In today’s digital-first economy, flawless e-commerce experiences are integral to securing and maintaining customer loyalty.
We’re here to help. In this guide, we’ll discuss:
Why retailers prefer MongoDB Guidance on data modeling for product catalogs
How to make products discoverable
Driving conversions with fast and relevance-based search
In order to deliver the AI/ML-enriched and hyper-personalized retail experiences that are table stakes in the digital ecosystem, retailers are moving away from monolithic architectures. The first focus for this transformation is the product catalog, which is the window into modern e-commerce platforms.
As consumers’ preferred shopping methods shifted to e-commerce, customer preference for real-time updates has increased dramatically. A retailer’s ability to adopt this change has a direct influence on customer loyalty and business growth. A lack of a real-time, consolidated view of customer history, orders, inventory, and supply chain network updates will hurt the bottom line.
Product catalog data management is a complex problem for retailers. After years of relying on multiple monolithic, vendor-provided systems, retailers have learned that product catalogs built on legacy databases are unsuitable for modern e-commerce experiences.
In today’s vendor-provided systems, product data must frequently be moved back and forth using ETL processes to ensure all systems (in store, mobile shopping, and ecommerce) are operating on the same data set. This approach is slow, error prone, and expensive in terms of development and management. In response, retailers are now making data services available individually as part of a distributed microservices.
Data models established using Relational databases carry restrictions and limitations when it comes to realigning with newly discovered attributes and other modifications required. Inconsistent and fragmented data structures (imagine a supplier introducing new attributes that were previously not known - size, availability season etc) can be visible to end customers as inconsistent product information across channels. Many retailers using Relational databases must introduce new tables to track newer attributes that take time and effort to propagate across channels which maintain their own copy of the product data.
Single view, scalability, flexibility, and search
Modern retailers understand the need for improved web, mobile, and social media commerce experiences. Today’s customers expect the digital-first experience to follow them to brick and mortar stores, too. The next frontier of retail personalization is the seamless connection, and blurring, of the digital and physical retail experience.
How will retailers get to the hybrid future of shopping? Many are approaching the challenge by investing in cloud migration, typically with a “lift-and-shift” approach by replicating their on-premise infrastructure in the cloud. For a more transformational approach to retail modernization, a modern database providing a single, unified view across all your data assets, scale, flexibility, and integrated search functionality can thoroughly reshape floundering modernization strategies.
Single view, scalability, flexibility, and search are foundational for product catalog modernization. Here’s why:
Single view: A single view of customer data breaks down data silos, allowing retailers to utilize data to offer a consistent, integrated service. Data duplication is reduced, data consistency is increased, and a holistic view of the customer is made available to the application stack, so retailers can focus on offering stronger personalized client experiences.
Scalability: As retailers add more products to meet market demand and growth acceleration goals, including moving to markets in new regions, product catalog access slows. Retailers need application data platforms that can scale without sacrificing performance.
Flexibility: Product catalog contains the details of various product attributes with high degree of variability that continue to evolve over a period of product life cycle. A flexible document model allows evolution of diverse data sets prevalent in retail data silos, and utilizes them to a retailers’ advantage, without worrying about data duplication, stale data, or data silos. For example a retail wants to carry a specific product line only for northern regions of Canada where it is required (ice fishing gear etc)
Search: Fast, sophisticated, intuitive, relevance-based search is key to provide superior customer experience across channels, including recommendations, geospatial merchandising, and systems availability. Typical Retailer establishes a search infrastructure which becomes an additional piece of the puzzle that must be managed and maintained. MongoDB Atlas solves this problem for enabling built-in capabilities comparable with any search engine based on Lucene.
