Over the past two decades, performance of storage hardware increased by two orders of magnitude. First, with the introduction of solid state drives (SSD), then with the transition from SATA to PCIe, and finally with the innovation in non-volatile memory technology and the manufacturing process [1,7]. More recently, in April 2019, Intel released the first commercial Storage Class Memory (SCM). Its Optane DC Persistent Memory, built with 3D XPoint technology, sits on a memory bus and further reduces I/O latency 2.
While device access used to dominate I/O latency, the cost of navigating the software stack of a storage system is becoming more prominent as devices’ access time shrinks. This is resulting in a flurry of academic research and in changes to commercially used operating systems (OS) and file systems. Despite these efforts, mainstream system software is failing to keep up with rapidly evolving hardware. Studies [4,5,6] have shown that file system and other OS overhead still dominates the cost of I/O in very fast storage devices, such as SCMs.
In response to these challenges, academics proposed a new user-level file system, SplitFS [6], that substantially reduces these overheads. Unfortunately, adopting a user-level file system is not a viable option for many commercial products. Apart from concerns about correctness, stability, and maintenance, adoption of SplitFS would restrict portability, as it only runs on Linux and only on top of the ext4-DAX file system.
Fortunately, there IS something that can be done in software storage engines that care about I/O performance. Within MongoDB’s storage engine, WiredTiger, we were able to essentially remove the brakes that the file system applied to our performance without sacrificing the convenience it provides or losing portability. Our changes rely on using memory-mapped files for I/O and batching expensive file system operations. These changes resulted in up to 63% performance improvements for 19 out of 65 benchmarks on mainstream SSDs.
Streamlining I/O in WiredTiger
Our changes to WiredTiger were inspired by a study from UCSD [4], where the authors demonstrated that by using memory-mapped files for I/O and by pre-allocating some extra space in the file whenever it needed to grow, they could achieve almost the same performance as if the file system was completely absent.
Memory-mapped files
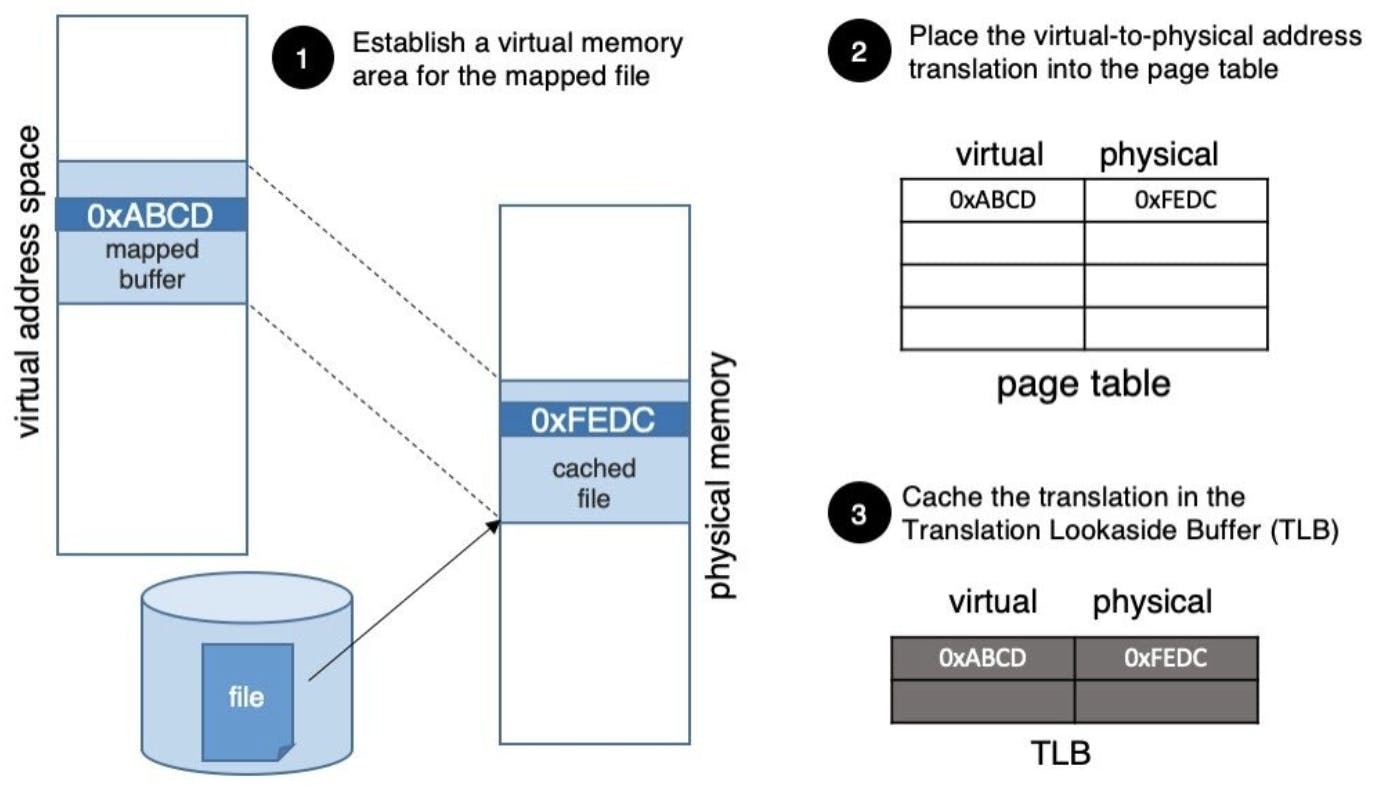
Memory-mapped files work as follows. The application makes an mmap system call, whereby it requests the operating system to “map” a chunk of its virtual address space to a same-sized chunk in the file of its choice (Step 1 in Fig.1). When it accesses memory in that portion of the virtual address space for the first time (e.g., virtual page 0xABCD in Fig. 1), the following events take place:
- Since this is a virtual address that has not been accessed before, the hardware will generate a trap and transfer control to the operating system.
