MongoDB is excited to announce the launch of the Atlas Flex tier. This new offering is designed to help developers and teams navigate the complexities of variable workloads while growing their apps.
Modern development environments demand database solutions that can dynamically scale without surprise costs, and the Atlas Flex tier is an ideal option offering elasticity and predictable pricing. Previously, developers could either pick the predictable pricing of a shared tier cluster or the elasticity of a serverless instance. Atlas Flex tier combines the best features of the Shared and Serverless tiers and replaces them, providing an easier choice for developers. This enables teams to focus on innovation rather than database management.
This new tier underscores MongoDB’s commitment to empowering developers through an intuitive and customer-friendly platform. It simplifies cluster provisioning on MongoDB Atlas, providing a unified, simple path from idea to production. With the ever-increasing complexity of application development, it’s imperative that a database evolve alongside the project it supports. Whether prototyping a new app or managing dynamic production environments, MongoDB Atlas provides comprehensive support. And, by seamlessly combining scalability and affordability, the Atlas Flex tier reduces friction as requirements expand.
Bridging the gap between flexibility and predictability: What the Atlas Flex tier offers developers
Database solutions that can adapt to fluctuating workloads without incurring unexpected costs are becoming a must-have for every organization. While traditional serverless models offer flexibility, they can result in unpredictable expenses due to unoptimized queries or unanticipated traffic surges.
The Atlas Flex tier bridges this gap and empowers developers with:
Flexibility: 100 ops/sec and 5 GB of storage are included by default, as is dynamic scaling of up to 500 ops/sec.
Predictable pricing: Customers will be billed an $8 base fee and additional fees based on usage. And pricing is capped at $30 per month. This prevents runaway costs—a persistent challenge with serverless architectures.
Data services: Customers can access various features such as MongoDB Atlas Search, MongoDB Atlas Vector Search, Change Streams, MongoDB Atlas Triggers, and more. This delivers a comprehensive solution for development and test environments.
Seamless migration: Atlas Flex tier customers can transition to dedicated clusters when needed via the MongoDB Atlas UI or using the Admin API.
The Atlas Flex tier marks a significant step forward in streamlining database management and enhancing its adaptability to the needs of modern software development. The Atlas Flex tier provides unmatched flexibility and reliability for managing high-variance traffic and testing new features.
Building a unified on-ramp: From exploration to production
MongoDB Atlas enables a seamless progression for developers at every stage of application development. With three distinct tiers—Free, Flex, and Dedicated—MongoDB Atlas encourages developers to explore, build, and scale their applications:
Atlas Free tier: Perfect for experimenting with MongoDB and building small applications at no initial cost, this tier remains free forever.
Atlas Flex tier: Bridging the gap between exploration and production, this tier offers scalable, cost-predictable solutions for growing workloads.
Atlas Dedicated tier: Designed for high-performance, production-ready applications with built-in automated performance optimization, this tier lets you scale applications confidently with MongoDB Atlas’s robust observability, security, and management capabilities.
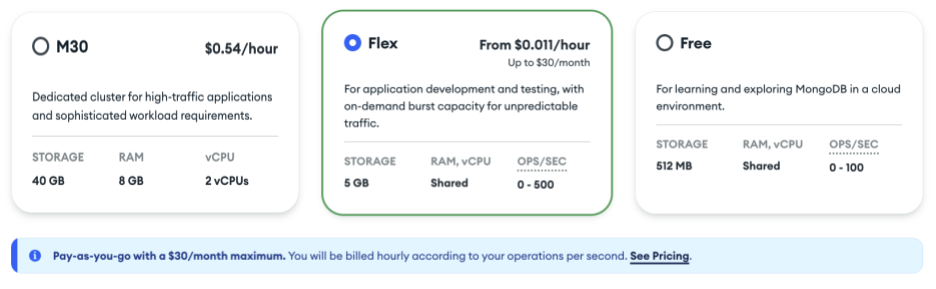
This tiered approach gives developers a unified platform for their entire journey. It ensures smooth transitions as projects evolve from prototypes to enterprise-grade applications. At MongoDB, our focus has always been on removing obstacles for innovators, and this simple scaling path empowers developers to focus on innovation rather than navigating infrastructure challenges.
Supporting startups with unpredictable traffic
When startups launch applications with uncertain user adoption rates, they often face scalability and cost challenges. But the Atlas Flex tier addresses these issues!
For example, startups can begin building apps with minimal upfront costs. The Atlas Flex tier enables them to scale effortlessly to accommodate traffic spikes, with support for up to 500 operations per second whenever required. And as user activity stabilizes and grows, migrating to dedicated clusters is a breeze.
MongoDB Atlas removes the stress of managing infrastructure. It enables startups to focus on building exceptional user experiences and achieving product-market fit.
Accelerating MVPs for gen AI applications
The Atlas Flex tier is particularly suitable for minimum viable products in generative AI applications. Indeed, those incorporating vector search capabilities are perfect use cases.
