in Python, but program in JavaScript), we define a method in each visitor called start that calls the visit method for the root node for that input language. That way our compiler can simply call start on each visitor without having to worry what the root node is called.
The default behavior of the ANTLR visit methods is to recur on each child node and return the results in an array. If the node doesn’t have any children, then the visit method will return the node itself. So if we do not overwrite any of the ANTLR methods, then the return value of our start method would be an array of nodes. To go from returning nodes to returning strings in our simple "hello world" example, we first overwrite the visitTerminal method so that the leaf nodes will return the raw text stored in the node. We then modify the visitChildren method so that instead of putting the results of visiting each child node into an array, the results get concatenated into a string. Those two changes are enough for our "hello world” example to be fully translated into a language that uses the same string representation, like Python.
Transformations
However, we cannot always just concatenate the text values of the terminal nodes to form the result. Instead we need to transform floating point numbers, as well as numbers in different numeral systems without losing any precision. For string literals we need to think about single and double quotes, escape sequences, comments, spaces and empty lines. This type of transformation logic can be applied to any type of node.
Let’s look at a concrete example: In Python, an object property name must be enclosed in quotes ({'hello': 'world'}); in JavaScript this is optional ({hello: 'world'}). In this particular case, this is the only one modification we need in order to transform a fragment of JavaScript code into Python code.
The propertyExpressionAssignment node has two child nodes (propertyName and singleExpression). To get the values of these two child nodes, we need to traverse them separately as left hand side and right hand side subtrees. Traversing subtrees returns the original or transformed values of the child nodes. We can then build a new string using retrieved values here to make up the transformed code fragment. Instead of doing this in the visitor directly, we check if the corresponding emit method exists.
If the visitor finds a proper emit method, it will delegate the transformation process to the generator class. By doing this we free our visitors from knowing anything about the output language. We just assume that there is some generator class that knows how to handle the output language.
However, If this method doesn’t exist, the visitor will return the original string without any transformation. In our case we assume a emitPropertyExpressionAssignment was supplied and this will return the transformed JavaScript string.
Processing
In more complex cases, we must do some preprocessing in the visitor before we can call any emit methods.
For example, date representations are a complex case because dates have a wide range of acceptable argument formats across different programming languages. We need to do some preprocessing in the visitor so we can ensure that all the emit methods are sent the same information, regardless of input language. In this case of a date node, the easiest way to represent date information is to construct a JavaScript Date object and pass it to the generator. Node types that need pre-processing must have a process* method defined in the visitor to handle this pre-processing. For this example it would be called processDate.
For this processDate method, since we are compiling JavaScript and the transpiler is written in JavaScript, we took a shortcut: executing the users input to construct the Date. Because it has already been tokenized we know exactly what the code contains so it is safe to execute in a sandbox. For processing dates in other language we would instead parse the results and construct the date object through arguments. Upon completion, the process method will then call the respective emit* method, emitDate and pass it the constructed Date as an argument. Now that we can call the required process and emit methods from the visitor’s appropriate visit method.
Given the input string Date(‘2019-02-12T11:31:14.828Z’), the root of the parse tree will be a FuncCallExpression node. The visit method for this node will called visitFuncCallExpression().
The first thing the visit method does is recurse on its two child nodes. The left-hand-child represents the function name node, i.e. Date. The right-hand-child represents the arguments node, i.e. 2019-02-12T11:31:14.828Z. Once the method retrieves the name of the function it can check to see if that function requires any preprocessing. It checks if the processDate method is defined and, failing that check, whether an emitDate method is defined. Even though the emitDate method is defined in the generator, since the visitor and generator are composed into one class, the visitor treats emit methods as if they were its own class methods. If neither method exists, the visit* method will return a concatenation of the results of the recursion on the child nodes.
Every input language has its own visitor that can contain processing logic and every output language has its own generator that contains the required transformation logic for the specific language. As a rule, transformations required by all output languages will happen as processing logic, while all other transformations happen in the generator. With this design, different transpilers based on different visitors can use the same generator methods. That way, for every input language we add, we only need to define a single visitor. Similarly, for every output language we add, we only need to define a single generator. For n languages we want to support, we now have O(n) amount of work instead of having to write one visitor-generator for every language combination.
Conclusion
The Compass BSON transpiler plugin has the potential to parse and generate MongoDB queries and aggregations in any programming language. The current version supports several input (MongoDB Shell, Javascript, and Python) and output (Java, C#, Python, MongoDB Shell, and Javascript) languages.
The BSON transpiler plugin is built as a standalone Node.js module and can be used in any browser-based or Node.js application with npm install bson-transpilers.
When writing the BSON transpiler, we were guided by general compiler design principles (lexical analysis, syntax analysis, tree traversal). We used ANTLR to reduce the amount of manual work required to parse the input languages of interest, which allowed us to focus mostly on modularizing the code generation process. A major benefit of modularizing the language definitions is that a user can contribute a new output language without needing to know anything about the input languages that are currently supported. The same rule applies for adding a new input language: you should be able to define your visitor without needing to care about the existing generators.
The latest version of the BSON transpiler plugin is more complex and powerful than what has been covered by the current blog post. It supports a wider range of syntax through the use of a symbol table. It also includes the entire BSON library, function calls with arguments and type validation, and informative error messages. On top of that, we have added a high level of optimization by using string templates to abstract a lot of the code generation. All of these developments will be described in a future blog post.
Written by Anna Herlihy, Alena Khineika, & Irina Shestak. Illustrations by Irina Shestak
Further Reading
- Compiler in JavaScript using ANTLR by Alena Khineika;
- Compilers: Principles, Techniques, and Tools by Alfred V. Aho, Monica S. Lam, Ravi Sethi and Jeffrey D. Ullman;
- The Elements of Computing Systems by Noam Nisan and Shimon Schocken.