Code can't be optimized; it can only be optimized for a set of conditions. When conditions change, optimizations can become bottlenecks, and when that happens, a thorough audit of assumptions might well hold the key to the solution.
The WiredTiger write-ahead log exemplifies this principle. It’s a critical codepath within a high-performance storage engine, and I have optimized it heavily to avoid I/O and locking. But some of the conditions I had initially targeted became invalid when WiredTiger became a storage engine in MongoDB. When a colleague of mine investigated a case of negative scaling found during testing, he uncovered a serious bottleneck in the write-ahead log… call it a "logjam". That investigation ultimately led us to rethink our assumptions and optimize for new conditions. We validated the new approach with a quick prototype, and then covered all the intricacies and edge cases to produce a fully realized solution.
In part one of this two-part series, I’ll dive deep into the innards of the WiredTiger write-ahead log. I’ll show how it orchestrates many threads writing to a single buffer without locking, and I’ll explain how two conflicts between that design and the new conditions produced the logjam. Part two will focus on how we eliminated the bottleneck. I’ll analyze its root causes, describe the key insight that enabled our solution, and detail the new algorithm and how it reflects our current conditions.
The write-ahead log
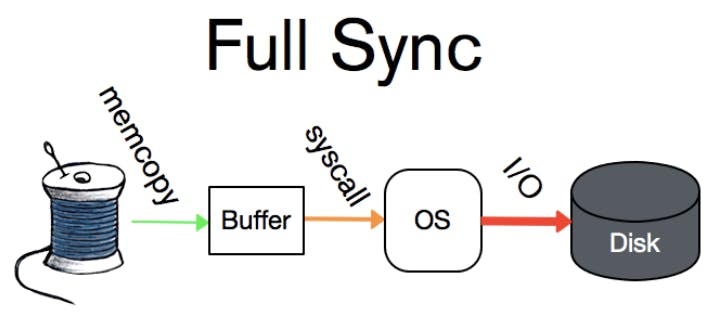
The write-ahead log is the durability feature that allows WiredTiger to survive a process or system crash. (MongoDB calls this the "journal".) Any thread writing data to WiredTiger first appends a record describing the write operation to the write-ahead log; in the event of a crash, any writes that were not persisted to the storage tables can be replayed from this log. The write-ahead log offers three durability modes. The strictest durability, ”full-sync”, guarantees the record is flushed to disk before returning, allowing the data to survive a system crash. The second level of durability, “write-only”, guarantees the record is written to the OS file system before returning to the user, allowing the data to survive a process crash. The least durable is “no-sync”, where the record is recorded in a buffer in memory but there is no guarantee it is immediately written to the file system.
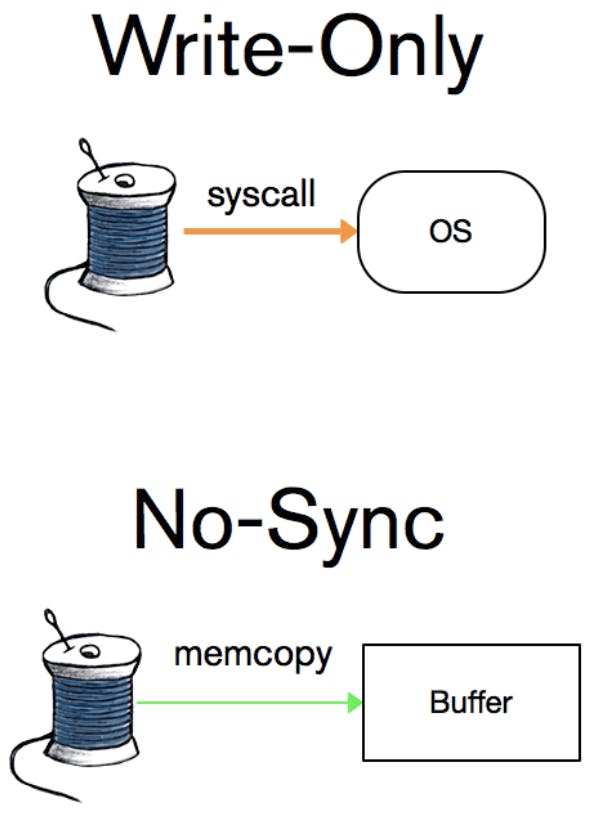
Traditional write-ahead logs use mutexes to coordinate their writes. On single-core architectures this works well, but when more cores are available, it wastes a lot of time making threads wait for a mutex. To achieve better parallelization in our write-ahead log, I had adapted a design from a research paper, "Scalability of write-ahead logging on multicore and multisocket hardware", in the Very Large Databases Journal. Instead of writes being synced or written individually, many threads may copy their records into a single in-memory buffer, which can be written to the file system in a single call. The threads still have to wait for their desired level of durability to be achieved before they return, but the overall throughput of the write-ahead log is greater, because each thread isn’t making its own system call.
Instead of mutexes, atomic operations provide for isolation of writes, allowing all the threads to run without locking. This design could not work with a mutex controlling access to the in-memory buffer — that would just re-introduce the contention to a different layer in the call stack.