MongoDB helps developers build retail product catalogs with seven key solutions:
Omnichannel catalog
Single view
Real-time analytics
Payments
Fast & relevant full-text search
Real-time inventory and supply chain
Retail logistics: personalization
Why MongoDB works for mission critical applications
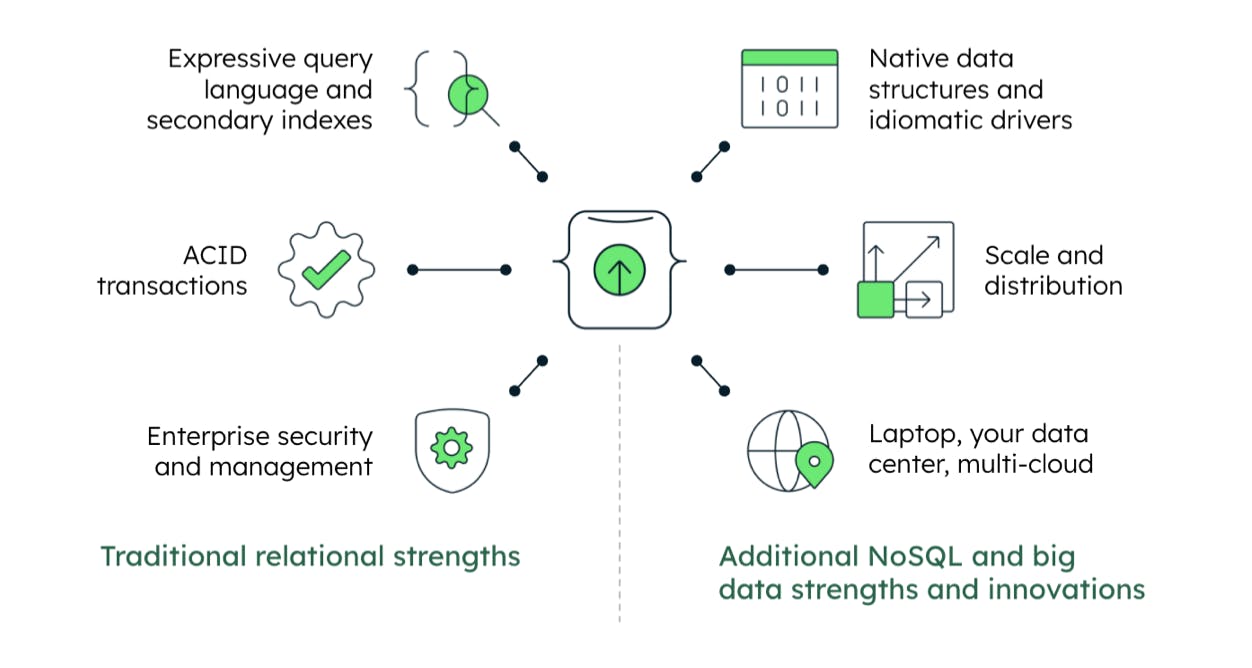
MongoDB application data platform radically simplifies data architecture by providing commonly known for its strengths in traditional relational systems with ACID transactions, secondary indexes, unions, joins, security and enterprise management, the real value comes from application data platform approach.
MongoDB’s document model resembles intuitive data modeling aligning the real world objects within native data structures, in a flexible manner. Idiomatic drivers enable developers to work with data as code. The MongoDB Query API and drivers are idiomatic to your programming language, whether it’s C#, SWIFT, Java, Javascript, etc. Ad Hoc queries, indexing, full text search, and real time aggregations provide powerful ways for accessing grouping, transforming, searching and analyzing data to support any class of workload.
This empowers you to build a global database over multiple cloud platforms, anywhere, any time with our scalability and distribution.
In retailers’ product catalogs, a single item could have thousands of variants – for example, a single shoe style that comes in six different colors and 12 sizes. Product prices vary widely based on store or geography, and each product comes with reviews, promotions, data sheets, images, videos and more. Altogether, a single SKU for a product can represent tens or hundreds of different attributes, each of which can be unique to that SKU.
MongoDB’s document data model helps contain and organize the chaos of retailers’ data silos into a consolidated rich JSON document. This model enables retailers to dramatically reduce hours spent on database administration. Development teams are freed up to focus on launching new features instead of grappling with rigid, tabular data models that bear no relation to the product being modeled, and that need to be constantly changed as new products are added to the catalog.