For example, imagine a small research team specializing in AI. It has developed a prototype that employs MongoDB Atlas Vector Search for the management of embeddings in the domain of natural language processing. The initial workloads remain under 100 ops/sec. As such, the overhead costs $8 per month. As the model is subjected to comprehensive testing and as demand for queries increases, the application can be seamlessly scaled while performance is uninterrupted. Given the top-end cap of $30 per month, developers can refine the application without concerns for infrastructure scalability or unforeseen expenses.
The table below shows how monthly Atlas Flex tier pricing breaks down by capacity.
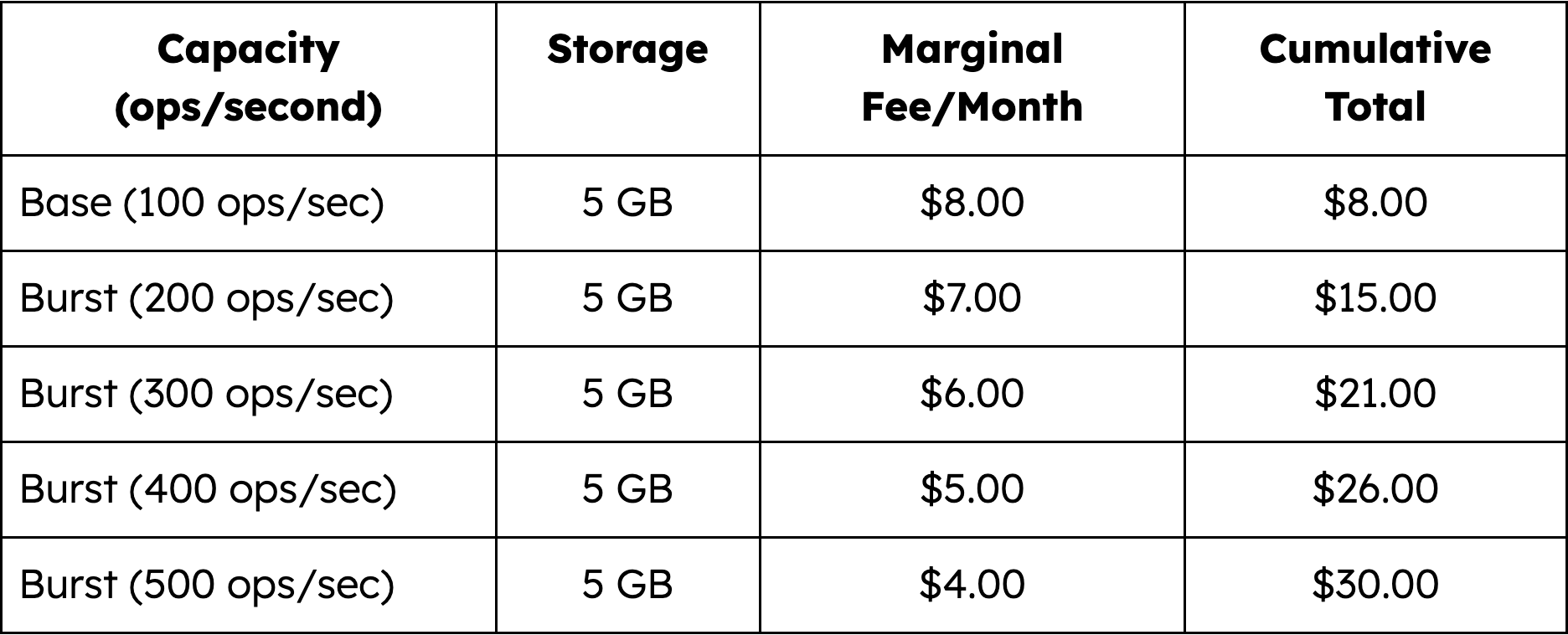
The monthly fee for each level of usage is prorated and billed on an hourly basis. All clusters on MongoDB Atlas, including Atlas Flex tier clusters, are pay-as-you-go. Clusters are only charged for as long as they remain active. For example, a workload that requires 100 ops/sec for 20 days, 250 ops/sec for 5 days, and 500 ops/sec for 5 days would cost approximately $13.67. If the cluster was deleted after the first 20 days of usage, the cost would be approximately $5.28.
This straightforward and transparent pricing model ensures developers can plan budgets with confidence while accessing world-class database capabilities.
Get started today
The Atlas Flex tier revolutionizes database management. It caters to projects at all stages—from prototypes to production. Additionally, it delivers cost stability, enhanced scalability, and access to MongoDB’s robust developer tools in a single seamless solution.
With Atlas Flex tier, developers gain the freedom to innovate without constraints, confident that their database can handle any demand their applications generate. Whether testing groundbreaking ideas or scaling for a product launch, this tier provides comprehensive support.
Learn more or get started with Atlas Flex tier today to elevate application development to the next level.