If you’ve gotten this far in my Safe Software Deployment series, you know how scary deployment day can be. Sleepless nights. Knots in the stomach. Cold sweats. These are the symptoms of uncertainty. And three decades of experience have taught me that all the positive thinking in the world won’t ensure a bug-free deployment.
That’s why I’ve developed a number of techniques that can consistently help teams minimize fear and achieve safe software deployment. In the last post, we discussed the 180 Rule. The purpose of this post is to explain how you can use “Z Deployments” to mitigate both fear and downtime. In future posts, we’ll look at both the Goldilocks Gauge and Through the Looking Glass.
Z Deployments are more than a catchy name. This is all about failed rollbacks, which in my experience are the biggest source of downtime in any software deployment pipeline. Now, we all try our best to eliminate the need for rollbacks in the first place - but when they do happen, we want them to be successful. However, in most companies, rollbacks are only tested in Prod, not in the prior stages of the pipeline. Even if you use the 180 Rule, which encourages quick and automated rollbacks, you don’t have any more certainty that they will work. This is where Z Deployments come in.
With a Z Deployment, the goal is to make rollbacks just as predictable and reliable as your normal “roll forward” software deployments. I call this technique a Z Deployment, because if you chart out the process, it looks like a Z. But you can also think of Z Deployments as akin to pressing “Command Z” on your keyboard: undo. Fast, simple, no drama. Here’s how it works.
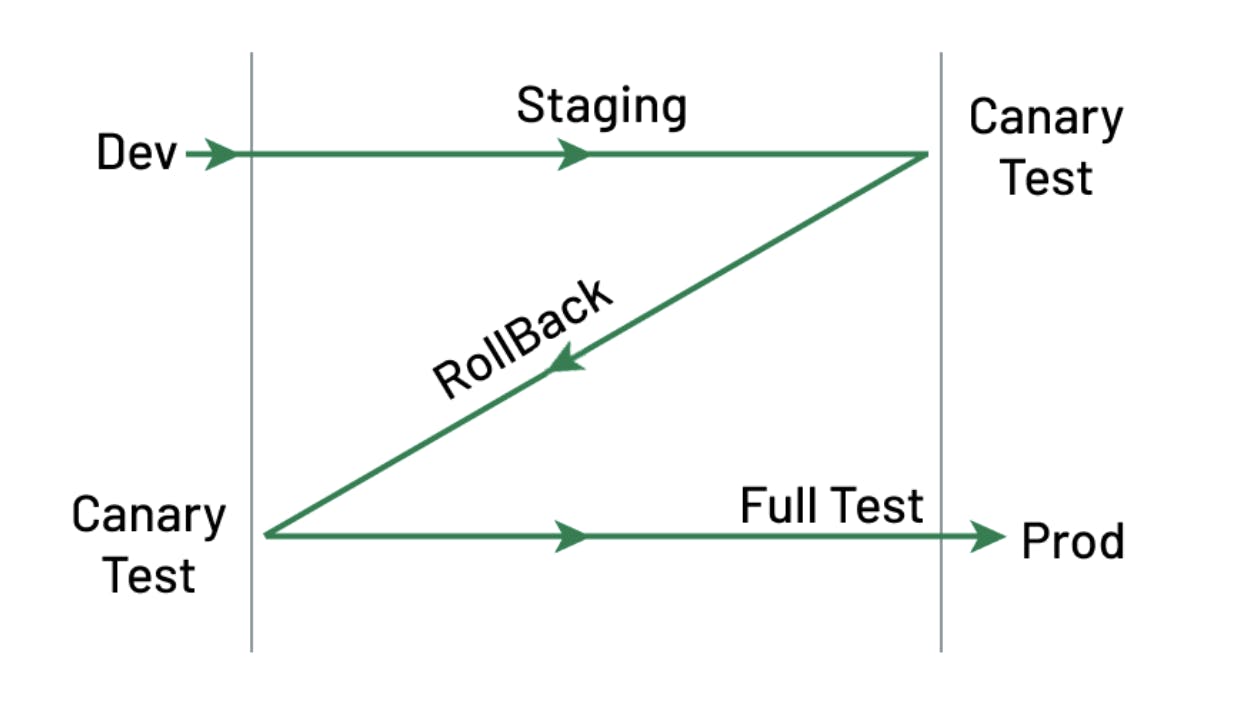
Roll your code forward from development into staging. In staging, do your canary testing.
Then roll back into development. Do your canary testing again. If it doesn’t work, then you just proved that your rollback code was faulty in some way.
Roll your code forward into staging again, and do your full testing.
If it’s successful, roll your code forward into production.
Of course, this only works if your staging environment is clean and your team trusts it. I’ll get into this more in a future post called “Through the Looking Glass.” But the bottom line is that developers need to know that things will work in production; including any needed rollbacks. And the only way to do that is to test rollbacks in staging. Your version of canary tests and full tests might be different - in a perfect world you’d run full tests three full times, but often build systems aren’t set up to do that quickly enough.
Too often, staging is not clean. But generally, when developers deploy to staging, their added functionality tends to work. Everyone else is using staging, and their functionality is working, too. This is the “Happy Path” - where engineers test that their new thing works. That sounds great. But what else happens? Adjacent things get broken.
Often when you roll back, you’re not necessarily returning to your system’s original state, either for your own software change or for the adjacent software components. Your rollback code has to undo all the state changes your deployment to staging (or prod) may have made. Otherwise, the staging environment becomes polluted, and the results in staging won’t match the results in production. Developers lose faith in staging, and deployment again becomes a terrifying ordeal.
I used to work with someone who was absolutely obsessive about staging. He ran testing, and he refused to have a long-term staging environment. Instead, his team blew away staging every month and rebuilt it from scratch. Did I like this? Absolutely. Did it work? Yes. Developers trusted staging, which meant that deployments to prod were less scary.
The next step of safe software deployment is to embrace the Goldilocks Gauge, which helps make deployments routine and even boring – in a good way. It also makes both the 180 Rule and Z Deployments easier to execute, and it’s a necessity for teams working toward continuous development. In the meantime, feel free to share your own techniques for safe deployments at @MarkLovesTech.