- The operating system will determine that this is a valid virtual address, ask the file system to read the corresponding page-sized part of the file into its buffer cache, and
- Create a page table entry mapping the user virtual page to the physical page in the buffer cache (e.g., physical page 0xFEDC in Fig.1), where that part of the file resides (Step 2 in Fig 1).
- Finally, the virtual-to-physical translation will be inserted into the Translation Lookaside Buffer (TLB -- a hardware cache for these translations), and the application will proceed with the data access.
Subsequent accesses to the same virtual page may or may not require operating system involvement, depending on the following:
- If the physical page containing the file data is still in the buffer cache and the page table entry is in the TLB, operating system involvement is NOT necessary, and the data will be accessed using regular load or store instructions.
- If the page containing the file data is still in the buffer cache, but the TLB entry was evicted, the hardware will transition into kernel mode, walk the page table to find the entry (assuming x86 architecture), install it into the TLB and then let the software access the data using regular load or store instructions.
- If the page containing the file data is not in the buffer cache, the hardware will trap into the OS, which will ask the file system to fetch the page, set up the page table entry, and proceed as in scenario 2.
In contrast, system calls cross the user/kernel boundary every time we need to access a file. Even though memory-mapped I/O also crosses the user/kernel boundary in the second and third scenarios described above, the path it takes through the system stack is more efficient than that taken by system calls. Dispatching and returning from a system call adds CPU overhead that memory-mapped I/O does not have [8]. Furthermore, if the data is copied from the memory mapped file area to another application buffer, it would typically use a highly optimized AVX-based implementation of memcpy. When the data is copied from the kernel space into the user space via a system call, the kernel has to use a less efficient implementation, because the kernel does not use AVX registers [8].
Pre-allocating file space
Memory-mapped files allow us to substantially reduce the involvement of the OS and the file system when accessing a fixed-sized file. If the file grows, however, we do need to involve the file system. The file system will update the file metadata to indicate its new size and ensure that these updates survive crashes.
Ensuring crash consistency is especially expensive, because each journal record must be persisted to storage to make sure it is not lost in the event of a crash. If we grow a file piecemeal, we incur that overhead quite often. That is why the authors of SplitFS [6] and the authors of the UCSD study [4] both pre-allocate a large chunk of the file when an application extends it. In essence, this strategy batches file system operations to reduce their overhead.
