We’re excited to announce analytics node tiers for MongoDB Atlas. Analytics node tiers provide greater control and flexibility by allowing you to customize the exact infrastructure you need for your analytics workloads.
Analytics node tiers provide control and flexibility
Until now, analytics nodes in MongoDB’s Atlas clusters have used the same cluster tier as all other nodes. However, operational and analytical workloads can vary greatly in terms of resource requirements. Analytics node tiers allow you to enhance the performance of your analytics workloads by choosing the best tier size for your needs. This means you can choose an analytics node tier larger or smaller than the operational nodes in your cluster. This added level of customization ensures you achieve the performance required for both transactional and analytical queries — without the need to over- or under-provision your entire cluster for the sake of the analytical workload. Analytics node tiers are available in both Atlas and Atlas for Government.
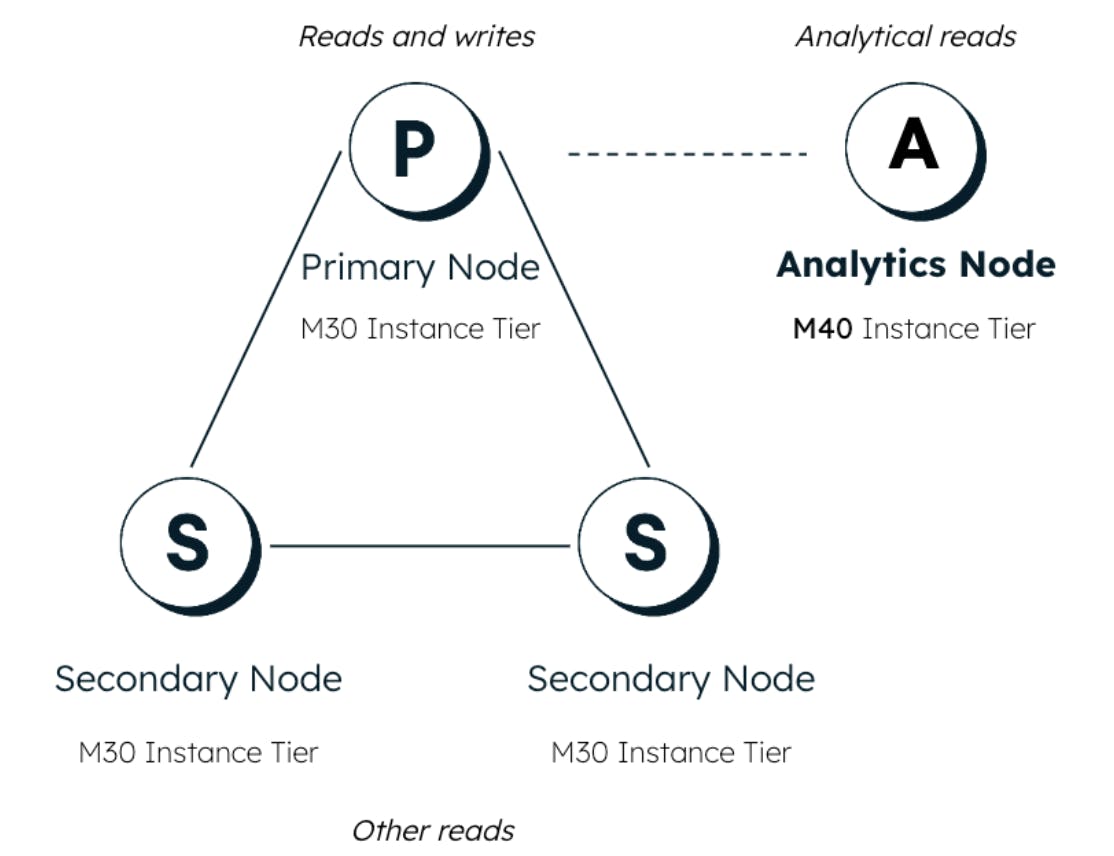
Choose a higher or lower analytics node tier based on your analytics needs
Teams with large user bases using their BI dashboards may want to increase their analytics node tiers above that of their operational nodes. Choosing a higher tier can be useful when you have many users or require more memory to serve analytics needs. Scaling up the entire cluster tier would be costly, but scaling up just your analytics node tiers helps optimize the cost.
Teams with inconsistent needs may want to decrease their analytics node tier below that of their operational nodes. The ability to set a lower tier gives you flexibility and cost savings when you have fewer users or analytics are not your top priority.
With analytics node tiers, you get more discretion and control over how you manage your analytics workloads by choosing the appropriately sized tier for your analytics needs.
Get started today by setting up a new cluster or adding an analytics node tier to any existing cluster. Check out our documentation to learn more.