The MongoDB .NET/C# driver introduces idiomatic APIs for constructing queries and aggregations: LINQ and Builders. These APIs eliminate the need to write native MongoDB Query Language (MQL), but they also introduce some overhead when it comes to troubleshooting and optimizing the underlying MQL. Because the generated MQL cannot be inspected at compile time, troubleshooting queries involves outputting MQL at runtime and/or inspecting runtime exceptions.
Given that MQL generation from a C# expression is basically transpiling, we knew that theoretically inferring the general form of MQL in compile time was solvable by static analysis. This realization, and the fact that the .NET ecosystem has an amazing framework for writing static analyzers (Roslyn), made me excited to try out this idea during MongoDB Skunkworks week.
In this article, I will share my experience of forming a plan for this project, crafting a quick proof-of-concept during Skunkworks week, and eventually releasing the first public version.
Skunkworks at MongoDB
One of my favorite perks of working at MongoDB is that we get a whole week, twice a year, to focus on our own projects. This week is a great opportunity to meet and collaborate with other folks in the company, try out any ideas we want, or learn something new.
I started my Skunkworks week by refreshing my Roslyn skills. While a week sounds like a fair amount of time for rapid prototyping, naturally I still had to settle on just a small subset of all the cool features that came to mind. I was lucky and, by the end of the Skunkworks, I had a MongoDB Analyzer for .NET prototype sufficient to demonstrate the feasibility of this idea.
Roslyn analyzers
A significant part of the .NET ecosystem is the open source .NET Compiler Platform SDK (Roslyn API). This SDK is well integrated into the .NET build pipeline and IDE (e.g., VS, Rider), which allows for the creation of tools for code analysis and generation.
The Roslyn SDK exposes the standard compiler's building blocks. The main ones that will be used in the Analyzer project are:
Abstract syntax tree (AST): Data structure representing the text of the analyzed code.
Symbol table: Data structure that holds information about variables, methods, classes, interfaces, types, and other language elements. Each node in AST can have a corresponding symbol.
Emit API: API that allows you to generate a new IL code dynamically and compile it to a memory assembly, which can be loaded and executed in the same application.
Roslyn SDK provides a convenient API to develop and package a code analyzer, which can be easily integrated into a .NET project and executed as part of the build pipeline. Or, it can expose an interactive UI in an IDE, thereby enriching developers' experience and enforcing project-specific rules.
Design approach
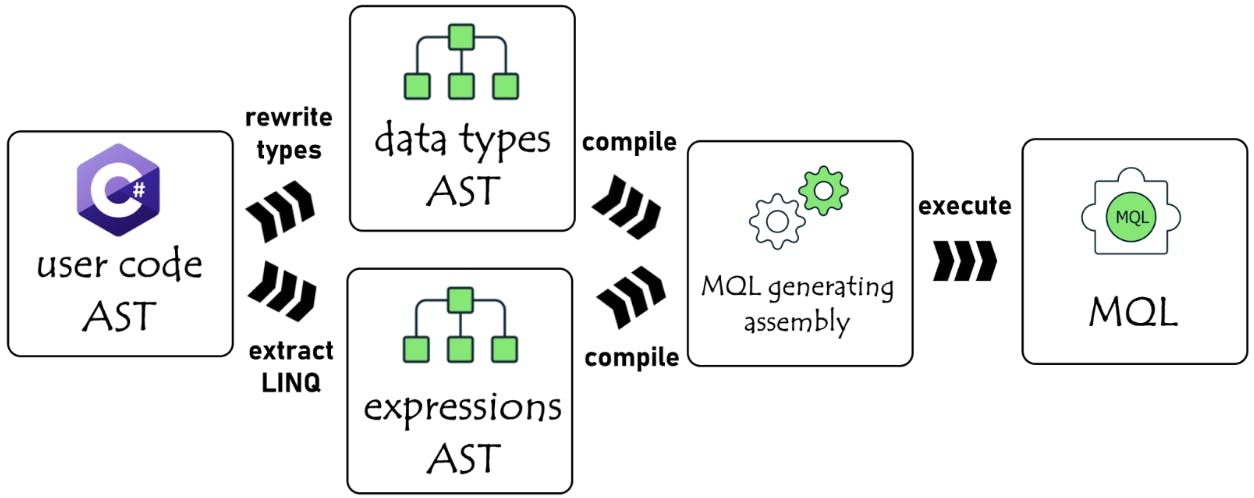
The .NET.C# driver provides an API to render any LINQ or Builder expression to MQL. The next logical step is to identify the needed expressions and use the driver to extract the matching MQLs. Extracting the Builders or LINQ expression syntax nodes from the syntax tree provided by Roslyn was fairly straightforward.
