Founded by the former leaders of AI teams at Google, Netflix, and Splunk, Gradient enables businesses to create high-performing, cost-effective custom AI applications.
Gradient provides a platform for businesses to build, customize, and deploy bespoke AI solutions — starting with the fastest way to develop AI through the use of its Accelerator Blocks.
Gradient’s Accelerator Blocks are comprehensive, fully managed building blocks designed for AI use cases — reducing developer workload and helping businesses achieve their goals in a fraction of the time. Each block can be used as is (e.g. entity extraction, document summarization, etc.) or combined to create more robust and intricate solutions (e.g. investment co-pilots, customer chatbots, etc.) that are low-code, use best-of-breed technologies, and provide state-of-the-art performance.
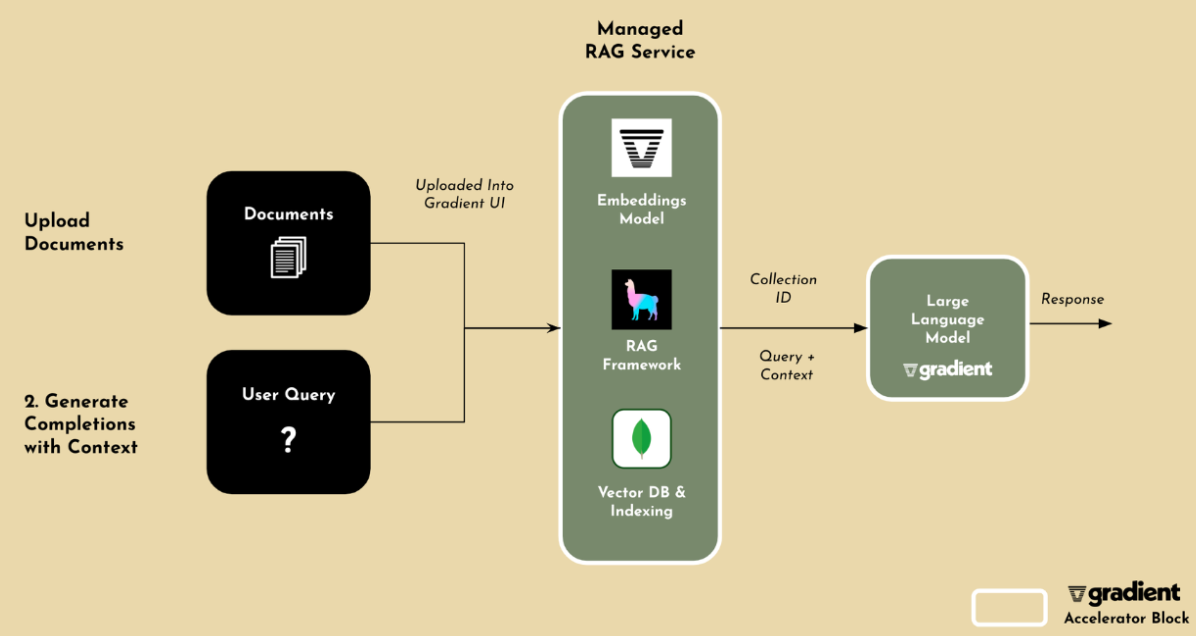
Gradient’s newest Accelerator Block focuses on enhancing the performance and accuracy of a model through retrieval augmented generation (RAG). The Accelerator Block uses Gradient’s state-of-the-art LLMs and embeddings, MongoDB Atlas Vector Search for storing, indexing, and retrieving high-dimensional vector data, and LlamaIndex for data integration.
Together, Atlas Vector Search and LlamaIndex feed foundation models with up-to-date, proprietary enterprise data in real-time. Gradient designed the Accelerator Block for RAG to improve development velocity up to 10x by removing the need for infrastructure, setup, or in-depth knowledge around retrieval architectures. It also incorporates best practices in document chunking, re-rankers, and advanced retrieval strategies.
As Tiffany Peng, VP of Engineering from Gradient explains, “Users who are looking to build custom AI applications can leverage Gradient’s Accelerator Block for RAG to set up RAG in seconds. Users just have to upload their data into our UI and Gradient will take care of the rest. That way users can leverage all of the benefits of RAG, without having to write any code or worry about the setup.”
Peng goes on to say:
“With MongoDB, developers can store data of any structure and then expose that data to OLTP, text search, and vector search processing using a single query API and driver. With this unification, developers have all of the core data services they need to build AI-powered apps that rely on working with live, operational data. For example, querying across keyword and vector search applications can filter on metadata and fuse result sets to quickly identify and return the exact context the model needs to generate grounded, accurate outputs. It is really hard to do this with other systems. That is because developers have to deal with the complexity of bolting on a standalone vector database to a separate OLTP database and search engine, and then keep all those separate systems in sync.”
Check out our AI Learning Hub to learn more about building AI-powered apps with MongoDB.
Providing further customization and an industry edge
With Gradient’s platform, businesses can further build, customize, and deploy AI as they see fit — in addition to the benefits that stem from the use of Gradient’s Accelerator Blocks.
Gradient partners with key vendors and communities in the AI ecosystem to provide developers and businesses with best-of-breed technologies. This includes Llama-2 and Mistral LLMs — with additional options coming — alongside the BGE embedding model and the Langchain, LlamaIndex, and Haystack frameworks. MongoDB Atlas is included as a core part of the stack available in the Gradient platform.
While any business can leverage its platform, Gradient’s domain-specific models in financial services and healthcare provide a unique advantage for businesses within those industries. For example in financial services, typical use cases for Gradient’s models include risk management, KYC, anti-money laundering (AML), and robo-advisers, along with forecasting and analysis. In healthcare, Gradient use cases include pre-screening and post-visit summaries, clinical research, billing, and benefits, along with claims auditing.
What is common to both finance and healthcare is that these two industries are subject to comprehensive regulations where user privacy is key. By building on Gradient and its state-of-the-art open-source large language models (LLMs) and embedding models, enterprises maintain full ownership of their data and AI systems. Developers can train, tune, and deploy their models in private environments running on Gradient’s AI cloud, which the company claims delivers up to 7x higher performance than base foundation models at 10x lower cost than the hyperscale cloud providers.
To keep up with the latest announcements from Gradient, follow the company on Twitter/X or LinkedIn. You can learn more about MongoDB Atlas Vector Search from our 10-minute learning byte.
Head over to our quick-start guide to get started with Atlas Vector Search today.