As a premier launch partner for the recent GA announcement of the AWS CloudFormation Public Registry, we’re delighted to share that you can now deploy and manage MongoDB Atlas directly from your AWS environment.
Amazon and MongoDB have been pioneers in the cloud computing space, providing mission critical systems for over a decade. Before MongoDB Atlas was launched in June 2016, tens of thousands of customers were running MongoDB themselves on AWS EC2 instances, and many of them were originally spun up using the legacy MongoDB on the AWS Cloud: Quick Start Reference Deployment. This Quick Start was among the top five most popular guides for AWS and allows users to take advantage of AWS CloudFormation's seamless automation and MongoDB’s flexible data model and expressive query API.
In April 2021, we launched a new AWS Quick Start for MongoDB Atlas, which allows AWS customers to quickly and easily launch a basic MongoDB Atlas deployment from the AWS CLI or console. Now, with the availability of the MongoDB Atlas resource types on the CloudFormation Public Registry, customers have more flexibility over their deployment configurations to better meet their cloud workflows. Let’s walk through how it works.
Setup your AWS account for MongoDB Atlas CloudFormation Support
The first step is to sign up for MongoDB Atlas, if you haven’t done so already. Once you create your account, follow these steps:
- Skip the cluster deployment options
- Go to Billing and add a credit card to your account
- Create an organization-level MongoDB Atlas Programmatic API Key with an IP Access List entry. The key needs Organization Project Creator permissions.
Next, open the AWS console in your browser and navigate to CloudFormation. On the left-side navigation, select the Public extensions option. From there you will be able to find the MongoDB Atlas resource types by selecting the “Resource Types” and “Third Party” options.
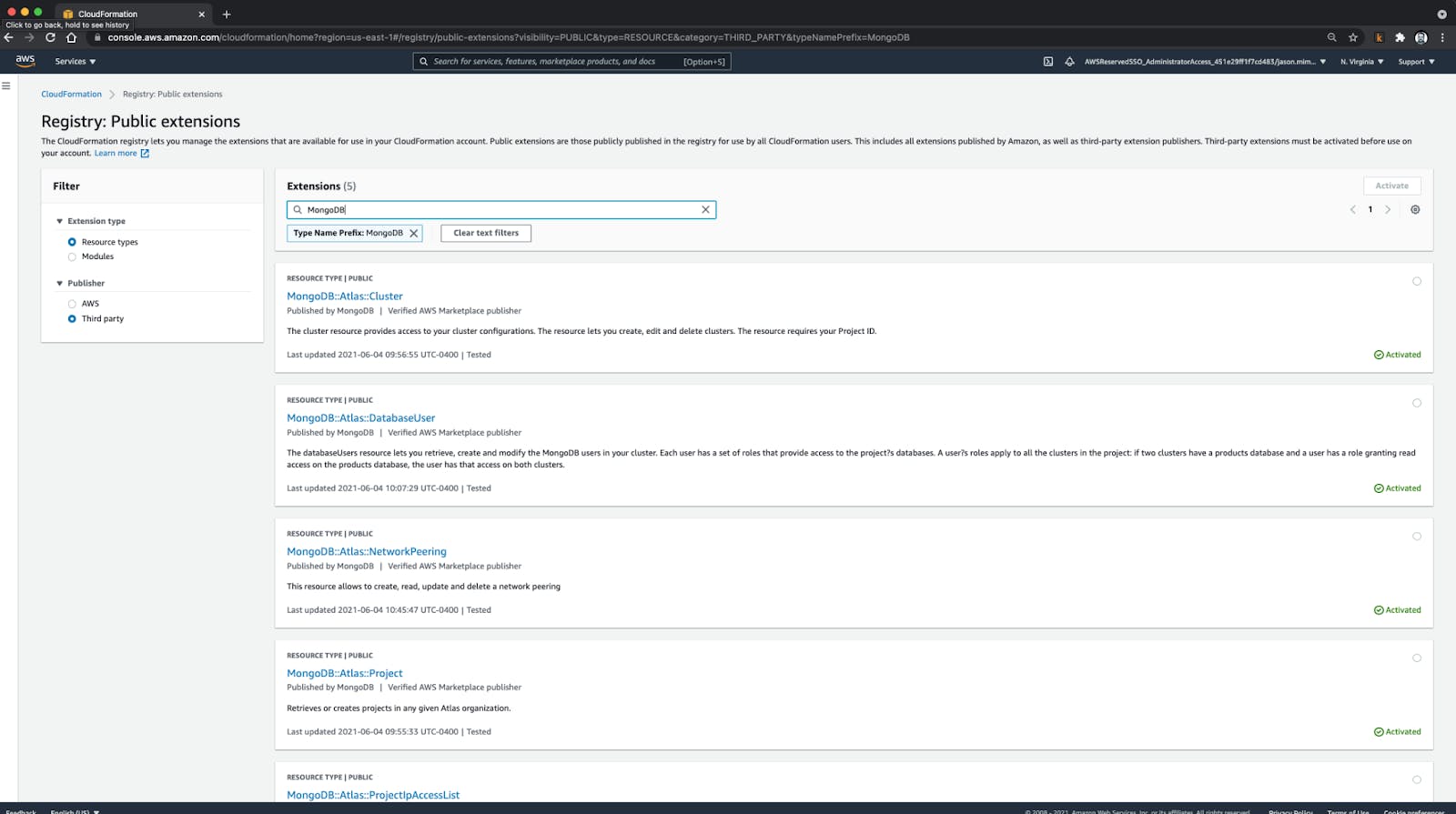
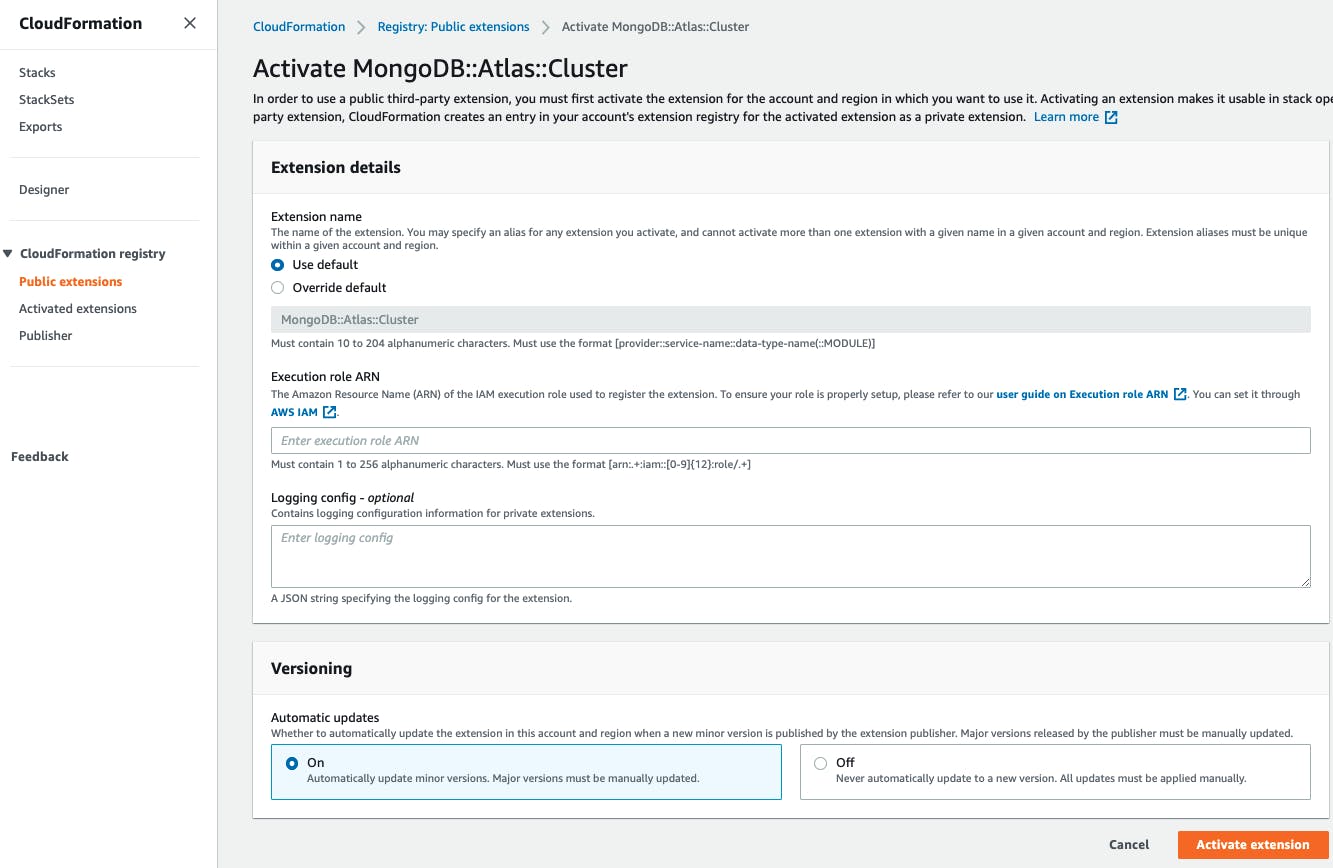
For each of the MongoDB::Atlas resource types, click “Activate”, and then follow on screen prompts to complete the process.
Once you have activated the MongoDB Atlas resources in a region, you’re ready to launch apps with MongoDB Atlas directly from your AWS control plane.
Build apps faster with Cloud Automation
Context switching is a hassle for developers. Launching and deploying application stacks with MongoDB Atlas directly from the AWS console is now more seamless than ever. Whether you use the AWS Quick Start deployment guide as a template or create your own MongoDB Atlas CloudFormation templates, you can leverage the latest in cloud automation to reduce the pain of infrastructure provisioning and management.
Try out the new MongoDB Atlas CloudFormation Resources today, and stay tuned for an in depth look at building apps with AWS Lambda and SAM CLI in an upcoming DevHub article!