The next step, therefore, is to create a new syntax tree and add these expression syntax nodes combined with MQL generating syntax. Then, this new syntax tree is compiled into executable code, which is dynamically invoked to generate the MQL.
To optimize this process, the Analyzer maintains a template syntax tree containing a sample MQL generation code from an expression:
From this template, a new single syntax tree is produced for each Analyzer run, by dynamically adding the RenderMQL_N method for each analyzed expression N, and replacing the expression placeholder with the analyzed expression:
Next, the compilation unit is created from the syntax tree containing all the analyzed expressions and emitted to in-memory assembly (Figure 1). This assembly is loaded into Analyzer AppDomain, from which the MQLGenerator object is instantiated, which provides the actual MQL by invoking RenderMQL_N methods.

This approach imposed four fundamental challenges, discussed below:
Data types resolution: Expressions are strongly typed, while the types are usually custom types that are defined in the user code.
Variables resolution: Expressions usually involve variables, constants, and external methods. The Analyzer cannot resolve those dependencies at compile time.
Driver versions: Different driver versions might render different MQL. The exact driver version referenced by the analyzed code has to be used.
Testing: The Roslyn out-of-the-box testing template lets you test analyzers on C# code provided as a simple string, which imposes significant maintainability challenges for a large number of tests.
Data types resolution
Given a simple LINQ expression that retrieves all the movies produced by Christopher Nolan from the movies collection:
The underlying Movie type, and all types Movie is dependent upon, must be ported into the Analyzer compilation space. All imported types must exactly reproduce the original namespaces hierarchy. Expressions like db.GetCollection
An additional problem with importing the types directly is the unbounded complexity of methods and properties implementations, which in most cases could not be compiled in the Analyzer compilation space. This excess code plays no role in MQL generation and must not be imported into the compilation unit.
We decided that an easier and cleaner solution was to create a unique type name for each referenced type under a single namespace. The Analyzer uses the semantic model to inspect the Movie type defined in the user’s code and creates a new MovieNew syntax node mirroring all Movie properties and fields. This process is repeated for each type referenced by Movie, including enums, arrays, collections (Figure 2).