Our Implementation
The team applied these ideas to WiredTiger in two phases. First, we implemented the design where the size of the mapped file area never changes. Then, after making sure that this simple design works and yields performance improvements, we added the feature of remapping files as they grow or shrink. That feature required efficient inter-thread synchronization and was the trickiest part of the whole design -- we highlight it later in this section.
Our changes have been in testing in the develop branch of WiredTiger as of January 2020. As of the time of the writing, these changes are only for POSIX systems; a Windows port is planned for the future.
Assuming a fixed-size mapped file area
Implementing this part required few code changes. WiredTiger provides wrappers for all file-related operations, so we only needed to modify those wrappers. Upon opening the file, we issue the mmap system call to also map it into the virtual address space. Subsequent calls to wrappers that read or write the file will copy the desired part of the file from the mapped area into the supplied buffer.
WiredTiger allows three ways to grow or shrink the size of the file. The file can grow explicitly via a fallocate system call (or its equivalent), it can grow implicitly if the engine writes to the file beyond its boundary, or the file can shrink via the truncate system call. In our preliminary design we disallowed explicitly growing or shrinking the file, which did not affect the correctness of the engine. If the engine writes to the file beyond the mapped area, our wrapper functions simply default to using system calls. If the engine then reads the part of the file that had not been mapped, we also resort to using a system call.
While this implementation was decent as an early prototype, it was too limiting for a production system.
Resizing the mapped file area
The trickiest part of this feature is synchronization. Imagine the following scenario involving two threads, one of which is reading the file and another one truncating it. Prior to reading, the first thread would do the checks on the mapped buffer to ensure that the offset from which it reads is within the mapped buffer’s boundaries. Assuming that it is, it would proceed to copy the data from the mapped buffer. However, if the second thread intervenes just before the copy and truncates the file so that its new size is smaller than the offset from which the first thread reads, the first thread’s attempt to copy the data would result in a crash. This is because the mapped buffer is larger than the file after truncation and attempting to copy data from the part of the buffer that extends beyond the end of the file would generate a segmentation fault.
An obvious way to prevent this problem is to acquire a lock every time we need to access the file or change its size. Unfortunately, this would serialize I/O and could severely limit performance. Instead, we use a lock-free synchronization protocol inspired by read-copy-update (RCU) [9]. We will refer to all threads that might change the size of the file as writers. A writer, therefore, is any thread that writes beyond the end of the file, extends it via a fallocate system call, or truncates it. A reader is any thread that reads the file.
Our solution works as follows: A writer first performs the operation that changes the size of the file and then remaps the file into the virtual address space. During this time we want nobody else accessing the mapped buffer, neither readers nor writers. However, it is not necessary to prevent all I/O from occurring at this time; we can simply route I/O to system calls while the writer is manipulating the mapped buffer, since system calls are properly synchronized in the kernel with other file operations.
To achieve these goals without locking, we rely on two variables:
- mmap_resizing: when a writer wants to indicate to others that it is about to exclusively manipulate the mapped buffer, it atomically sets this flag.
- mmap_use_count: a reader increments this counter prior to using the mapped buffer, and decrements it when it is done. So this counter tells us if anyone is currently using the buffer. The writer waits until this counter goes to zero before proceeding.
- Before resizing the file and the mapped buffer, writers execute the function prepare_remap_resize_file; its pseudocode is shown below. Essentially, the writer efficiently waits until no one else is resizing the buffer, then sets the resizing flag to claim exclusive rights to the operation. Then, it waits until all the readers are done using the buffer.
After executing prepare_remap_resize_file, the writer performs the file-resizing operation, unmaps the buffer, remaps it with the new size and resets the resizing flag.
The synchronization performed by the readers is shown in the pseudocode of the function read_mmap:
As a side note, threads writing the file must perform both the reader synchronization, as in read_mmap, to see if they can use the memory-mapped buffer for I/O, and the writer synchronization in the case they are writing past the end of the file (hence extending its size). Please refer to the WiredTiger develop branch for the complete source code.
