MongoDB has a long history of advocating for simplicity and focusing on making developers more agile and productive. MongoDB first disrupted the database market with the document model, storing data records as BSON (binary representation of JSON documents). This approach to working with data enables developers to easily store and query their data as they use it naturally within their applications. As your data changes, you simply add an attribute to your documents and move on to the next ticket. There is no need to waste time altering tables and constraints when the needs of your application change.
MongoDB is always on the lookout for more ways to make life easier for developers, such as addressing the challenges of working with streaming data. With streaming data, it may take armies of highly skilled operational personnel to build and maintain a production-ready platform (like Apache Kafka). Developers then have to integrate their applications with these streaming data platforms resulting in complex application architectures.
It’s exciting to see technologies like Redpanda seeking to improve developer productivity for working with streaming data. For those unfamiliar with Redpanda, it is a Kafka API compatible streaming platform that works with the entire Kafka ecosystem, such as Kafka-Connect and popular Kafka drivers: librdkafka, kafka-python, and the Apache Kafka Java Client. Redpanda is written in C++ and leverages the RAFT protocol, which makes Apache ZooKeeper irrelevant. Also, its thread-per-core architecture and JVM-free implementation enable performance improvements over other data streaming platforms. On a side note, MongoDB also implements a protocol similar to RAFT for its replica set cluster primary and secondary elections and management.
Both MongoDB and Redpanda share a common goal of simplicity and making complex tasks trivial for the developer. So we decided to show you how to pull together a simple streaming application using both technologies.
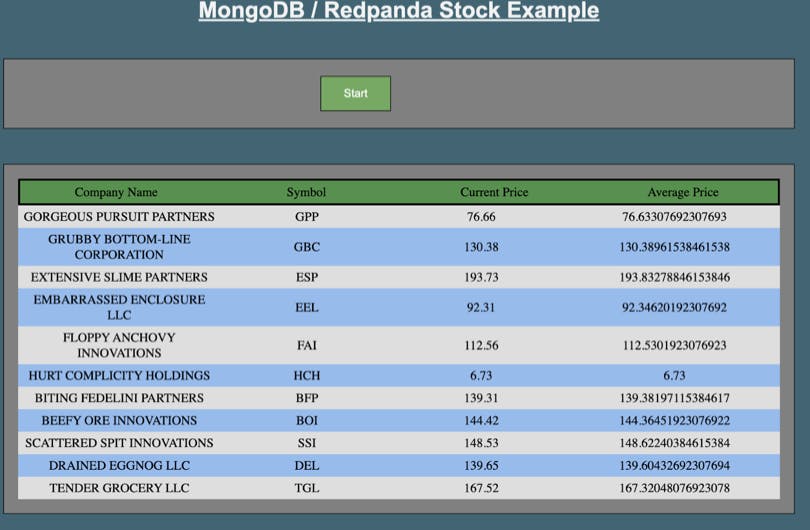
The example application (found in this GitHub repository) considers the scenario where stock ticker data is written to a Redpanda and consumed by MongoDB. Once you have the example running, a “stock generator” creates a list of 10 fictitious companies and starts writing ticker data to a Redpanda topic. Kafka Connect service listens for data coming into this topic and “sinks” the data to the MongoDB cluster. Once landed in MongoDB, the application issues an aggregation query to determine the moving averages of the stock securities and updates the UI. MongoDB consumes the ticker data and calculates the average stock price trends using the aggregation framework.
Once you have downloaded the repository, a docker-compose script includes a Node server, Redpanda deployment, Kafka Connect service, and a MongoDB instance. The Kafka Connect image includes the Dockerfile-MongoConnect file to install the MongoDB Connector for Apache Kafka. The Dockerfile-Nodesvr is included in the nodesvr image and it copies the web app code & installs the necessary files via NPM.
There is a run.sh script file that will launch the docker-compose script to launch the containers. To start the demo, simply run this script file via sh run.sh and upon success, you will see a list of the servers and their ports:
Once started, navigate to localhost:4000 in a browser and click the “Start” button. After a few seconds, you will see the sample stock data from 10 fictitious companies with the moving average price.
Get started with MongoDB and Redpanda
This example showcases the simplicity of moving data through the Redpanda streaming platform and into MongoDB for processing. Check out these resources to learn more:
Introduction to Redpanda
MongoDB + Redpanda Example Application GitHub repository
Learn more about the MongoDB Connector for Apache Kafka
Ask questions on the MongoDB Developer Community forums
Sign up for MongoDB Atlas to get your free tier cluster