Content Discovery: How to Win the Battle for Attention
April 4, 2022 | Updated: June 6, 2022
Think of the last app you used today. For me, it was searching for the latest episode of Sesame Street on HBOMax for my toddler. For someone else, it was finding a YouTube video on how to bake a cake. Or listening to a song recommended by Spotify. All of these instances, steps we barely put any thought into, are examples of content discovery, the bidirectional process by which users and applications interact, ensuring users’ known and unknown content consumption needs are fulfilled.
As content is being generated at a nearly unfathomable and exponential pace (think 500 hours of videos uploaded to YouTube every single minute), catching and holding consumers’ attention with content is only going to become more difficult. Delivering great content discovery experiences that meet evolving customer expectations will be the only way to keep up.
Content discovery happens in two ways, resembling push and pull forces:
-
Push (recommendation engines): Content is suggested to the user. This can look like personalized landing pages or content recommendations.
-
Pull (search): The customer searches for content, typically via a search bar. The user leads the action, and a new opportunity for suggesting relevant content is created.
Consider how you consume content. Maybe you’re searching for a show you want to watch, or once that show is completed, the app you’re using recommends another similar show you might like. If media providers can master both of these processes – accurate search and intuitive recommendations – you can expect to fuel user engagement and decrease churn.
Simple enough, right? Unfortunately, developing and deploying cutting-edge search and recommendation engines is easier said than done. A few major challenges stand in the way, like integrating data from multiple sources with excruciating extract, transform, load (ETL) pipelines, adding and maintaining a separate search engine solution, reduction in both time-to-value and developer productivity, and more.
Having a unified data platform that can handle analytics at scale and search natively is a massive advantage for effective content discovery. Let’s look at how an advanced data platform like MongoDB Atlas makes the push and pull of content discovery possible.
The push: Real-time, relevant recommendations
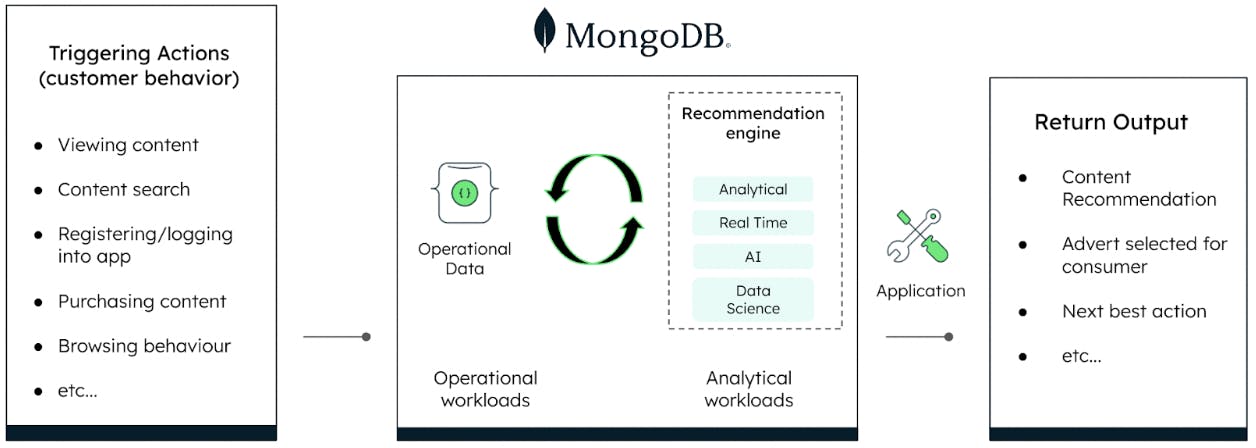
Hitting users with the content they want when they want it (whether they know it's the content they want or not) is the aim of any recommendation engine. It’s particularly important in the media content consumption game, since there are so many competing platforms vying for user attention.
As the volume and variety of user data increases by the second — generated from what they’re watching, what they stopped watching, what devices they’re using to interact with content — recommendations engines need to move beyond simple if-then-else statement based on historical data to advanced machine learning model that learns with data captured in real time, such as a causal inference models that predict what people might want to watch based on what other users with similar profiles and viewing habits are currently watching.