After creating a MovieNew type as a syntax declaration, the original LINQ expression must be rewritten to reference the new type. Therefore, the original expression is transformed to a new expression: db.GetCollection
Variables resolution
In practice, LINQ and Builders expressions mostly reference variables as opposed to simple constants. For example:
At runtime, the movieName value is resolved, and MQL is generated with a constant value. For example, the above expression can result in the following MQL:
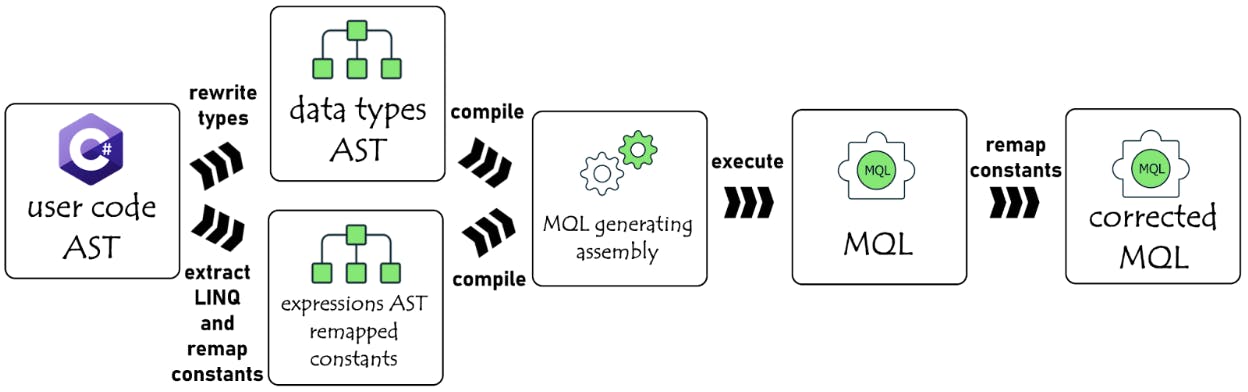
This constant value is not available to Analyzer at compile time; therefore, we have to think of a workaround. Instead of presenting the constant, the Analyzer outputs the variable name:
As you can see, this technique does not produce a valid MQL. But, most importantly, it preserves the MQL shape and contains the referenced variable information. This is done by replacing each external variable and method reference in the original expression by a unique constant, and substituting it back in the resulting MQL (Figure 3).
Driver versions
The naive approach would be to embed a fixed driver dependency into the Analyzer. However, this approach imposes some significant limitations, including:
MQL accuracy degradation: Different versions of the driver can produce slightly different MQL due to bug fixes and/or new features.
Backward compatibility: Expressions written with older driver versions might not be supported or result in different MQL.
Forward compatibility: The Analyzer would not be able to process new expressions supported by newer driver versions. This issue can be resolved by releasing a new Analyzer version for each driver version, but ideally we wanted to avoid such development overhead.
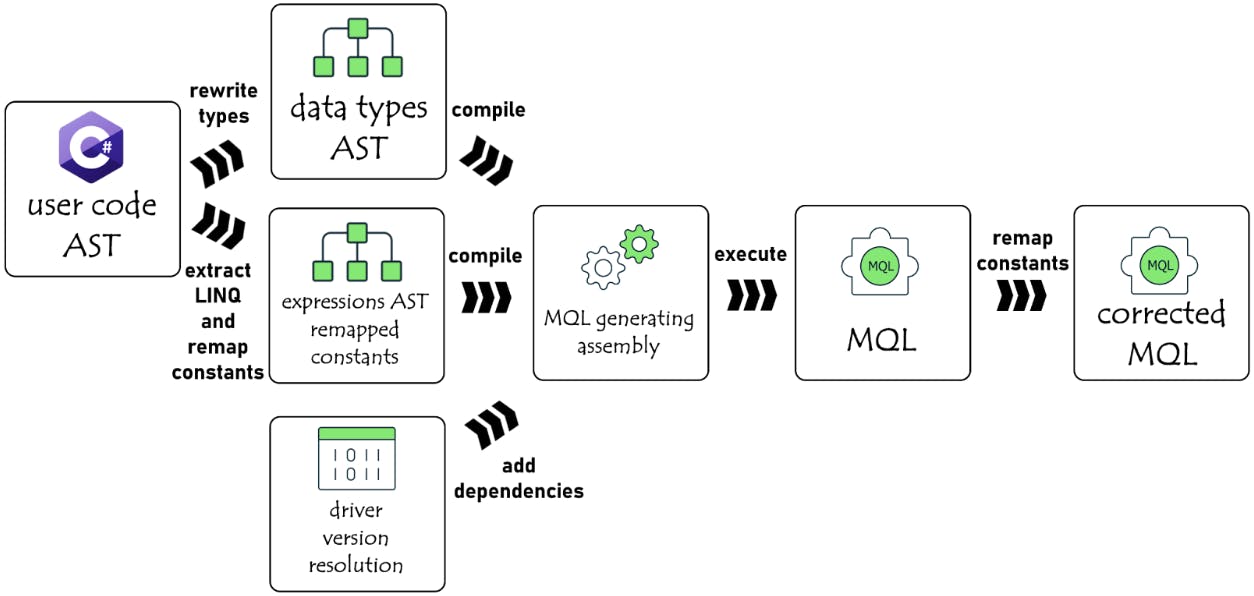
Luckily, instead of embedding a driver package with a fixed version into the Analyzer package, and limiting the Analyzer only to that specific driver version, Analyzer uses the actual driver package that is used by the user’s project and found on the user's machine. In this way, Analyzer is “driver-version agnostic” in some sense.