Batching file system operations
As we mentioned earlier, a crucial finding of the UCSD study that inspired our design [4], was the need to batch expensive file system operations by pre-allocating file space in large chunks. Our experiments with WiredTiger showed that it already uses this strategy to some extent. We ran experiments comparing two configurations: (1) In the default configuration WiredTiger uses the fallocate system call to grow files. (2) In the restricted configuration WiredTiger is not allowed to use fallocate and thus resorts to implicitly growing files by writing past their end. We measured the number of file system invocations in both cases and found that it was at least an order of magnitude smaller in the default configuration than in the restricted. This tells us that WiredTiger already batches file system operations. Investigating whether batching can be optimized for further performance gains is planned for the future.
Performance
To measure the impact of our changes, we compared the performance of the mmap branch and the develop branch on the WiredTiger benchmark suite WTPERF. WTPERF is a configurable benchmarking tool that can emulate various data layouts, schemas, and access patterns while supporting all kinds of database configurations. Out of 65 workloads, the mmap branch improved performance for 19. Performance of the remaining workloads either remained unchanged or showed insignificant changes (within two standard deviations of the average). Variance in performance of two workloads (those that update a log-structured merge tree) increased by a few percent, but apart from these, we did not observe any downsides to using mmap.
The figures below show the performance improvement, in percent, of the mmap branch relative to develop for the 19 benchmarks where mmap made a difference. The experiments were run on a system with an Intel Xeon processor E5-2620 v4 (eight cores), 64GB of RAM and an Intel Pro 6000p series 512GB SSD drive. We used default settings for all the benchmarks and ran each at least three times to ensure the results are statistically significant.
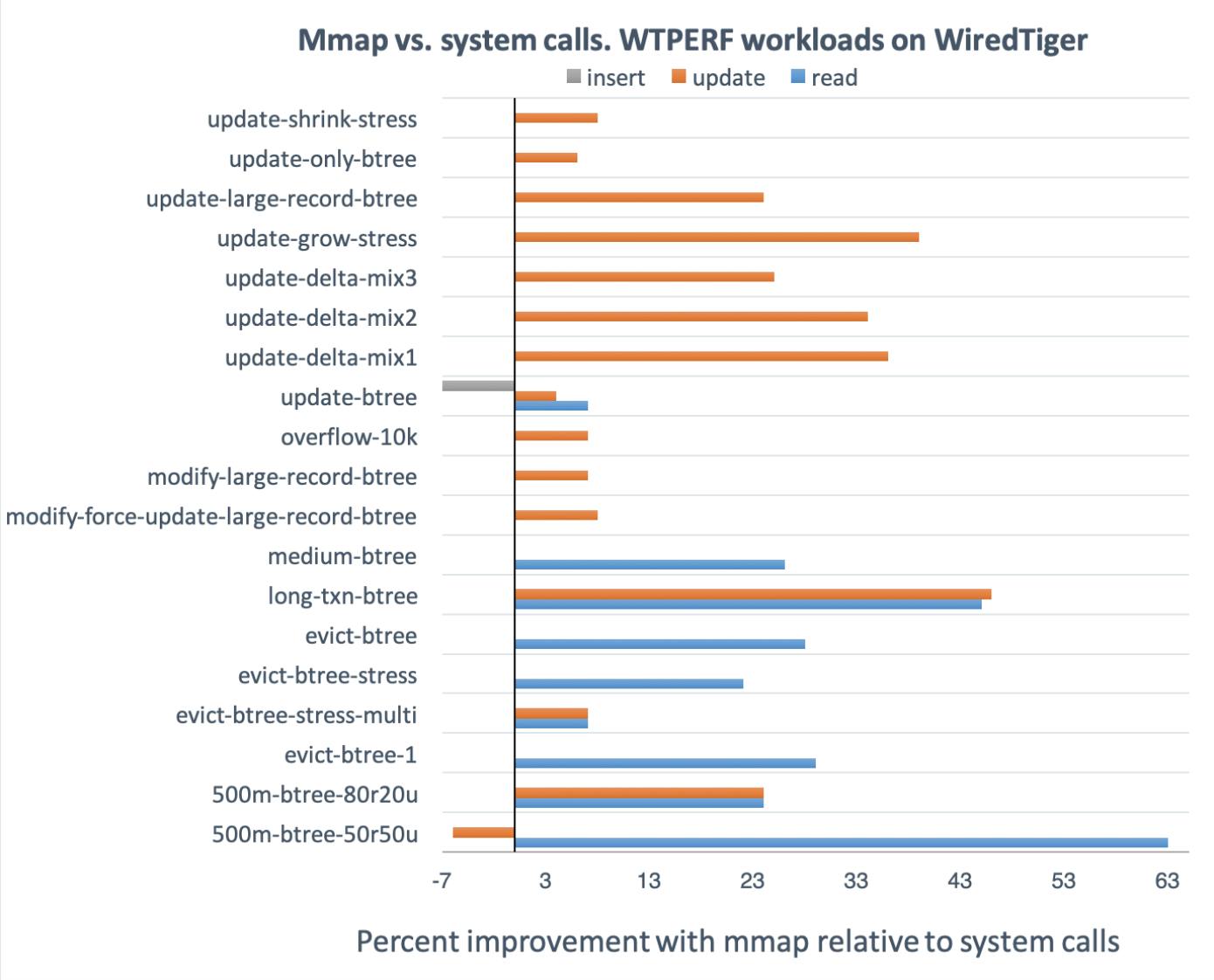
Overall, there are substantial performance improvements for these workloads, but there are a couple interesting exceptions. For 500m-btree-50r50u and for update-btree some operations (e.g., updates or inserts) are a bit slower with mmap, but others (typically reads) are substantially faster. It appears that some operations benefit from mmap at the expense of others; we are still investigating why this is happening.