MongoDB integrates natively with machine learning and artificial intelligence engines, using change streams to update the ML models to provide recommendations. The consumer profile is updated and saved in MongoDB, acting as the persistence layer and effectively becoming the single-view consumer data platform, a critical component in the pursuit of real-time analytics informing recommendations. Developers now have a single view of data, and machine learning models use that unsoiled data to make lightning-fast, accurate recommendations to keep users engaged with content.
The pull: Solving the search bar
Virtually every application today has a search function — but it is also challenging to get right. Unlike database queries, where the user knows exactly what they are querying for, search has to give fast and relevant results to open ended, natural language inputs, tolerating typos and partial search terms, and essentially inferring users intent. Ultimately, consumers expect a Google-level search experience, and if they don’t get it, they’ll move to the next content platform.
Building your own search engine, that will meet user expectations even as those expectations evolve, is costly in terms of time and resources spent developing and maintaining the engine. Many more database indexes need to be added to support search queries, and the search workload will start to contend for system resources with the core data persistence and processing demands of the application. To avoid resource contention between these two workloads, the database needs to be carefully sized and closely monitored and scaled, driving up operational overhead and cost.
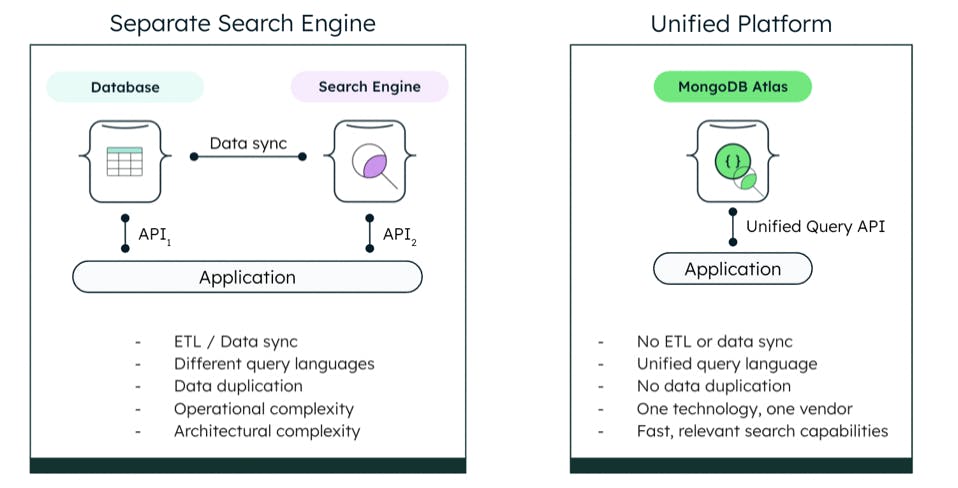
Also developing a database search solution won’t offer you any advantage over the competition, since there are dedicated search engines in the market that can do that heavy lifting for you. This reality has led companies to bolt-on a specialized search engine to their database – not that this is a simple solution either.
Bolting on a search cluster to your database requires adding a new query language to integrate your application with the search engine, which increases the operational and architectural complexity of your current environment. This results in an elongated time for market for what could be a suboptimal search engine.
Atlas Search solves the architecture and operational challenges of adding a separate search engine, since it’s fully integrated with the MongoDB Atlas Data Platform. Powered by the market-leading search engine Apache Lucene, it provides advanced search capabilities, while reducing architectural sprawl. Customers have reported improved development velocities of 30% to 50% after adopting Atlas Search.
Atlas manages the required search infrastructure and automatically keeps the search indexes in sync with data mastered in the MongoDB database. Developers interact with search using the same universal interface that they are accustomed to using when interacting with other data in the platform, which means no new solutions to learn or decrease in developer productivity.
With MongoDB Atlas, you can deliver the right recommendations at the most opportune time, and provide a best-in-class search experience to keep users engaged. No secondary solutions. No months of wasted development. Just a single, simplified process for game-changing content discovery.
Take a deeper look into content discovery powered by MongoDB in our recent guide, Simplifying Content Discovery.