_Spot_BS_SpringGreen_20(1).png_auto_format_252Ccompress)
Artificial Intelligence’s (AI) growth has led to transformative advancements in the retail industry, including natural language processing, image recognition, and data analysis. These capabilities are pivotal to enhancing the efficiency and accuracy of e-commerce search results.
E-commerce, characterized by its vast product catalogs and diverse customer base, generates enormous amounts of data every day. From user preferences and search histories to product reviews and purchase patterns — and add to that images, video, and audio associated with product campaigns and user search — the data is both a goldmine and a challenge.
Traditional search mechanisms, which rely on exact keyword matches, are inadequate at handling such nuanced and voluminous data. This is where vector search comes into play as the perfect data mining tool.
As a sophisticated search mechanism, it leverages AI-driven algorithms to understand the intrinsic relationships between data points. This enables it to discern complex patterns, similarities, and contexts that conventional keyword-based searches might overlook.
Let’s dig deeper into the differences between traditional keyword matching search and vector search, and answer questions like: What type of queries does vector search improve in the retail search landscape? What are the challenges associated with it? And how can your business tap into the competitive advantage it represents?
Check out our AI Learning Hub to learn more about building AI-powered apps with MongoDB.

Traditional Keyword Matching vs. Vector Search
Traditional search functionalities for e-commerce platforms — keyword matching, typo tolerance, autocomplete, highlighting, facets, and scoring — are often built in-house or implemented on top of typical search engines like Apache Lucene, AtlasSearch, or ElasticSearch, relying heavily on metadata textual descriptions.
While this has served the industry well for years, it often falls short of understanding the nuanced needs of modern consumers. For instance, a customer might be looking for a "blue floral summer dress," but if the product description lacks these terms, it might not appear in the search results, even if it perfectly matches the visual description.
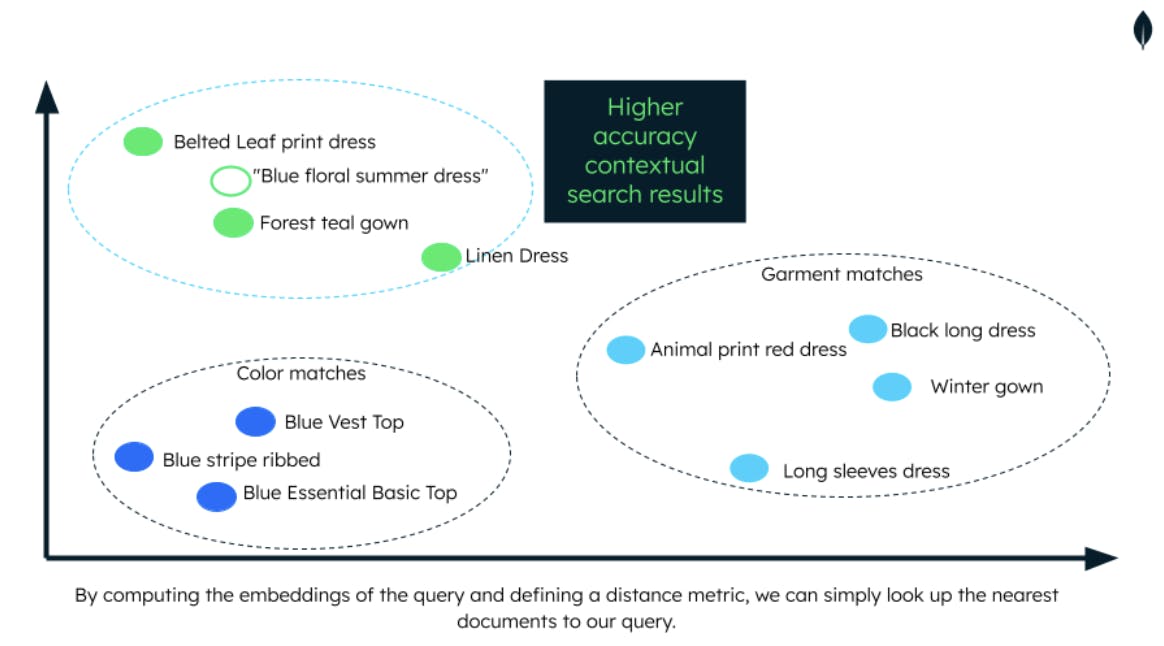
Vector search is a method that finds similar items in a dataset based on their vector representations, and offers a more efficient and accurate way to sift through large datasets. Instead of relying on exact matches, it uses mathematical techniques to measure the similarity between vectors, allowing it to retrieve items that are semantically similar to the user's query, even if the query and the item descriptions don't contain exact keyword matches.

