Update June 25, 2024: Search Nodes are now in general availability for Google Cloud and Microsoft Azure.
We’re excited to announce Search Nodes are now in General Availability for AWS and Public Preview for Google Cloud, including a memory optimized, low CPU option that is optimal for Vector Search (also in GA). This makes resource contention or the possibility of a resulting service interruption a thing of the past. Read the blog below for the full announcement and list of benefits.
While scalability has become a common buzzword in today’s enterprise vernacular, it’s something we take extremely seriously at MongoDB. Whether it’s increasing a certain capability to be used in additional contexts, or continuing to increase the capacity of a certain technology in size or scale, our product teams are always looking to maximize scalability for our customers’ most demanding workloads.
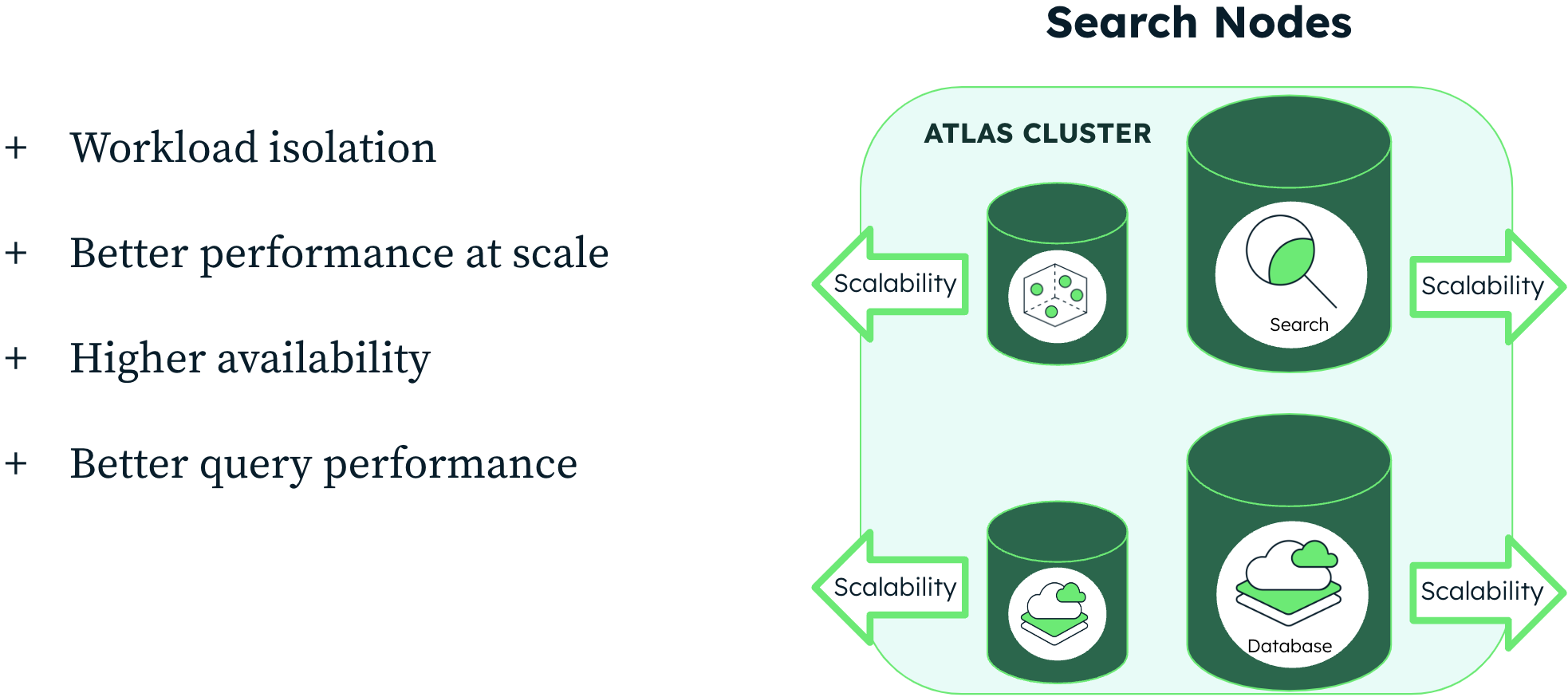
Today we are excited to take the next step in this journey with the announcement of Search Nodes, now available in GA. Search Nodes provide dedicated infrastructure for Atlas Search and Vector Search workloads, allowing you to fully scale search independent of database needs. Incorporating Search Nodes into your Atlas deployment allows for better performance at scale, and delivers workload isolation, higher availability, and the ability to optimize resource usage. We see this as the next evolution of our architecture for both Atlas Search and Vector Search, furthering our modern database, including the benefits of a fully managed sync without the need for an ETL or index management. We have listened to the feedback from our customer base and are excited to take the next step in bringing this feature closer to general availability.
So what exactly is changing, and what are the benefits of Search Nodes?
To see where we’re going, let’s take a brief look at where we have been. Previously, Atlas Search has been co-located with Atlas on Atlas Nodes (see diagram below). The pros of this configuration are that it is simple and cheap, enabling a large portion of our current user base to get started quickly.

However, there are a couple of consequences from this setup. Because Search and Vector Search are co-located on Atlas Nodes and clusters, users have to try and size their workload based on both Search and Database requirements using traditional Atlas deployment.
This introduces potential issues, including the possibility of resource contention between a database and search deployment, which has the potential to cause service interruptions. It also becomes difficult having both resources commingled, as you lack the granularity to set limits on the share of the overall workload from your database or search.
With our announcement of Search Nodes available in GA, these considerations are a thing of the past, as we now offer the developer greater visibility and control, with benefits including:
- Workload isolation
- Better performance at scale (40% - 60% decrease in query time for many complex queries)
- Higher availability
- Improved developer experience
Getting started with Search Nodes is super simple — to begin, just follow these steps in the MongoDB UI:
- Navigate to your “Database Deployments” section in the MongoDB UI
- Click the green “+Create” button
- On the “Create New Cluster” page, change the radio button for AWS or Google Cloud for “Multi-cloud, multi-region & workload isolation” to enabled
- Toggle the radio button for “Search Nodes for workload isolation” to enabled. Select the number of nodes in the text box
- Check the agreement box
- Click “Create cluster”
For existing Atlas Search users, click “Edit Configuration” in the MongoDB Atlas Search UI and enable the toggle for workload isolation. Then the steps are the same as noted above.
We’re excited to be offering customers the option of dedicated infrastructure that Search Nodes provides and look forward to seeing the next wave of scalability for both Atlas Search and Vector Search workloads. We’ll also be announcing a more cost and performance efficient configuration for Vector Search coming soon. For further details you can jump right into our docs to learn more. We can’t wait to see what you build!