When most people think about Amazon, they think of the cloud. But the company was founded more than a decade before anyone was talking about the cloud. In fact, by 2002, when Amazon founder Jeff Bezos wrote a now-famous internal email directing all new software development to be designed around service-oriented architecture, Amazon was already a $5 billion enterprise.
In 2017, Amazon was generating more than 50 times that annual revenue, and like many enterprise organizations, the core of that revenue was driven by the monolithic services that formed the backbone of the business.
Those monoliths didn’t go away overnight, and in 2017 and 2018, Amazon kicked off a massive RDBMS-to-NoSQL migration project called “Rolling Stone” to move about 10,000 RDBMS-backed microservices as well as decompose the remaining monoliths into microservices backed by NoSQL.
Amazon chose to use its own NoSQL database, but the lessons from that huge effort are valuable for any migration to a NoSQL or document database. In this article, I’ll share some of the insights gained about when and how to use NoSQL.
RDBMS costs
At the time of this migration, I ran the NoSQL Blackbelt Team for Amazon’s retail business, which was the center of excellence for the business and which developed most of the design patterns and best practices that Amazon uses to build NoSQL-backed application services today. In 2017, Amazon had more than 3,000 Oracle server instances, 10,000 application services and 25,000 global developers, and almost the entire development team was well versed in relational database technology. The cost of the IT infrastructure driving the business, however, was spiraling out of control.
As the team started to look for root causes, they quickly realized that the cost of the relational database management system (RDBMS) was a big line item. The infrastructure required to support RDBMS workloads was enormous and did not scale well to meet the needs of the company’s high-demand services.
Amazon had the biggest Oracle license and the largest RAC deployments in the world, and the cost and complexity of scaling services built on RDBMS was negatively affecting the business. As a result, we started looking at what we were actually doing in these databases. A couple of interesting things came out.
We found that 70% of the access patterns that we were running against the data involved a single row of data on a single table. Another 20% were on a range of rows on a single table. So, we weren’t running complex queries against the data at high velocity.
In fact, the vast majority were just inserts and updates, but many of those were executed “transactionally” across disparate systems using two-phase commits to ensure data consistency. Additionally, the cost was very high for the other 10% of the access patterns because most were complex queries requiring multiple table joins.
Technology triggers
While the team was looking into these issues, they also noticed a trend in the industry: Per core CPU performance was flattening, and the server processor industry was not investing enough in 5 nm fabrication technology to meet the efficiency increases described by Moore’s Law. This is one of the reasons why Amazon built its own processor.
If you look at the history of data processing, you’ll see a series of peaks and valleys in what can be defined as “data pressure,” or the ability of a system to process the required amount of data at a reasonable cost and within a reasonable amount of time.
When one of these dimensions is broken, it defines a “technology trigger” that signals the need to invent something. At Amazon, we saw that the cost efficiency of the relational database was declining while the TCO of high time-complexity queries was increasing as a result. Something had to change.
Relational data platforms only scale well vertically, which means getting a bigger box. Sooner or later, there is no bigger box, and the options to scale an RDBMS-backed system introduce either design complexity or time complexity. Sharding RDBMS systems is hard to self-manage.
And, although distributed SQL insulates users from that complexity by providing things like distributed cross commits behind the API to maintain consistency, that insulation also comes at a cost, which can be measured in the time complexity of the queries running across the distributed backend.
At the same time, the cost of storage was falling and the promise of denormalized, low time-complexity queries in NoSQL was enticing to say the least. Clearly, it was never going to get any cheaper to operate a relational database; it was only going to get more expensive.
Thus, Amazon made the decision to undertake what may be the largest technology migration ever attempted and deprecate RDBMS technology in favor of NoSQL for all Tier 1 services.
A new approach to building NoSQL skills
Project Rolling Stone launched with great fanfare and had buy-in from all the right stakeholders. But things didn’t go well at first. Amazon’s developers were now using a database designed to operate without the complex queries they had always relied on, and the lack of in-house NoSQL data modeling expertise was crippling the migration effort.
The teams lacked the skills needed to design efficient data models, so the early results from prototyped solutions were far worse than anticipated. To correct this situation, leadership created a center of excellence to define best practices and educate the broad Amazon technical organization; the NoSQL Blackbelt Team was formed under my leadership.
The challenge before us was enormous. We had limited resources with global scope across an organization of more than 25,000 technical team members. The traditional technical training approach built on workshops, brown bags and hackathons did not deliver the required results because the Amazon organization lacked a core nucleus of NoSQL skills to build on.
Additionally, traditional training tends to be sandboxed around canned problems that are often not representative of what the developers are actually working on. As a result, technical team members were completing those exercises without significant insight into how to use NoSQL for their specific use cases.
