Multiplexing Golang Channels to Maximize Throughput
May 26, 2016 | Updated: September 26, 2025
The Go language is great for concurrency, but when you have to do work that is naturally serial, must you forgo those benefits? We faced this question while rewriting our database backup utility, mongodump, and utilized a “divide-and-multiplex” method to marry a high-throughput concurrent workload with a serial output.
The need for concurrency
In MongoDB, data is organized into collections of documents. When reading from a collection, requests are often preempted, when other processes obtain a write lock in that collection. To prevent stalls from reducing overall throughput, you can enqueue reads from multiple collections at once. Thus, a previous version of mongodump concurrently read data across collections, to achieve maximum throughput.
However, since the old mongodump wrote each collection to a separate file, it did not work for two very common use cases for database backup utilities: 1) streaming the backup over a network, and 2) streaming the backup directly into another instance as part of a load operation. Our new version was designed to support these use cases.
To do that, while preserving the throughput-maximizing properties of concurrent reads, we leveraged some Golang constructs -- including reflection and channels -- to safely permit multiple goroutines to concurrently feed data into the archive. Let me show you how.
The archive format
The new mongodump archive consists of two sections: the prelude and the body. The prelude records the number of collections backed up, and other metadata. In the body, we interleave slices of data from the collections. Each collection's last slice is a special "EOF" slice. Let’s get a bird’s eye view of the archive layout:
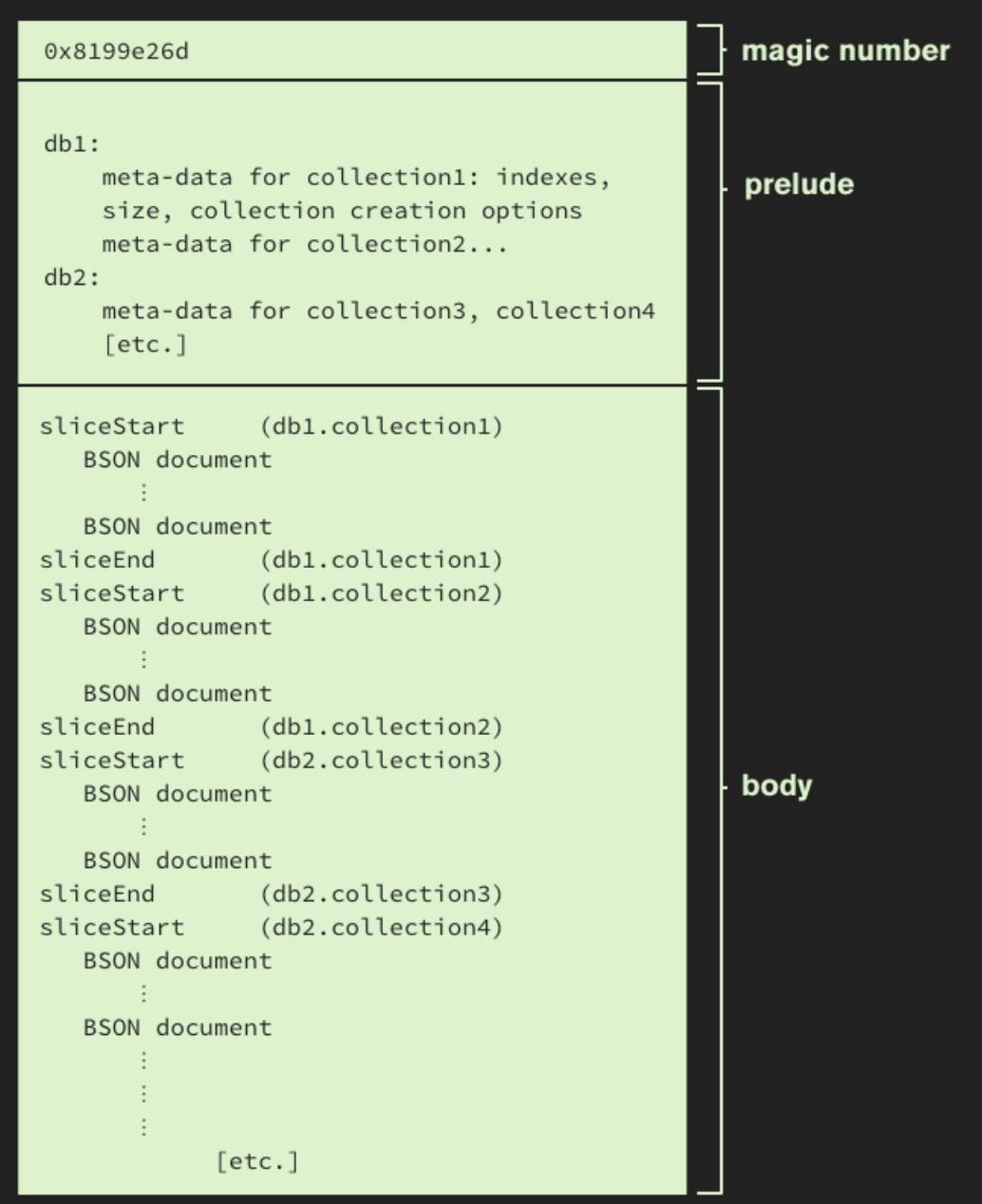
Because this format supports interleaving slices of collection data, we can concurrently back up multiple databases and collections to a single file, allowing users to easily compress archives, or pipe mongodump through ssh to mongorestore on another server. But how does this layout bridge the serial/concurrent chasm?
