Azure Cosmos DB is Microsoft's proprietary globally distributed, multi-model database service. Cosmos DB supports SQL interface as one of the models in addition to the Cosmos MongoDB API. Even customers with the SQL interface use COSMOS for the document model and the convenience of working with a SQL interface.
We have seen customers struggle with scalability issues and costs with Cosmos DB and want to move to MongoDB Atlas.
Migrating an application from Cosmos DB SQL to MongoDB Atlas involves both application refactoring and data migration from Cosmos to MongoDB. The current tool set for migrating data from Cosmos SQL to MongoDB Atlas is fairly limited. While the Azure datamigration tool can be used for a 1 time export, customers frequently need zero downtime for migrations which the datamigration tool cannot satisfy. All writes into the source COSMOS SQL should be discontinued before the data migration can be performed. This puts a lot of pressure on the customer in terms of downtime requirements and planning out the migration.
PeerIslands has built a COSMOS SQL migrator tool that addresses these concerns. The tool provides a way to perform COSMOS SQL migration with near zero downtime.
The architecture of the tool is explained below.
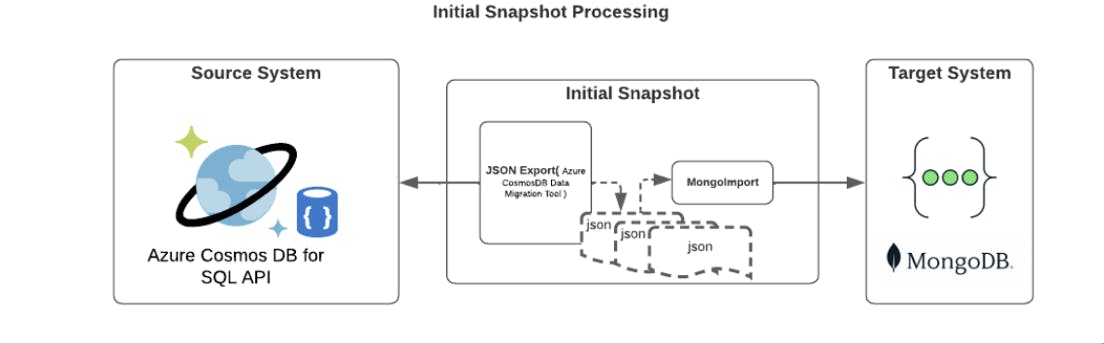
Initial Snapshot
The tool uses the native datamigrationtool to export data as JSON files from Azure Cosmos DB SQL API. The Data Migration tool is an open-source solution that imports/exports data to/from Azure Cosmos DB. The exported data in JSON format is then imported into MongoDB Atlas using the mongoimport.
Change data capture
Using the combination of the above tools we complete the initial snapshot. But what happens to documents that are updated or newly inserted during migration?
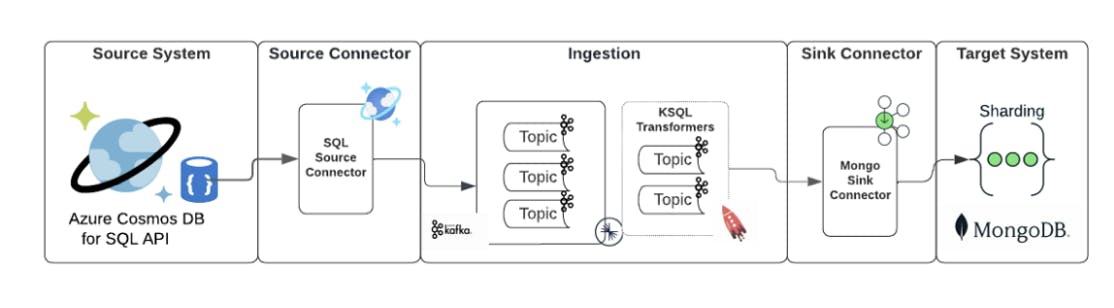
Just prior to the initial snapshot process being started, the migration tool starts the change capture process. The migration tool listens to the ongoing changes in CosmosDB using the Kafka Source Connector provided by Azure and pushes the changes to a Kafka topic. Optionally KSQL can be used to perform any transformation required.
Once the changes are in Kafka, the migration tool uses the Atlas Sink Connector to push the ongoing message to the Atlas Cluster.
Below is the diagram depicting the flow of change stream messages from Cosmos SQL to MongoDB.
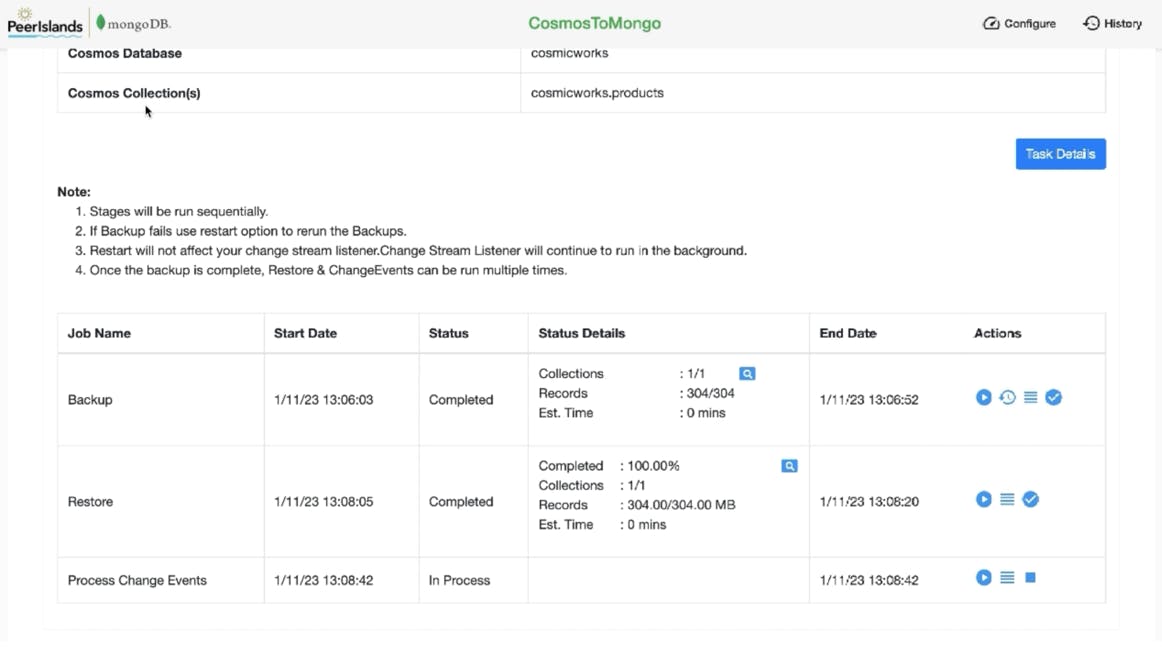
The COSMOS SQL migration tool provides a GUI based point & click interface that brings together the above capabilities for handling the entire migration process. Since the tool is capable of change data capture, the tool provides a lot of flexibility for migrating your data without any downtime.
In addition to data migration, PeerIslands can help with complete application refactoring required for migrating out of COSMOS SQL interface.
Reach out to our partners team if you need to migrate from COSMOS SQL to MongoDB Atlas.