One of the variables that explains improved performance with mmap is increased rate of I/O. For example, for the 500m-btree-50r50u workload (this workload simulates a typical MongoDB load) the read I/O rate is about 30% higher with mmap than with system calls. This statistic does not explain everything: after all, read throughput for this workload is 63% better with mmap than with system calls. Most likely, the rest of the difference is due to more efficient code paths of memory-mapped I/O (as opposed to going through system calls), as observed in earlier work [8]. Indeed, we typically observe a higher CPU utilization when using mmap.
Conclusion
Throughput and latency of storage devices improve at a higher rate than CPU speed thanks to radical innovations in storage technology and the placement of devices in the system. Faster storage devices reveal inefficiencies in the software stack. In our work we focussed on overhead related to system calls and file system access and showed how it can be navigated by employing memory-mapped I/O. Our changes in the WiredTiger storage engine yielded up to 63% improvement in read throughput. For more information on our implementation, we encourage you to take a look at the files os_fs.c and os_fallocate.c in the os_posix directory of the WiredTiger develop branch.
References
[1] List of Intel SSDs. https://en.wikipedia.org/wiki/List_of_Intel_SSDs
[2] Optane DC Persistent Memory. https://www.intel.com/content/www/us/en/products/details/memory-storage.html
[3] Linux® Storage System Analysis for e.MMC with Command Queuing
[4] Jian Xu, Juno Kim, Amirsaman Memaripour, and Steven Swanson. 2019. Finding and Fixing Performance Pathologies in Persistent Memory Software Stacks. In 2019 Architectural Support for Program- ming Languages and Operating Systems (ASPLOS ’19). https://cseweb.ucsd.edu/~juk146/papers/ASPLOS2019-APP.pdf
[5] Jian Xu and Steven Swanson, NOVA: A Log-structured File System for Hybrid Volatile/Non-volatile Main Memories, 14th USENIX Conference on File and Storage Technologies (FAST’16). https://www.usenix.org/system/files/conference/fast16/fast16-papers-xu.pdf
[6] Rohan Kadekodi, Se Kwon Lee, Sanidhya Kashyap, Taesoo Kim, Aasheesh Kolli, and Vijay Chidambaram. 2019. SplitFS: reducing software overhead in file systems for persistent memory. In Proceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP ’19). https://www.cs.utexas.edu/~vijay/papers/sosp19-splitfs.pdf
[7] SDD vs HDD. https://www.enterprisestorageforum.com/storage-hardware/ssd-vs-hdd.html
[8] Why mmap is faster than system calls. https://medium.com/@sasha_f/why-mmap-is-faster-than-system-calls-24718e75ab37
[9] Paul McKinney. What is RCU, fundamentally? https://lwn.net/Articles/262464/