Writing to an archive
In our new mongodump, we implement concurrent reading with a fixed, user-specified number of goroutines. Suppose our MongoDB server has two databases, db1 and db2, that we want to back up. Let's tell mongodump to use two goroutines, by passing -j2:
mongodump -j2 --archive=backup.archive --host mongod.example.com
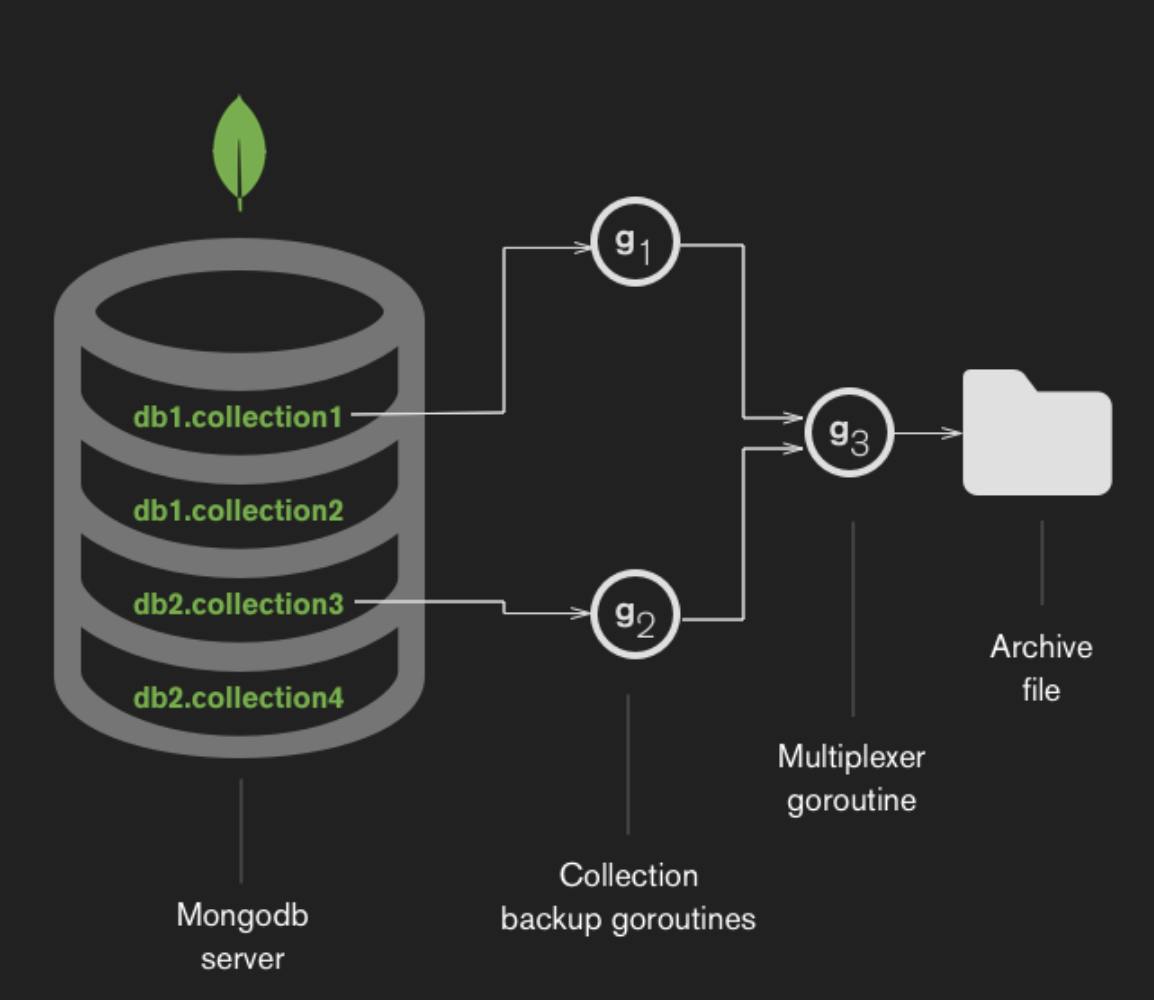
The diagram shows how mongodump allocates goroutines. Each goroutine gets pegged to a particular collection to read data from (collection1, collection2, etc above) and serves as an input source to the multiplexer. These two goroutines are used as arguments to Golang’s Select function. Here’s its function signature:
func Select(cases []SelectCase) (chosen int, recv Value, recvOK bool)
Each SelectCase maps to one of the multiplexer’s input sources. recv holds a BSON document received from an input source. recvOK is true until all data from that input source has been completely received, then a recvOK of false signals completion.