Traditional write-ahead logs also can’t offer a no-sync mode, but since WiredTiger already consolidated writes in memory, the ability to do so presented itself. It simply lets threads return without waiting for their writes to be written or synced. In this way, a set of logically related writes could be run much faster: client code could issue all but one write using no-sync and finish with a write-only or full-sync call.
The first hint of trouble
In the summer of 2015, Bruce Lucas, a Senior Technical Service Engineer at MongoDB, was helping make WiredTiger the default storage engine in MongoDB version 3.2. Bruce needs to have a high degree of expertise with the innards of MongoDB to support customers, so he was running experiments to study how WiredTiger performed under a wide variety of circumstances. One of those experiments, a workload consisting of many small inserts using a high number of threads per core, uncovered a case of negative scaling.
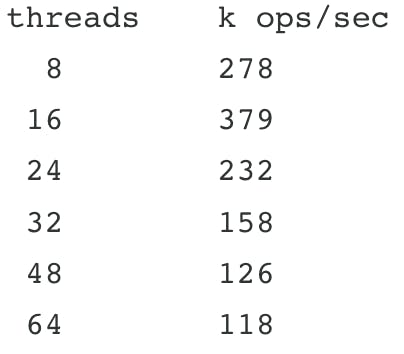
Here are results from an AWS Linux box with 8 cores running the WiredTiger code from MongoDB 3.0.4:
Using Poor Man's Profiler, which periodically invokes gdb to take full stack traces of all threads, Bruce was able to discern the bottleneck: busy-waits in WiredTiger's write-ahead log. As he dug deeper, he uncovered two mismatches between the design of the write-ahead log and the conditions under which it would run as a storage engine for MongoDB.
Condition mismatch #1: durability level
I first designed the write-ahead log before WiredTiger joined MongoDB, and I assumed that most applications using a write-ahead log would use write-only or possibly full-sync mode. This was the typical use case for customers at that time, who were using the WiredTiger library’s key-value store directly.
MongoDB, however, is exactly the kind of system that benefits from issuing a series of related no-sync writes concluding with a full-sync write. WiredTiger structures data as key/value pairs within tables, and those tables are what all of MongoDB’s data structures are built upon — collections, the oplog, indexes, and various internal MongoDB meta-data are all WiredTiger tables. A single write to a MongoDB document results in many write calls into several WiredTiger tables, and from a client perspective, unless all of them persist, none of the rest matter. So even when a call to MongoDB specifies that the journal must be synced to disk before a write returns, MongoDB can make use of the highly efficient no-sync mode for all but the last call. That now makes "no-sync" by far the most common case.
Looking deeper: the WiredTiger log slot
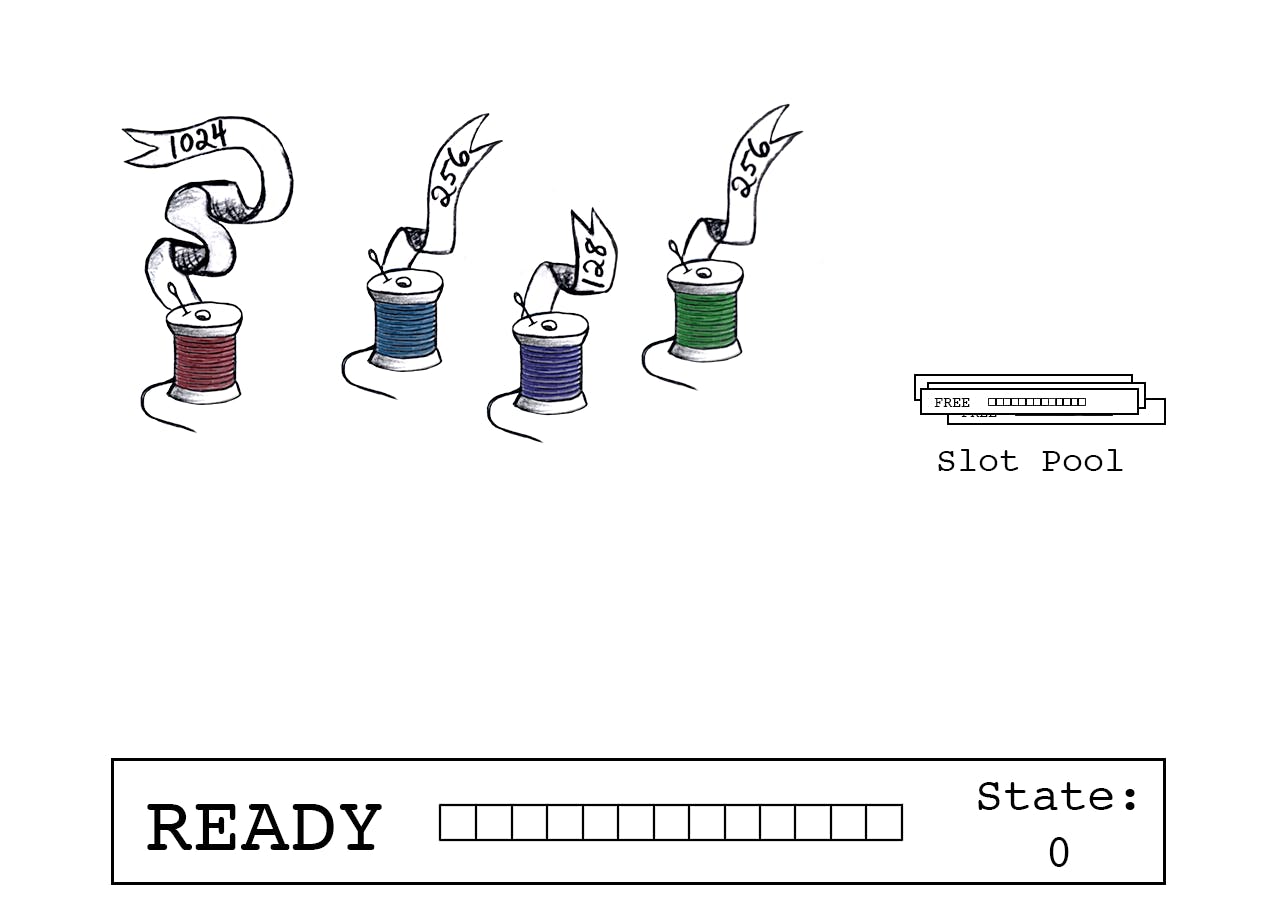
The prevalence of no-sync calls now puts WiredTiger’s write consolidation mechanism front and center. At it’s heart is a data structure called a "slot," using the terminology from the research paper. A slot encapsulates an in-memory buffer, related meta-data, and a special int64_t field called “slot_state” which counts the number of bytes claimed in the buffer. We reserve the lower integers in slot_state for internal state values, the highest of which is called READY. Threads first join a slot that is READY, claiming a spot in its buffer with an atomic operation on slot_state, and when the slot is closed to further joins, they all copy their data and release their claim with another atomic operation on slot_state.
WiredTiger maintains a pool of these slots. To write a record into the log, a thread attempts to join the currently active slot if it is in the READY state. The first step is to determine if the record fits within the remaining buffer space by adding the record size to the slot_state. If the total fits within the buffer, the thread performs an atomic compare-and-swap of slot_state with the new total size. On success, the prior value of slot_state indicates this thread’s offset into the buffer and its new value reflects the correct offset for the next thread to join (or the final size of this buffer).