The specifics: data models and per store pricing
Now that you’ve learned the key reasons why retailers choose MongoDB for e-commerce solutions, we’ll take a look at the specifics of how we put some of these to use in our retail reference architecture to support a number of features, including:
Searching for products and product variants
Retrieving per store pricing for items
Enabling catalog browsing with faceted search
Product Data Model The first thing we need to consider is the data model for our items. In the following examples we are showing only the most important information about each item, such as category, brand and description:
This type of simple data model allows us to easily query for items based on the most common predicates. For example, using db.collection.findOne, which will return a single document that satisfies a query:
Get item by ID db.definition.findOne({_id:30671})
Get items for a set of product IDs db.definition.findOne({_id:{$in:[30671;452318]}})
Get items by category prefix db.definition.findOne({category:/^Shoes/Women/})
Notice how the second and third queries used the $in operator and a regular expression, respectively. When performed on indexed collections, MongoDB provides high throughput and low latency for common queries that the users are generally looking for.
Variant Data Model Another important consideration for our product catalog is item variants, such as available sizes, colors, and styles. Our item data model above only captures a small amount of the data about each catalog item. So what about all of the available item variations we may need to retrieve, such as size and color?
One option is to store an item and all its variants together in a single document. This approach has the advantage of being able to retrieve an item and all variants in a single query. However, it is not the best approach in all cases. It is an important best practice to avoid unbounded document growth. If the number of variants and their associated data is small, it may make sense to store them in the item document.
Another option is to create a separate variant data model that can be referenced relative to the primary item:
This data model allows us to do fast lookups of specific item variants by their SKU number:
db.variation.find({_id:93284847362823})
As well as all variants for a specific item by querying on the itemId attribute:
db.variation.find({itemId:30671}).sort({_id:1})
In this way, we maintain fast queries on both our primary item for displaying in our catalog, as well as every variant for when the user requests a more specific product view. We also ensure a predictable size for the item and variant documents. MongoDB document model not only gives the flexibility of dynamic schema but also enforce governance through schema validation.
Per store pricing
Another consideration when defining the reference architecture for our product catalog is pricing. We’ve now seen a few ways that the data model for our items can be structured to quickly retrieve items directly or based on specific attributes. Prices can vary by many factors, like store location, geograpies, local currencies and taxation laws. We need a way to quickly retrieve the specific price and other relevant factors of any given item or item variant. This can be very problematic for large retailers, since a catalog with a million items and one thousand stores means we must query across a collection of a billion documents to find the price of any given item.
We could, of course, store the price for each variant as a nested document within the item document, but a better solution is to again take advantage of how quickly MongoDB is able to query on _id. For example, if each item in our catalog is referenced by an itemId, while each variant is referenced by a SKU number, we can set the _id of each document to be a concatenation of the itemId or SKU and the storeId associated with that price variant. Using this model, the _id for the pair of pumps and its red variant described above would look something like this:
Item: 30671_store23
Variant: 93284847362823_store23
This approach also provides a lot of flexibility for handling pricing, as it allows us to price items at the item or the variant level. We can then query for all prices or just the price for a particular location:
*All prices: db.prices.find({_id:/^30671/})
- Store price: db.prices.find({_id:/^30671_store23/})
We could even add other combinations, such as pricing per store group, and get all possible prices for an item with a single query by using the $in operator: db.prices.find({_id:{$in:
Product catalog search: How hard is it to build full-text search?
Product catalogs contain a high degree of variability of information per product type or category. Complex product structures like serialized items/bundles/kits require an exhaustive process to update the catalog as well as to search. Product search bar on an ecommerce website need to be powered by a search technology that infers the intent of the customer to surface the right product(s) to further enhance customer experience. A product catalog is only as good as the results its search engine provides. Customers expect to find what they are looking for based on a few keystrokes and intelligent guesses by the commerce platform. They depend on the search bar, which is essentially a window into your ecommerce store. The faster and more relevant search results need to be to satisfy customer expectations, the more complex and difficult it is to build.
