At MongoDB we write open source database drivers in ten programming languages. We also help developers in our community replicate our drivers' behavior in even more (and more exotic) languages. Ideally, all drivers behave alike; or, where they differ, the differences are written down and justified. How can we herd all these cats along the same path?
For years we failed. Each false start at standardization left us more discouraged. But we’ve recently gained momentum on standardizing our drivers. Human-readable, machine-testable specs, coded in YAML, prove which code conforms and which does not. These YAML tests are the Cat-Herd's Crook: a tool to guide us all in the same direction.
Dozens of cats
Our drivers for the ten programming languages we support are, for the most part, independent rewrites. We implement the same API, the same algorithms, the same wire protocol from scratch each time. Once each driver is released, we maintain its separate code as MongoDB evolves and adds features.
All these official drivers don't even encompass the whole effort. Programmers in our community tackle driver development in other languages that are newer or more exotic. Sometimes we come across some driver already fully-formed, published by someone we don't even know. Of course, these third-party drivers reuse code as rarely as we do. They're rewrites of the same ideas, over and over again.
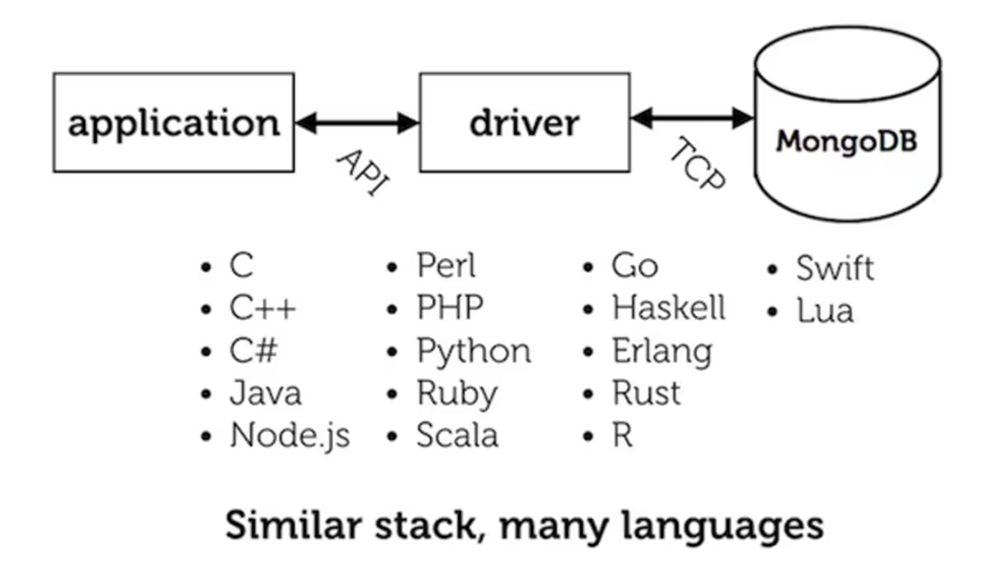
I hear you thinking: "How wasteful! All those drivers should just be thin wrappers of the C Driver." But the effort pays off: any programming language you might reasonably use has a language-native, idiomatic driver for MongoDB.
There is, however, a problem: unintentional differences among the drivers.
Let us set aside the topic of bugs. All drivers have them, but this article is not about bugs. It's about driver authors making reasonable choices that differ. Without intending to, we vary. Sometimes we don't even know what the variations are.
"Local threshold"
A couple years ago, Jesse and Samantha specified a simple way for MongoDB drivers to load-balance queries across servers. It was easy enough to build, but, to our exasperation, not all drivers implemented it the same.