The thread doesn’t write its payload yet! That write, and the associated bookkeeping, has to wait until the slot is closed to other joining threads — a task that belongs to the leader thread. So for now, it just waits, and watches slot_state for that closed indication.
A joining thread that gets an offset of zero is designated the leader. It doesn’t sit around waiting for the slot to close, that’s its job. But first it prepares a new slot from the pool, to ensure one will be ready for the subsequent round of joins and writes. This is the one task in the entire process that requires a lock, and when it’s over, the leader atomically inverts the sign on slot_state. A negative slot_state indicates that the slot is closed to further joins — the sign the other writers have been waiting for. They already know where their data belongs in the buffer, so they can copy in parallel. Job done, they release the slot by atomically adding their record size to slot_state, which is now the negative of the total number of bytes left to copy into the buffer. When slot_state reaches zero, all copies are complete and that slot is fully prepared for writing. The last thread to release the slot sees this zero and takes charge of writing the buffer to the OS, owing nothing to the rest of the threads, which have already gone on their merry way.
Condition mismatch #2: about as many cores as threads
The original algorithm is elegant and it works beautifully… as long as you have at most a few threads per core. This was another assumption that I made in my original design, based on the expectation that WiredTiger would be embedded in specialized applications, not a general-purpose database.
The availability of cores is important to threads that are waiting to copy records to the buffer, because they have to busy-wait until slot_state changes, consuming CPU cycles. Since I expected that the state would be updated very quickly and that there would be plenty of CPU available for the check, a busy-wait was safe when I wrote it. But MongoDB uses a different thread for every client connection. Some workloads, like those that perform a lot of tiny writes, create many more threads than cores.
The bottleneck
Individually, neither one of the condition mismatches would have been a disaster. But when there are a lot of threads and few cores, and when most of those threads are busy-waiting on a state change, we get a classic case of priority inversion. The thread in charge of managing slot_state and the slot pool ought to be top-priority, but all the threads that have joined a slot and are waiting for a change in slot_state have overwhelmed the CPUs. These threads do call sched_yield, but that doesn’t help much on Linux's scheduler.
Stay tuned for an entirely new approach
We couldn’t just replace yielding with a mutex, because that would kill performance under all loads. We needed to consider new optimizations based on these new conditions. It turned out that Bruce would be the one to crack the nut. While I was optimizing within the framework of the existing code, Bruce went off and experimented. Unencumbered by the concerns of the original design, he tried a completely different approach. He came up with a stand-alone prototype that held the promise of a massive improvement to our "no-sync" case. It was completely bare-bones — it didn’t even use any MongoDB or WiredTiger code — but it was so compelling that I had to try it out for real.
Join us next time for part 2, when we break that logjam!