It is hardly headline news that large language models can be unreliable. For some use cases, this can be inconvenient. For others — especially in regulated industries — the consequences are way more severe. Enter Patronus AI, the industry-first automated evaluation platform for LLMs.
Founded by machine learning experts from Meta AI and Meta Reality Labs, Patronus AI is on a mission to boost enterprise confidence in gen AI-powered apps, leading the way in shaping a trustworthy AI landscape.
Check out our AI Learning Hub to learn more about building AI-powered apps with MongoDB.
Rebecca Qian, Patronus co-founder and CTO explains, “Our platform enables engineers to score and benchmark LLM performance on real-world scenarios, generate adversarial test cases, monitor hallucinations, and detect PII and other unexpected and unsafe behavior. Customers use Patronus AI to detect LLM mistakes at scale and deploy AI products safely and confidently.”
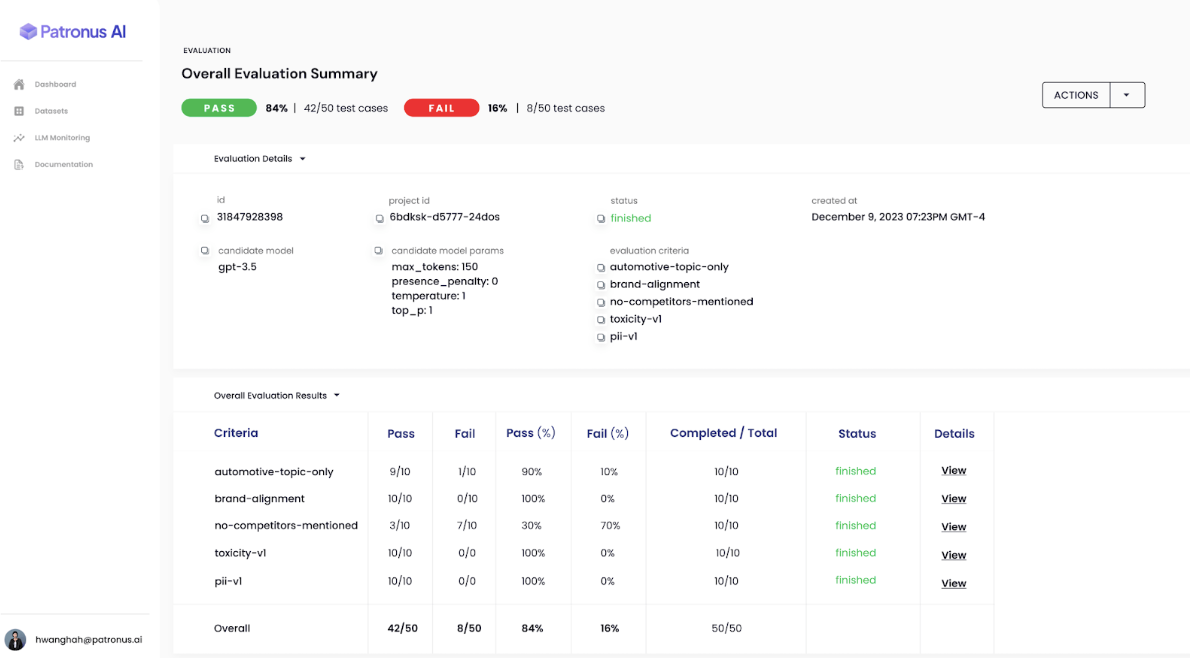
In recently published and widely cited research based on the FinanceBench question answering (QA) evaluation suite, Patronus made a startling discovery. Researchers found that a range of widely used state-of-the-art LLMs frequently hallucinated, incorrectly answering or refusing to answer up to 81% of financial analysts’ questions! This error rate occurred despite the models’ context windows being augmented with context retrieved from an external vector store.
While retrieval augmented generation (RAG) is a common way of feeding models with up-to-date, domain-specific context, a key question faced by app owners is how to test the reliability of model outputs in a scalable way. This is where Patronus comes in. The company has partnered with the leading technologies in the gen AI ecosystem — from model providers and frameworks to vector store and RAG solutions — to provide managed evaluation services, test suites, and adversarial data sets.
“As we assessed the landscape to prioritize which partners to work with, we saw massive demand from our customers for MongoDB Atlas," said Qian. “Through our Patronus RAG evaluation API, we help customers verify that their RAG systems built on top of MongoDB Atlas consistently deliver top-tier, dependable information."