One great thing about Vector search is that by encoding any type of data, i.e. text, images or sound, you can perform queries on top of that, creating a much more comprehensive way of improving the relevance of your search results.
Let’s explore examples of queries that involve context, intent, and similarity.
Visual similarity queries
Query: "Find lipsticks in shades similar to this coral lipstick."
Vector Search Benefit: Vector search can recognize the color tone and undertones of the specified lipstick and suggest similar shades from the same or different brands.
Data type: image or text
Contextual queries
Query: "Affordable running shoes for beginners."
Vector Search Benefit: Vector search can consider both the price range and the context of "beginners," leading to relevant shoe suggestions tailored to the user's experience level and budget.
Data type: text, audio (voice)
Natural language queries
Query: "Show me wireless noise-canceling headphones under $100."
Vector Search Benefit: Capture intent. Vector search can parse the query's intent to filter headphones with specific features (wireless, noise-canceling) and a price constraint, offering products that precisely match the request.
Data type: text, audio (voice)
Complementary product queries
Query: "Match this dress with elegant heels and a clutch."
Vector Search Benefit: Vector search can comprehend the user's request to create a coordinated outfit by suggesting shoes and accessories that complement the selected dress.
Data type: text, audio (voice), image
Challenging landscape, flexible stack
Now that we've explored different queries and their associated data types that could be used in vector embeddings for search, we can see how much more information can be used to deliver more accurate results and fuel growth.
Let’s consider some of the challenges associated with a vector search solution data workflow and how MongoDB Atlas Vector Search helps bridge the gap between challenges and opportunities.
Data overload
The sheer volume of products and user-generated data can be overwhelming, making it challenging to offer relevant search results. By embedding different types of data inputs like images, audio (voice), and text queries for later use with vector search, we can simplify this workload.
Storing your vector encoding in the same shared operational data layer your applications are built on top of, but also generating search indexes based on those vectors, makes it simple to add context to your application search functionalities.
Using Atlas Vector Search combined with MongoDB App Services, you can reduce operational overhead by creating a trigger that could “see” when a new document is created in your collections and automatically make the call to the embedding API of your preference, pushing the document to it and storing the retrieved embedding data in the same document stored in your collection.

By simply creating an index based on the embedded data field, you can leverage the optimized retrieval of the data, reduce the computational load, and accelerate its performance, especially for nearest neighbor search tasks, where the goal is to find items that are most similar to a given query.
Altogether, the combination of MongoDB Vector Search capabilities with App Services and indexing provides a robust and scalable solution to achieve real-time responsiveness. An indexed vector search database can provide rapid query results, making it suitable for applications like recommendation engines or live search interfaces.
Changing consumer behavior
Developing an effective vector search solution involves understanding the nuances of the retail domain. Retailers must consider factors like seasonality, trends, and user behavior to improve the accuracy of search results.