A common misperception is that a fast database can support the search requirements for e-commerce interfaces. But database queries are much less dynamic than search queries. Database queries are ideal for situations when developers know what queries to expect, based on how the application works. They can index fields based on common query patterns to improve performance, and queries are optimized for correctness and integrity. For example: “show me all navy blue Calvin Klein evening shoes in size 8”—it’s straightforward, there’s an exact answer, and I can create an index on the relevant brand, title, size, and color fields.
On the other hand, search queries are designed for situations where developers don’t know what user queries will look like in advance. They are often expressed in natural language questions and may require searching across a lot of different fields. These queries are optimized for speed and relevance; they return results immediately, and sort them by how closely they match the users and search terms. For example: “show me all women’s pumps for evening and casual wear — in this case, we have to consider the color, brand, image alt text, meta tags, etc. And the next query might be entirely different—it could ask, “show me all evening shoes priced between $50-$100.”
Legacy product search architectures use several different systems to deliver this capability, including: data in RDBMS, a separate search engine, and a caching layer to allow faster responses to page rendering resulting in complex architectures and tremendous synchronization need across systems.
Modern retail search requirements for e-commerce sites
Today’s online shoppers are savvy internet users. We’re all accustomed to the quick, robust search results we get from Google. Once again, there are 7 key solutions that MongoDB offers to help retailers build search experiences that run like Google and give consumers the relevant results they need to make quick and easy purchases.
Here are the key search requirements for e-commerce sites:
Fuzzy search, autocomplete, synonyms, and analyzers help users get the right search results quickly and easily.
Faceted search and counts help users efficiently navigate categorized search results on several attributes
Highlighted extract snippets help users understand a product’s relevance to their search term
Geospatial search allows users to filter and return results by location
Response within milliseconds for hundreds or thousands of items
Relevance tuning returns sponsored or preferred products higher up in the results set
Page rendering/pagination, which requires deterministic ordering
How retailers build search for product catalogs today
The way that developers in the retail industry build search today can be grouped into three buckets: simple database search, bolt-on search engine, and customized search.
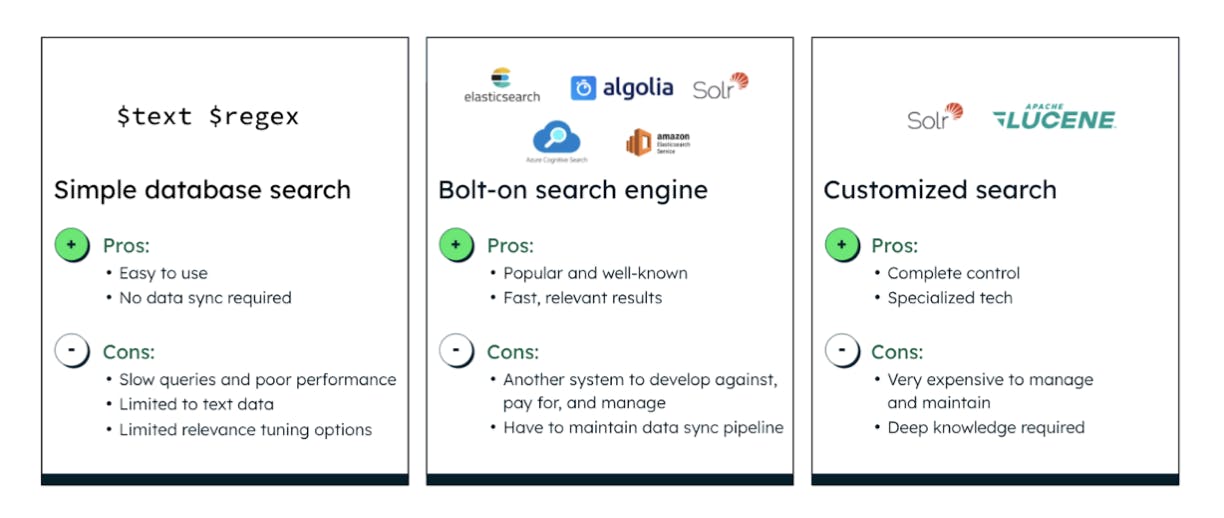
Simple database search: examples of this are the $text and $regex operators in MongoDB. They are easy to use and since they are common database commands, there’s no data sync required. On the flip side, they are often quite slow leading to poor performance, they are limited to just text data, and provide really no way to tune the relevance of results.