To tie this all together, we introduce a special control SelectCase to signal one of two states. The first state is when the goroutine associated with a particular collection begins working on a new collection. The second state is when the all input sources have been completely read. Select is the core of our design to bridge the chasm between the archive's serial nature and mongodump’s concurrency.
Here’s how the multiplexer is created:
func NewMultiplexer(out io.WriteCloser) *Multiplexer {
controlInput := make(chan *MuxIn)
multiplexer := &Multiplexer {
control: controlInput,
selectCases: []reflect.SelectCase {
reflect.SelectCase {
Dir: reflect.SelectRecv,
Chan: reflect.ValueOf(controlInput),
Send: reflect.Value{},
},
}
return multiplexer
}
And here’s how we use it:
// Run multiplexer until it receives an EOF on the control channel.
func (mux *Multiplexer) Run() {
for {
index, value, recv := reflect.Select(mux.selectCases)
EOF := !recv
// note that the control channel is always at index 0
if index == 0 {
if EOF {
return
}
muxInput, _ := value.Interface().(*muxInputSource)
mux.selectCases = append(mux.selectCases, reflect.SelectCase{
Dir: reflect.SelectRecv,
Chan: reflect.ValueOf(muxInput.collection),
Send: reflect.Value{},
})
} else {
if EOF {
mux.writeEOF()
mux.selectCases = append(mux.selectCases[:index], mux.selectCases[index+1:]...)
} else {
document, _ := value.Interface().([]byte)
mux.writeDocument(document)[]
}
}
}
}
The main goroutine creates the multiplexer and calls go Run() on it. In our example, we have two goroutines each reading data from a distinct collection. The Select function blocks until at least one of the goroutines is ready to send data. Then, we read the reflect value (a BSON document) off that goroutine’s channel and write the document to the archive file (lines 22-23). This process continues for each collection until it is completely read. But what do we do when we’ve finished backing up data from one collection, or finished backing up all the data? This is where the control channel comes in.
First, we consider how to reassign a goroutine once it has completely read all data from a collection. When a goroutine begins reading data from a new collection, it signals this to the multiplexer by sending a signal on the control channel. This causes the multiplexer to register the new collection in the select cases it chooses from (lines 12-16). Once the goroutine for that collection has completely read all the data, it sends an EOF which removes it from the multiplexer’s select cases (line 20). Then the goroutine reading that collection gets reassigned to the next collection, so all goroutines are kept busy until all collections have been backed up. (The Select function makes a copy of all the select cases before selecting, so we can safely update the select cases that comprise the multiplexer's inputs while the multiplexer is running.)
How does the multiplexer know when to stop? After the main mongodump process invokes go Run(), it waits for the backup goroutines to completely back up all the collections. Once these goroutines finish, the main mongodump process closes the control channel, and multiplexer goroutine knows it's done.
Reading from an archive
Reading from a mongodump archive file is straightforward. Once we’ve parsed the prelude, we know all collections to expect during the restore operation. In the body, we simply read each sliceStart we encounter, and assign a goroutine to insert all documents for that collection into the appropriate collection. Each available goroutine is assigned to a unique collection so that, the same as backing up, we restore collections concurrently.
By the way -- that curious magic number at the beginning of the archive -- 0x8199e26d (-2120621459)? The first byte, 6d, is the hex representation of the ASCII character ’m’. The remaining three bytes represent the earth symbol, ’♁’. Together, they form ’m♁’. So it's an allusion to how well suited MongoDB is to handling humongous data. But there's another reason we chose it. The first four bytes of a BSON document is the document's length as a signed integer. The magic number was specifically chosen because it's invalid as the start of a BSON document (since it’s negative).
The tool we designed to back up MongoDB collections to a single archive file is straightforward and easy to understand. Using a tidy file format and Golang's powerful concurrency, our new backup and restore tools are faster, simpler, and more featureful than before the rewrite.