Say you want to load-balance your queries between two MongoDB servers in a replica set, but not if the network latency to one of them is much greater than the other's. We consider the scenario in which one of them is a 10 ms round trip from your application, and the other is 20 ms:
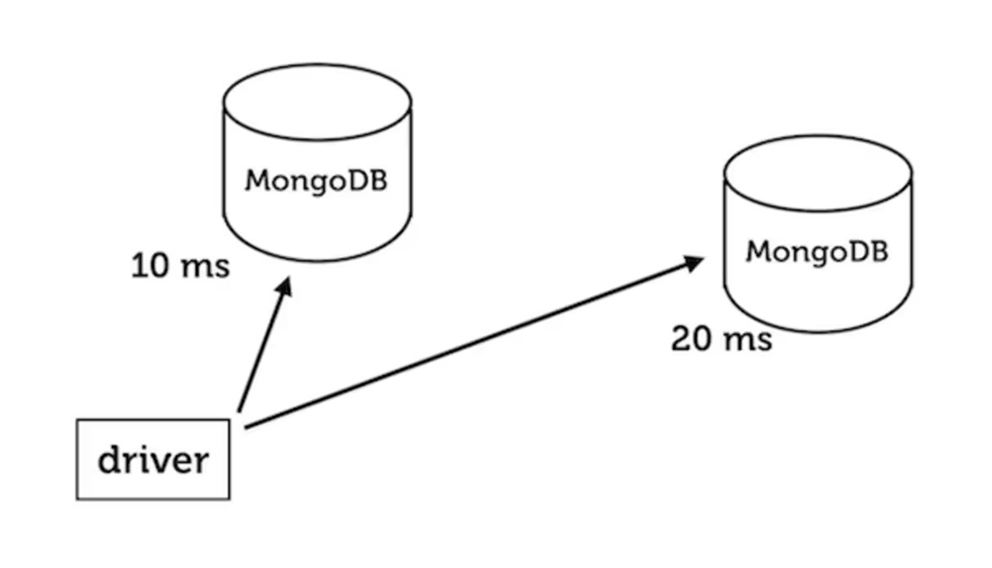
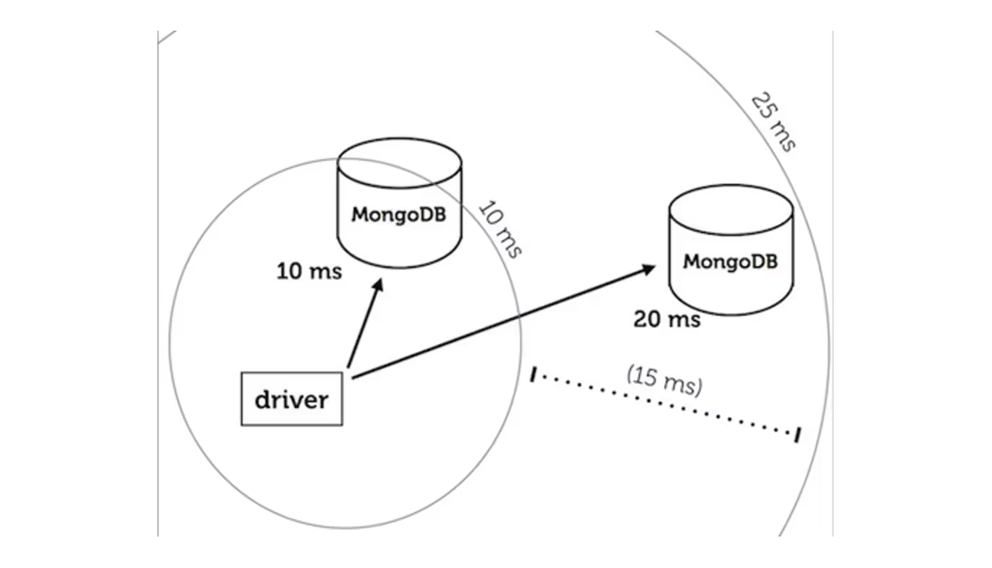
Jesse specified how drivers should do this balancing act: they should respect a "local threshold." The closest server is always eligible for queries, and so are all servers not more than 15 ms farther than it. (This logic applies when you configure the driver for secondary reads or "nearest" reads, see the manual for a specific driver like PyMongo for details.)