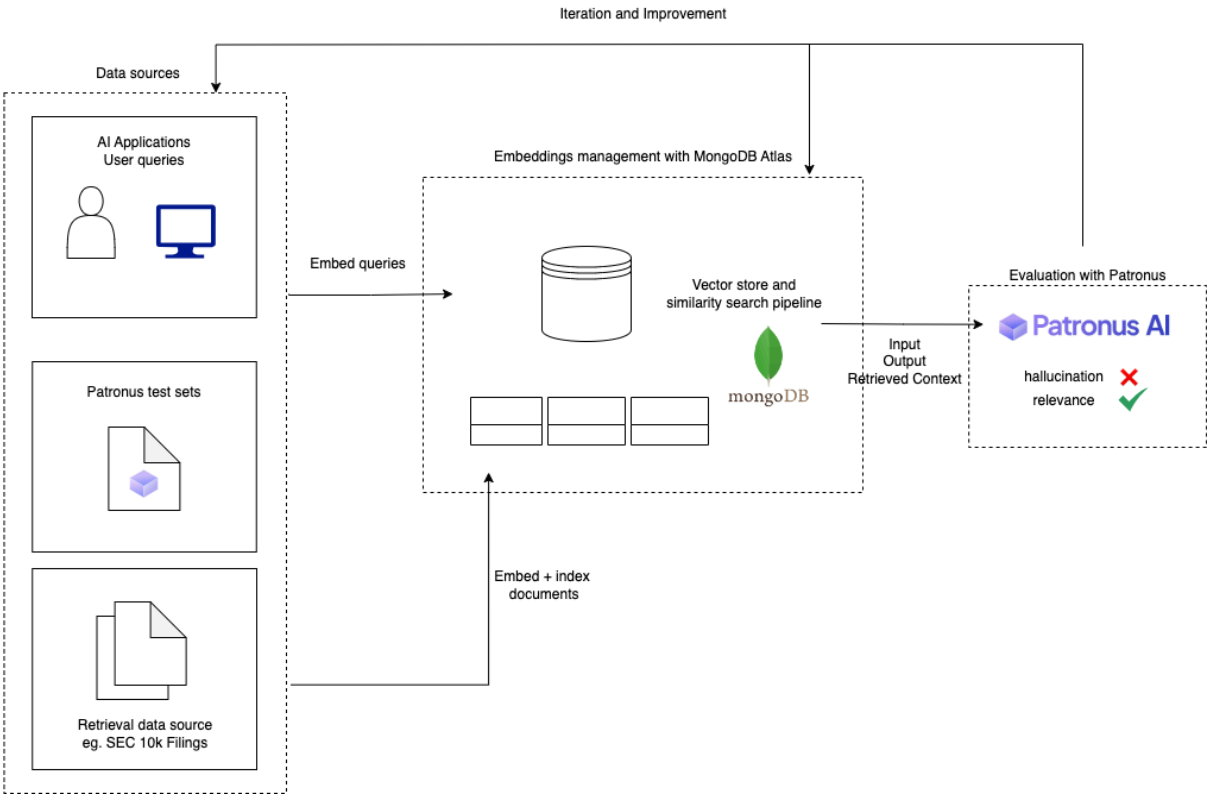
In its new 10-minute guide, Patronus takes developers through a workflow showcasing how to evaluate a MongoDB Atlas-based retrieval system. The guide focuses on evaluating hallucination and answers relevance against an SEC 10-K filing, simulating a financial analyst querying the document for analysis and insights. The workflow is built using:
The LlamaIndex data framework to ingest and chunk the source pdf document
Atlas Vector Search to store, index, and query the chunk’s metadata and embeddings
Patronus to score the model responses
The workflow is shown in the figure below.
Equipped with the results of an analysis, there are a number of steps developers can take to improve the performance of a RAG system. These include exploring different indexes, modifying document chunking sizes, re-engineering prompts, and for the most domain-specific apps, fine-tuning the embedding model itself. Review the 10-minute guide for a more detailed explanation of each of these steps.
As Qian goes on to say, “Regardless of which approach you take to debug and fix hallucinations, it’s always important to continuously test your RAG system to make sure performance improvements are maintained over time. Of course, you can use the Patronus API iteratively to confirm.” To learn more about LLM evaluation, contact the Patronus team.
Head over to our quick-start guide to get started with Atlas Vector Search today.