To correct this situation, we reworked the engagement model. Instead of running workshops and hackathons, we used the actual solutions the teams were working on as the learning exercises.
The Blackbelt Team executed a series of focused engagements across Amazon development centers, where we delivered technical brown bag sessions to advocate best practices and design patterns. Instead of running canned workshops, however, we scheduled individual design reviews with teams to discuss their specific workloads and prototype a data model they could then iterate on.
The result was powerful. Teams gained actionable information they could build on, rather than general knowledge that might or might not be relevant to their use case. During the next three years, Amazon migrated all Tier 1 RDBMS workloads to NoSQL and reduced the infrastructure required to support those services by more than 50%, while still maintaining a high business growth rate.
Watch Rick Houlihan’s full MongoDB World 2022 presentation, “From RDBMS to NoSQL at Enterprise Scale.”
When to use NoSQL - Looking at Access Patterns
When should you use NoSQL? I had to answer this question many times at Amazon, and the answer isn’t so clear-cut. A relational database is agnostic to the access pattern. It doesn’t care what questions you ask. You don’t have to know code, although some people would argue that SQL is code. You can theoretically ask a simple question and get your data. Relational systems do that by being agnostic to every access pattern and by optimizing for none of them.
The reality is that the code we write never asks random questions. When you write code, you’re doing it to automate a process — to run the same query a billion times a day, not to run a thousand random queries.
Thus, if you understand the access patterns, you can start doing things with the data to create structures that are much easier for systems to retrieve while doing less work. This is the key. The only way to reduce the cost of data processing and the amount of infrastructure deployed is to do less work.
OLTP (online transaction processing) applications are really the sweet spot for NoSQL databases. You’ll see the most cost efficiency here because you can create data models that mirror your access patterns and representative data structures that mirror your objects in the application layer.
The idea is to deliver a system that is very fast at the high-velocity access patterns that make up the majority of your workload. I talk more about data access patterns and data modeling at a recent Ask Me Anything.
Making It All Work
There’s a saying that goes, “Data is like garbage. You better know what you are going to do with it before you collect it.” This is where relationships come into play. Nonrelational data, to me, does not exist. I’ve worked with more than a thousand customers and workloads, and I’ve never seen an example of nonrelational data. When I query data, relationships become defined by the conditions of my query. Every piece of data we’re working with has some sort of structure. It has schema, and it has relationships; otherwise, we wouldn’t care about it.
No matter what application you’re building, you’re going to need some kind of entity relationship diagram (ERD) that describes your logical data diagram, entities and how they’re related to understand how to model it. Otherwise, you’re just throwing a bunch of bytes in a bucket and randomly selecting things.
A relationship always exists between these things. In relational models, they’re typically modeled in third normal form (3NF). For example, in a typical product catalog, you’ll see one-to-one relationships between products and books, products and albums, products and videos, one-to-many relationships between albums and tracks, and many-to-many relationships between videos and actors.
This is a pretty simple ERD — we’re not even talking about any complex patterns. But suppose you want to get a list of all your products, you’d have to run three different queries and various levels of joins. That’s a lot of things going on.
In a NoSQL database, you’re going to take all those rows and collapse them into objects. If you think about the primary access pattern of this workload, it’s going to be something like, “Get me the product by this ID,” or “Get me all the titles under this category.” Whenever you want the product, you typically want all the data for the product because you’re going to use it in a product window. If you put it all in one document, you no longer have to join those documents or rows. You can just fetch the data by product ID.
If you think about what’s happening from a time-complexity perspective, when you have all that data in tables, your one-to-one joins won’t be so bad, but with a one-to-many, the time complexity starts expanding.
Again, the examples mentioned here are fairly simple. When you start getting into nested joins, outer and inner, and other more complex SQL statements, you can imagine how much worse the time complexity becomes. That’s your CPU burning away, assembling data across tables. If you’re running a relational data model and you’re joining tables, that’s a problem.
Index and conquer
Let’s think about how we model those joins in NoSQL. To start, we have a key-value lookup on a product. But we can also create an array of embedded documents called “target” that contains all the things the product is related to, as shown in Figure 1. It contains metadata and anything about the product you need when you query by product ID. Now that we’re using embedded documents, there’s no more time complexity. It’s all an index lookup. It can be one-to-one, one-to-many, many-to-many — it doesn’t matter. As long as the aim is “get the document,” it’s still an index lookup.