Bolt-on search engine: examples of this are Elasticsearch, Algolia, AWS OpenSearch Service, Azure Cognitive Search, and in some cases, Solr. These are popular and well-known search engines available on the market and generally provide fast, relevant results. However, they are yet another system to develop against, pay for, and manage, and require constantly syncing data to and from a database. We’ll dig more into the pains shortly.
Customized search: examples of this are Solr and Lucene. Now, Lucene is the open source technology that powers many of these solutions, including Elasticsearch, Solr, and our very own Atlas Search. And while it’s great for search and you can have complete control over what features to use, it’s incredibly expensive to manage and maintain yourself, and requires seasoned experts on the team to run successfully.
Think twice before bolting on a search engine to your database
Option two for building out search, the bolt-on method, can lead to major complexity and architectural sprawl in your ecommerce platform.
First, bolting on a search engine to your database results in lower developer productivity. When it comes to building search functionality, developers have to use different drivers and query languages to access their database and search clusters. The learning curve and need to switch context can lead to wasted developer hours.
Second, architectural complexity. Since the data that needs to be searched is stored in the database cluster, there must be mechanisms in place to sync that data to the separate search cluster. This involves scripts and processes to transform and structure the data into a format that the search cluster can index and query. And when the underlying schema changes in the database, developers have to spend time coordinating those changes between the two systems.
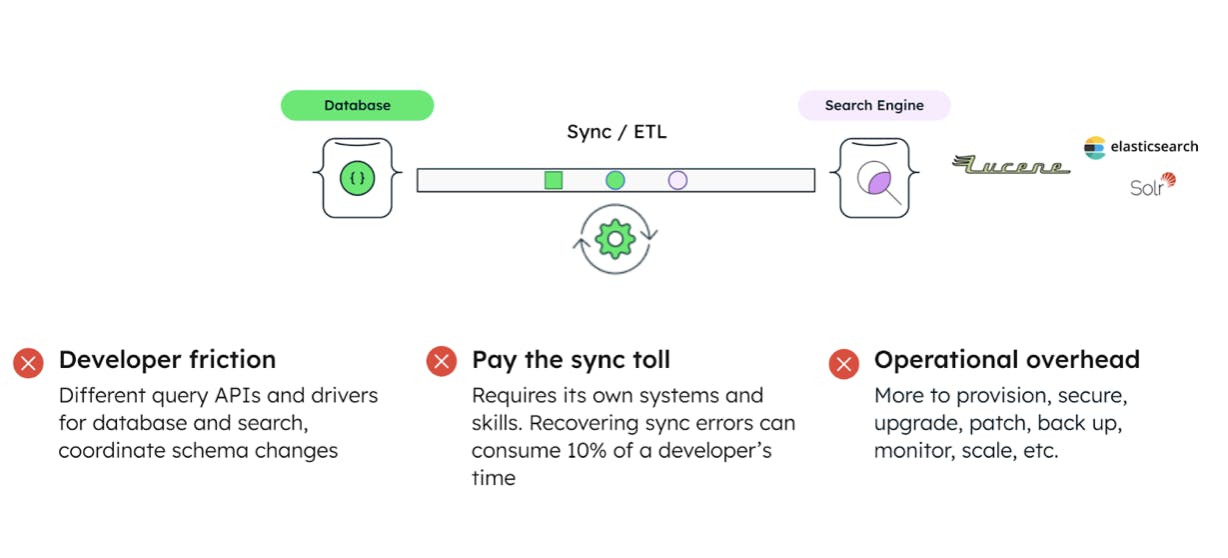
Finally, there’s operational overhead. Every icon in the diagram above requires its own infrastructure and support to ensure that it’s highly available, secure, backed up, using the latest software, scaled to meet changing demands, etc.