Some driver authors understood local threshold as Jesse intended. In the example here, the driver should spread load equally between the 10 ms and the 20 ms server, because the distant server is less than 15 ms farther than the near server:
But several driver authors misinterpreted the spec to mean, "query the nearest server, or any server within a 15 ms round-trip from the application". So in this case, the server 20 ms away is completely excused from load-balancing. The driver only uses the nearest server:
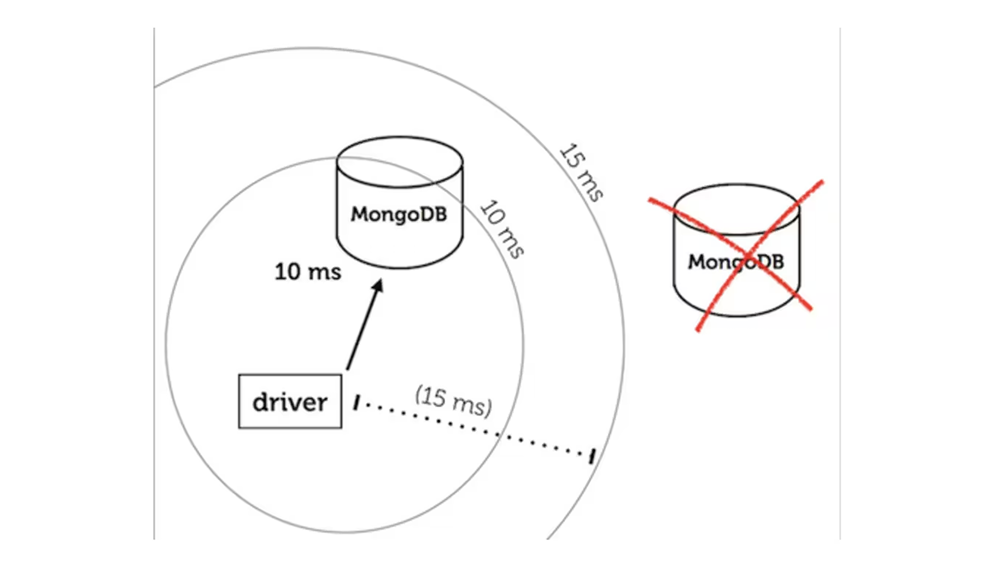
This misinterpretation had two consequences:
Consequence Number One: Some drivers didn't offer the trade-off we'd decided upon, between low-latency and load-balancing. Instead, in situations like this example, all you got was low-latency. But maybe that's not so bad. You might argue that's a reasonable way to implement a driver. Which leads us to the real issue:
Consequence Number Two: You install a driver and you don't know which behavior it implements. Unintentional differences like this cost our customer support team, make our drivers hard to document, and make them hard to learn.
The inconsistency wasn't due to a lack of specification. We wrote it down clearly!
"Determine the 'nearest' member as the one with the quickest response to a ping. Choose a member randomly from those at most 15ms 'farther' than the nearest member."
This is why it's so annoying. Everyone read the first sentence, but not everyone carefully read the second. After all, reading English is boring. As a result, some drivers shipped with this hidden variation that lasted for months or, in one case, more than a year before we knew that they weren't up to spec.
Did we have to let it linger?
Why? Why did these hidden, unintentional differences last for so long? There are two causes:
Too hard to verify
Jesse and Samantha were unable or unwilling to read dozens of implementations of "local threshold." We don't know dozens of programming languages, and we didn't want to make a career of ensuring this one idea was coded consistently. And "local threshold" is just one of hundreds of features that MongoDB drivers must all implement the same.
Non-conformism
We also balked at the social discomfort of forcing our colleagues to conform to our idea. Perhaps at a more starchy, proprietary company, this isn't a problem. The boss says, "Do this!" and everyone steps into line. But at MongoDB there's a collegial, open-source vibe. Although there eventually is a final outcome to any debate, enforcing that is uncomfortable. Samantha and Jesse weren't eager to be the enforcers.