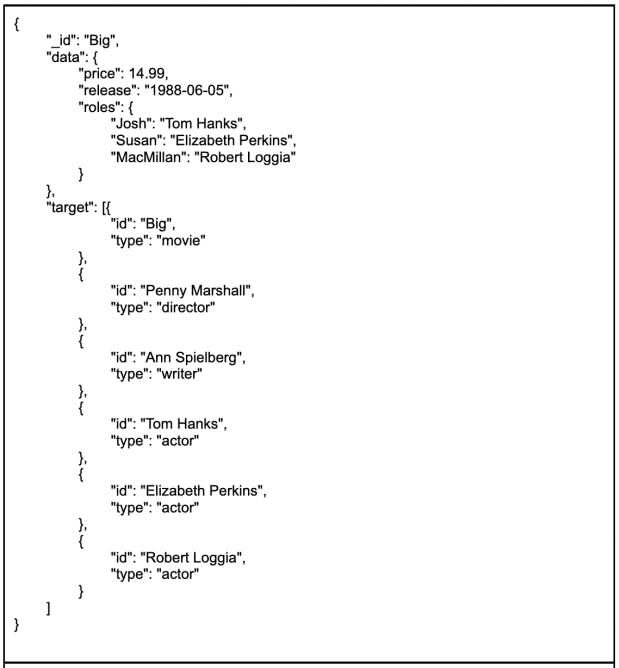
Of course, a lot more goes into an application than an index lookup. Remember, 70% of our access patterns at Amazon were for a single row of data, and 20% were for a range of rows on a single table. For more complex access patterns, we’re going to need more dimensions.
If, for example, we’re running a query for all the books by a given author or all people related to “x,” this will require adding more dimensions, or documents, to the collection. We can create documents for other actors who were in a collection of movies, directors of all the movies, songs from the movies, how these songs relate to other entities in this collection, writers, producers, artists who performed the songs and all the albums those songs appeared on, as shown in Figure 2.

Now, if I index the “target” array — which is one of the best things about MongoDB and document databases, multikey arrays — I can create essentially a B-tree lookup structure of those “target” IDs and join all those documents and all of those dimensions, as shown in Figure 3. Now I can select, for example, where target ID is Mary Shelley and get everything she’s related to — the books, people, critiques of her work. Where the target ID is a song title, I can get all the information about that song.
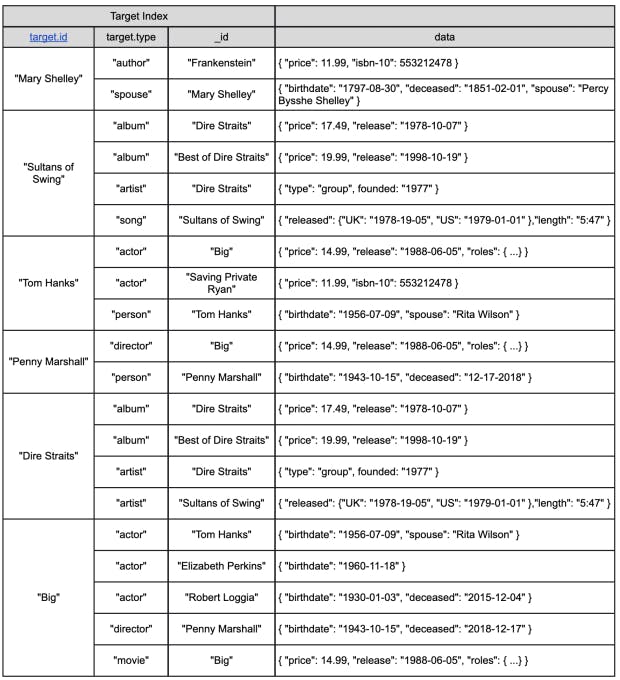
Essentially, we’re using the index as a join mechanism, which is a critical distinction in NoSQL. At AWS, many teams came to me and told me that NoSQL doesn’t work. The key thing to understand, however, is if you index documents that are stored in the same table or collection on a common dimension that has the same value, you’ve essentially eliminated the need to join that same index across that same value and across multiple tables.
That’s what the relational database does. You don’t want to join unindexed columns in a relational database because it will incur a lot of overhead. You want to index those attributes and put pointers to parent objects and child tables and then join on those IDs. With NoSQL, we’re essentially placing all those items in a single table and indexing on the ID. This approach also eliminates the time complexity. If all those documents share a common table, and they’re indexed on a common attribute, the time complexity is 0(log(N)).
Seventy percent of the overhead of handling a request from a database is not getting the data. It’s managing the connection, marshaling the data and moving it back and forth across the TCP/IP stack. So, if I can eliminate one request from a transaction, I’m going to reduce the overhead of that transaction.
Conclusion
Data that is accessed together should be stored together. That is the mantra that we’ve always espoused at MongoDB. Once we started learning how to use NoSQL at Amazon, we started having better results. We did that through regularly scheduled training sessions where we could teach the fundamentals of NoSQL using our own workloads. That’s what my developer advocacy team at MongoDB does now with customers. We provide templates for how to model data for their workloads to help them do it themselves.