All of this costs time, people and money. Think about it. You have three separate systems for database, search, and sync — even in fairly small companies, there could be 3-4 employees just maintaining this small part of the application.
How MongoDB helps: MongoDB Atlas Search
The biggest challenge for our product catalog is enabling users to browse and discover products using natural language queries and giving results quickly, even if the user doesn’t know the name of the product, or spells it incorrectly. While many users will want to search our product catalog for a specific item or criteria they are looking for, many others will want to browse, then narrow the returned results by any number of attributes. So given the need to create a page like this:
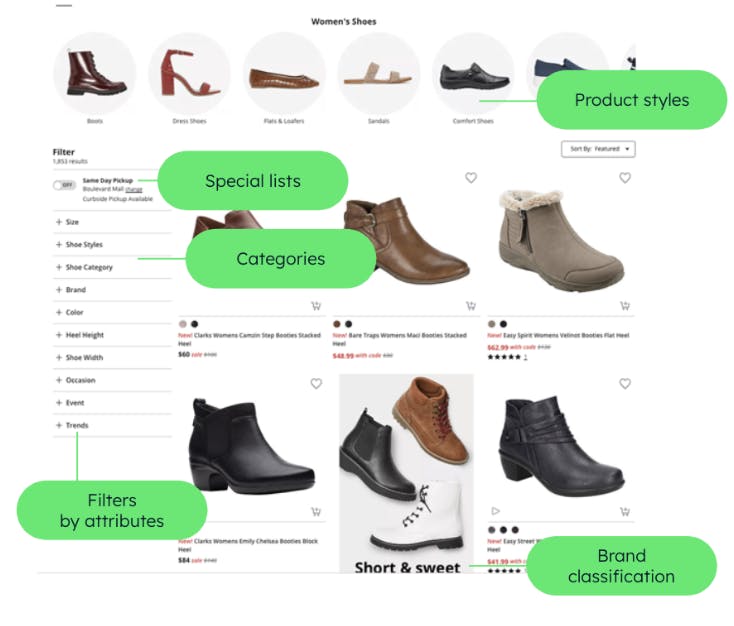
We have many challenges mentioned above: response time, multiple attributes, variant-level attributes, multiple variants, page sorting, pagination, and typos. Another challenge for retailers is controlling which products are surfaced first in search results. For example, a company may be running a promotional campaign, prioritizing its own brand or excess stock on clearance. All of these complexities fall under the umbrella of relevance tuning.
For catalog and content search, MongoDB’s document model handles a massive variability of catalog and content data. MongoDB Atlas provides real-time analytics capabilities with time series collections to capture clickstreams and conversions.
Atlas Search provides all of the features you need to deliver rich and personalized experiences to your users, including fuzzy matching; autocomplete; lightning fast facets and counts; highlighting; relevance scoring; geospatial queries; and synonyms, all backed by support for multiple analyzers and languages. These capabilities come together to help you boost user engagement and improve customer satisfaction with your applications – from product catalog and content search to powering complex, ad-hoc queries in your line-of-business applications.
Atlas Search is part of MongoDB Atlas, the multi-cloud application data platform that combines transactional processing, relevance-based search, real-time analytics, mobile edge computing with cloud sync, and cloud data lake in an elegant and integrated data architecture. Through a flexible document data model and unified query interface, Atlas provides a superior developer experience to power almost any class of application. At the same time it meets the most demanding requirements for resilience, scale, and data privacy.
Most importantly, its geo-distributed clusters provide a distributed architecture for resilience and low latency. This allows for auto-scale and sharding to handle promotional traffic spikes.
The benefits are immense: users can quickly find the most relevant matches using flexible search terms in any language and research and compare product and content categories. Your platform will be able to summarize product or content directly within the search results, and can boost preferred search results for promotions.
Learn more
Now that you have explored our e-commerce solutions for product catalogs and search, dive into our next post in the series: Approaches to inventory optimization.