One of the challenges was to dynamically resolve the correct driver version for each compilation, as C# dynamic compilation tries to resolve the dependencies from the current AppDomain. To solve this, Analyzer overrides the global AppDomain assembly resolution and loads the correct driver assemblies for each resolution request.
An additional nuance was to load the correct .NET framework version. Usually, the Analyzer runs on a different .NET platform than the project's .NET target (e.g., Analyzer can run in VS on .NET Framework 4.7.2, while the analyzed project references the .NET Standard 2.1 driver).
Luckily, all recent driver distributions contain the .NET Standard 2.0 version, which is supported by both .NET Core and .NET Framework platforms. The next step is to identify the physical location of .NET Standard 2.0 driver assemblies with the correct version (Figure 4).
This approach allows the Analyzer to be driver-version agnostic, including supporting future driver versions regardless of the OS platform (e.g., Rider on Linux/Mac, VS on Mac/Windows, .NET build Linux/Mac/Windows).
Testing
Writing tests for such a project requires an unorthodox testing methodology as well. However, the Roslyn SDK provides a testing framework for writing integration tests.
An integration test would receive a C# code snippet to be analyzed supplied as string and then execute the Analyzer on it. The default testing methodology introduces some inconveniences. For example, writing and maintaining hundreds of tests cases, with each test case testing multi-line C# code, involving complex data types as a usual string, without a compiler involves quite the overhead. Therefore, we extended the testing framework by creating a custom test runner in the following way.
All the C# code for the integration tests is written as a standalone C# project, which is compiled in a standard way. Common underlying data types and other code elements are easily reused. An intended test method is marked by a custom attribute denoting the expected result.
An additional test project references the former project and uses the reflection to identify the test cases denoted by special attributes. Then, it executes the Analyzer on the test cases’ C# files and the appropriate driver version and validates the results.
For example, for LINQ expression .Where(u => u.Name.Trim() == "123"), we expect the Analyzer to produce a warning for LINQ2 and valid MQL for LINQ3. The test case is written in the following way:
The Analyzer testing framework parses the C# test cases project and creates a test case for each (DriverVersion, LinqProviderVersion, TestCase) combination (as shown in Figure 5):
This approach allows smooth integration with VS test runner and a seamless development experience.
Besides significantly increasing the maintainability and readability, this approach also introduces a bonus feature. The test code project can be opened as a standalone solution (without the test framework), and the Analyzer output can be visually inspected for each test case as a user would see it.
From initial idea to first release
Because the Skunkworks project proved to be successful, the decision was made to develop a public first release. Generally, developing and releasing a greenfield product in most companies is a lengthy process, which involves resource allocation and planning, productizing, marketing, quality assurance, developing appropriate documentation, and support.
In MongoDB, however, this process was incredibly fast. We formed a remote ad hoc team, across two continents, involving product management, documentation experts, developer relations, marketing specialists, and developers. Despite the fact that we were working together as a team for the first time, the collaboration level was amazing, and the high level of professionalism and motivation allowed everybody to do their part extremely efficiently with almost zero overhead.
As a result, we developed and released a full working product, documentation, marketing materials, and support environment in less than three months.
Learn more about our internal Skunkworks hackathon and some of the projects MongoDB engineers built this year.