The authors of other specs besides "local threshold" weren't eager to be enforcers, either. But the drivers team never gave up. We tried to unify our drivers by a variety of methods. The first three failed.
False starts
Reference implementation
Since prose wasn't rigorous enough, our next idea was to describe the "local threshold" algorithm in code. We used Python, since it is famously legible:
This is certainly simple. It can even be unit-tested! But despite this reference implementation, unintentional differences persisted in our drivers. Why? Having a reference implementation doesn't prove that every other language implementation matches it. Besides, it is just as hard to read code as English.
A reference implementation does have the advantage that it is less ambiguous, but that is the only advantage. Varying implementations lingered.
Tests in prose
We had a better idea: We could write tests!
"Given servers with round trip time times 10ms and 20ms, the driver reads from both equally."
But again, we could not prove that everyone implemented the tests, or implemented them the same.
A test plan in prose is a substantial step in the right direction. Its main weakness is maintainability: over time, the specification evolves. We find problems with it, or improve it. We can broadcast those changes by updating tests or adding them, but we can't prove that a driver has updated its tests in Java and Python and Haskell to match the new English tests. There isn't enough time in the world for one person to read dozens of test suites in dozens of programming languages and verify all are up to date.
Cucumber
We needed automated, cross-language tests. After evaluating some tools we tried Cucumber.
Cucumber is a "behavior-driven development" tool. It was designed for coders to show to clients and say, "Do we agree that this is what I'm going to implement?" The client can read the test because it resembles English. It looks something like this:
The syntax is funky. And there is still ambiguity here—what does "when I track server latency on all nodes" mean?
But Cucumber does have an advantage: At least the tests are automated! The way you automate it is, you write a pattern-matcher that matches each kind of statement in these tests, like "node 0 has latency 10". Then you implement the statement in terms of driver operations in your programming language. We planned to do that work in C, C++, Python, Javascript, and so on, and then verify all the drivers matched the expected outcome: "the query occurs on either node." If this worked, we would have proven all drivers implemented "local threshold" the same.
Writing these pattern-matchers in a dozen languages sure seemed like hard work. Even worse, some languages like C didn't have a Cucumber framework at all, so we'd have had to write one. The work was daunting—we were certain there must be a better way.
Besides, there was a cultural rebellion against Cucumber. For Ruby or Python programmers, Cucumber looked reasonable, but less so to lower-level coders. Cucumber looks absurd to a C programmer. When engineers think a tool is aesthetically offensive, no amount of debating or threatening them will lead to an enthusiastic implementation.
So we relented. But now we were without a paddle. For more than a year, we kept writing specs, and we made a solid effort to manually verify that everyone implemented them correctly. But we didn't trust that all the drivers were the same, because we couldn't mechanically test them.
But we did find a way out. Our solution was to write tests for our specs in YAML.
Tests in YAML
What's a YAML?
YAML is Yet Another Markup Language—actually, its inventors changed their minds. YAML Ain't Markup Language. It's a data language. The distinction is revealing: unlike HTML, say, which marks up plain text, YAML code is pure data. It borrows syntax from several other programming languages like C, Python, Perl. Therefore, unlike Cucumber, YAML feels like neutral ground for programmers in any language. It doesn't provoke an aesthetic revolt. Also unlike Cucumber, most languages have YAML parsers. For those that do not, we convert our YAML tests into JSON.
Apart from its universality, YAML is appealing for other reasons. Large data structures are more readable in YAML than in JSON. YAML has comments, unlike JSON. And, since YAML is a superset of JSON, we can embed JSONified MongoDB data directly into a YAML test.
YAML is also factorable! For example, here are the descriptions Samantha wrote in YAML for servers with round trip times of 10 and 20 ms. We will use them to write a standard test of "local threshold":
YAML's killer feature is aliasing: you can name an object using the ampersand, like "&server_one" above, then reference it repeatedly:
Think of &server_one as "address-of" and *server_one as "dereference", like pointers in C. This lets us DRY our test specs.