To overcome this challenge, retailers will need to be able to adjust their business model by categorizing their product catalogs and user data according to different criteria, for example:
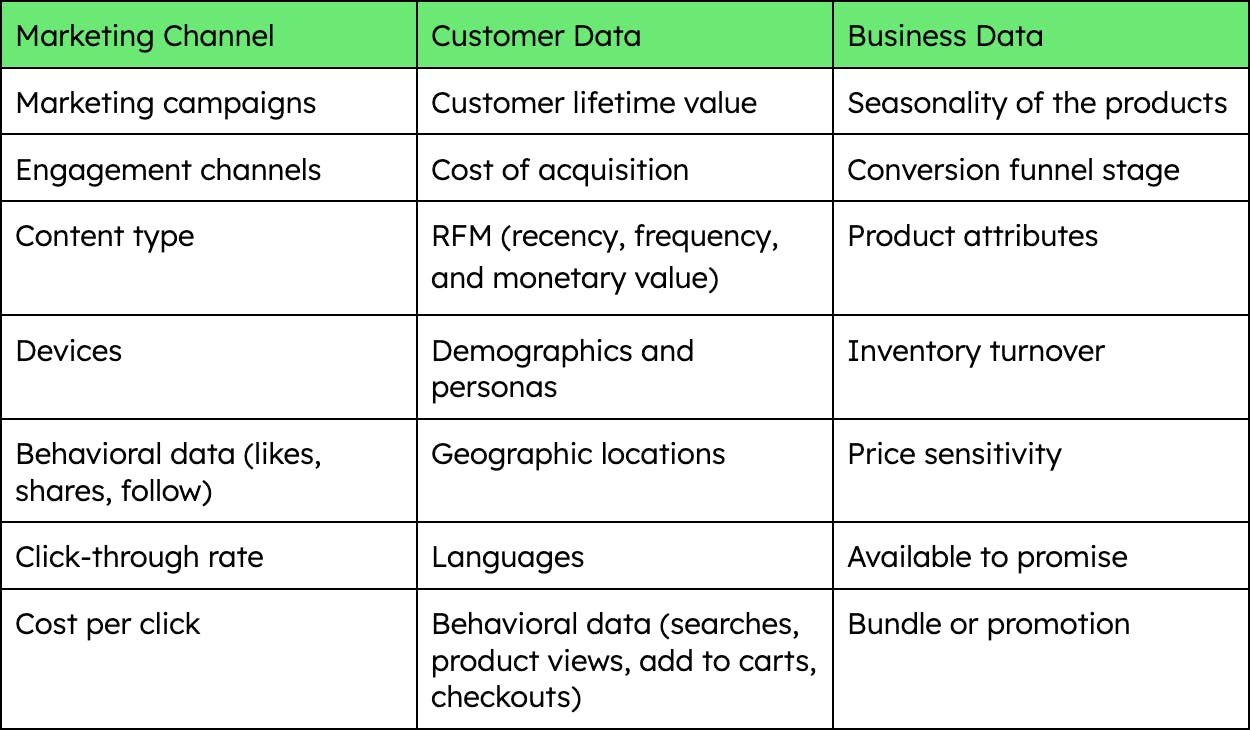
So as you can see all this vast amount of information can be embedded to build more comprehensive criteria for relevance, but first it needs to be properly captured and organized. This is where the value of the flexible document model comes into play.
The document model allows you to define different fields and attributes for each category of data. This can be used to capture the various categorization criteria. Retailers could also utilize embedded subdocuments to associate relevant information with products or customers. For instance, you can embed a subdocument containing marketing campaign data, engagement channels, and geographic location within products to track their performance.
As categorization criteria evolve, dynamic schema evolution allows you to add or modify fields without disrupting existing data. This flexibility easily accommodates changing business needs.
Retailers may also use embedded arrays to record purchase history for customers. Each array element can represent a transaction, including product details and purchase date, facilitating segmentation based on recency and frequency.
By embedding all these different data types, and leveraging the flexible capabilities of the document model, retailers can create a comprehensive and dynamic system that effectively categorizes data according to diverse criteria in a fast and resilient way. This enables personalized search experiences and enhanced customer engagement in the e-commerce space.
Sitting on a goldmine
Every retailer worldwide now realizes that with their customer data, they are sitting on a goldmine. Using the proper enabling technologies would allow them to build better experiences for their customers while infusing their applications with automated, data-driven decision-making.
Retailers offering more intuitive and contextual search results can ensure their customers find what they're looking for by personalizing the relevance of their search results, enhancing satisfaction, and increasing the likelihood of successful transactions.
The future of e-commerce search lies in harnessing the power of technologies like Atlas Vector Search, as it’s not only another vector search database, but also an extended product for the modern database, providing them with an integrated set of data and application services.
For retailers, the message is clear: to offer unparalleled shopping experiences, embracing and integrating vector search functionalities with a performant and reliant platform that simplifies your data organization and storage is not just beneficial, it's essential.
Learn more and discover How to Implement Databricks Workflows and Atlas Vector Search for Enhanced E-commerce Search Accuracy with our developer guide, and check out our GitHub repository explaining the full code for deploying an AI-Enhanced e-commerce search solution
Head over to our quick-start guide to get started with Atlas Vector Search today.