Testing "local threshold" in YAML
With our two servers declared, we can define a test of "local threshold". Both servers should be eligible for a query:
There are about 40 YAML tests in this format, that test different aspects of the drivers' load-balancing behavior. We ship a README with the tests, that describes the data structure and how driver tests should interpret it, and how to validate a driver's output against the expected output.
Here's an edited version of the Python driver's "local threshold" test harness. It uses the driver's real Topology class to represent the set of servers and their round trip times, and the driver's real function for selecting a server. But the test doesn't use the network: the inputs it needs are supplied by YAML data.
We run this harness with our 40 YAML files to test that "local threshold" and related features are all up to spec in the Python driver. Besides these 40 tests, there are other suites, in slightly different structures, that test other specifications of other aspects of the drivers.
With this method there's still some work that has to be done for each driver. All the driver authors write "harnesses" to run each spec's YAML tests. This duplicated work is unavoidable: the drivers are separate code bases in different programming languages, and they have to be tested in different ways. But the harnesses are concise little bits of code, and we are significantly deduplicating: we design tests once, and we maintain one set of tests for all drivers. The initial effort of reimplementing the YAML test harness in each driver gives that driver access to the shared suite, and keeps paying off forever after.
The payoff
On occasion, the spec changes. Jesse or Samantha or another driver engineer publishes an update that improves the spec and its tests. Most of the time, new tests broadcast spec changes very precisely: the drivers update their copies of the YAML files, they fail the new tests, and then they bring their implementations back up to spec.
Sometimes a detail can fall between the cracks. For example, we might specify that drivers should track an extra piece of information about the database servers' state, and add tests that show the expected value of this variable, but forget to update a few drivers' test harnesses to actually assert the driver's value matches the expected value. Still, such lapses are far better contained now than before we started using YAML tests.
We're closing the gaps that allow for misinterpretation, and we're making the duplicated effort as small as possible.
Brave new world
Ever since we began using YAML tests, our specs and our drivers have been improving rapidly.
Better implementations
The usual arguments in favor of Test Driven Development apply to our YAML tests: writing a driver (or adapting one) so it can be tested this way leads toward neatly factored interfaces, cleaved along the same conceptual borders as our specifications themselves.
Accountability
If your driver passes the tests, it is up to spec, otherwise you have to fix your code. It's no longer the spec author's responsibility to review all the drivers to catch mistakes.
Additionally, YAML tests have a way of ending debate. In the past, driver authors might ignore a spec, or remain attached to the different choices that remain in their own favorite code. These alternative ideas are usually excellent, but they are not the spec. Jesse, Samantha, and other spec authors hesitated to enforce their decisions, but a YAML test doesn't care. The layer of indirection that Samantha introduced into the verification process, by publishing YAML tests for our feature, reduced the emotional friction caused when a spec made our colleagues change their favorite code.
Encourages more specs
Writing a spec is time-consuming and often frustrating. When Samantha, Jesse, or any of the other driver engineers at MongoDB writes a spec, we have to learn the problem deeply, anticipate our users' future needs, then try to get dozens of eccentric coders to agree on one way to code a solution.
All this hard work deserves a satisfying outcome, but very often the outcome was discouraging. Some specs were never implemented by all drivers, or implemented inconsistently. "Leading programmers is like herding cats" is a cliché because it's true.
But now, with our YAML testing system in place, we know that our hard work will pay off. The specs we write will be implemented correctly, so we're motivated to write more specs and our standardization process is accelerating. Our specs actually work now.
Cats cooperating
Our success with the new spec process lets us dream of a greater ambition: organizing the open source community to build standard MongoDB drivers. The YAML tests are a pathway for outside contributors to write high-quality drivers that are consistent with ones we publish.
We could imagine the day when outside code is proven as trustworthy as our own. We're not there yet. A lot of the knowledge and discussion about how drivers interact with the MongoDB server is still internal, and it's hard for an outside developer to catch up on the debates and access the institutional knowledge of our engineering team. But we can at least see the way forward now; the spec tests are a powerful accelerant in that direction.